

 PDF
PDF Citation
Citation Print
Print


Introduction
Colorectal cancer (CRC) is one of the most common causes of mortality worldwide [1,2]. CRC treatment is based on multimodal approaches that are composed of surgery, chemotherapy, and radiation therapies [3]. When patients are diagnosed with CRC, treatment strategies are decided by clinical staging, which is based on radiologic examinations. In case of stage IV patients with unresectable metastases, chemotherapy is usually followed, whereas surgery is the preferred initial approach in patients with resectable tumors and postoperative pathologic stage is a single most important determinant to decide further adjuvant therapy. American Joint Committee on Cancer (AJCC) stage is an independent predictor for distinguishing patients based on survival outcomes and has been used as a standard treatment guideline, as it is easy to implement in clinical practice [4]. However, previous studies demonstrated that sometimes there is a difference in survival between patients even who have the same characters such as stage. In CRC, it hasn’t always been clear the prognostic difference between stage II and stage III [5,6]. Molecular, pathologic and radiologic biomarkers have been suggested as alternative parameters for more detailed stratification of survival [7–9]. Nevertheless, there are still difficulties in incorporating these biomarkers in clinical decision-making due to time and cost consuming characteristics.
Machine learning (ML) has been exploited in different areas of clinical research [6,10,11]. Nevertheless, there are several gaps that still need to be investigated. Lack of high-quality datasets for algorithm training and development and proper validation are regarded as major drawbacks in addition to lack of randomized controlled trials comparing newly developed algorithms to current clinical practices [10]. ML techniques have been introduced as useful tools to predict mortality in different diseases, but its clinical usefulness has not been widely studied with proper external validation in patients with CRC [12].
In this study, we developed a survival prediction ML-based model using data from The Surveillance, Epidemiology, and End Results (SEER) Database of the National Cancer Institute [13]. Moreover, we externally validated the model using an independent dataset of: Gangnam Severance Hospital, Yonsei University College of Medicine (Korean) dataset.
Materials and Methods
1. Data collection and patient characteristics
This is a retrospective study. The SEER database of the National Cancer Institute collects cancer incidence and survival data from 18 cancer registries, encompassing approximately 27.8% of the United States population [13]. SEER-Stat software (ver. 8.3.5) was used to identify patients diagnosed between 2004 and 2015. Since tumor characteristics such as tumor size, extension, and metastasis at diagnosis were started to be recorded in SEER registry after 2004, data collected before 2004 wasn’t included. Patients with CRC diagnosed and treated from 2003 and 2012 in Gangnam Severance Hospital, Yonsei University College of Medicine (Seoul, Republic of Korea) were included in the present study and allocated as a Korean dataset. All procedures performed in studies involving human participants were in accordance with the ethical standards of the institutional and/or national research committee and with the 1964 Helsinki declaration and its later amendments or comparable ethical standards.
Patients aged over 18 years old with primary CRC who underwent surgery were identified by defining the primary tumor location to include: C18.0-Cecum, C18.2-Ascending colon, C18.3-Hepatic flexure of colon, C18.4-Transverse colon, C18.5-Splenic flexure of colon, C18.6-Descending colon, C18.7-Sigmoid colon, C18.8-Overlapping lesion of colon, C18.9-Colon, NOS, C19.9-Rectosigmoid junction, C20.9-Rectum, NOS. Patients with unknown age or unknown survival months were excluded.
Patient characteristics were extracted including age at diagnosis in years, sex, tumor location, histology, grade, AJCC stage, tumor size in millimeters, number of examined lymph nodes (LN), number of positive LNs, radiation, chemotherapy, and carcinoembryonic antigen level.
In order not to lose cases with missing data, missing values were imputed using the most frequent for categorical variables and mean for continuous variables when training these algorithms: logistic regression, decision tree and, random forest. Light gradient boosting (LightGBM) didn’t need this as it can handle missing data internally. To shrink the range of continuous data with wide ranges (age and tumor size), age in years was converted into age in century (age in years/100) and tumor size in mm was converted to (tumor size in mm/100). To evaluate survival probability at different time intervals, only cases that had been adequately followed up for this time period were included. Then, survival months were binarized to either cases that survived or cases that hadn’t survived this period of time.
2. Selection of proper machine learning algorithms
Different machine learning algorithms were trained on part of the SEER registry called the “training set” then the trained model is tested on the remaining data called the “testing set” to predict outcome and then the prediction performance is evaluated. Tested algorithms included: Logistic Regression, Decision Tree, Random Forest, and LightGBM [14]. All used models were trained, tuned, and tested using the same methods (S1 Fig.).
3. Internal and external validation of machine learning algorithm
For hyperparameter tuning, Bayesian optimization was chosen which uses the information collected at each iteration for performing the next one. It provides better optimization performance than other methods such as random search and grid search (S2 Fig.) [15].
In terms of internal validation using the SEER dataset, an internal cross-validation approach using 18-fold-cross-validation was chosen for evaluating performance. Since the SEER dataset collects data from 18 cancer registries, dataset is partitioned into 18 splits; a split for each registry. One split is used as the testing set and the others are combined to form the training set in which each algorithm is trained with hyperparameter tuning. This procedure is conducted repeatedly, with each of the split being used once as the test set, to generate 18 models. Then the performance of the 18 corresponding results is averaged to evaluate model performance [16]. In terms of external validation, the algorithm was trained on the SEER registry then validated on the Korean dataset.
To assess model performance, different metrics were calculated including area under the receiver operating characteristic curve (AUROC) and accuracy at each survival period. Also, positive predictive value, sensitivity, and F1 score for each class were calculated. AUROC is a performance index that is independent of any particular threshold and its values range between 0.5 and 1.0, with 0.5 indicating random chance and 1.0 indicates perfect classification [17].
4. Web-based survival prediction
We developed survival prediction web-based application on the result of this work. The web-based survival predictor (http://colorectalcancer.pythonanywhere.com) was deployed using Flask (ver. 1.0). This site is a web-based program freely available online.
5. Statistical analysis
Differences in the distribution of categorical variables were compared using the chi-square test. Non-parametric Mann-Whitney was used to compare the differences between continuous variable [18]. Univariate survival analysis was estimated using the Kaplan-Meier method and log-rank test was used to compare survival of different subgroups. Significant differences between the two AUROC curves were calculated using the method of Hanley and McNeil [17].
Most of the analyses were performed using Python 3.7. Data preprocessing was done using pandas 0.24. Bayesian optimization was performed using scikit-optimize package. Machine learning algorithms were trained and tested using Scikit-learn 0.20 library except LightGBM in which LightGBM 2.2 package was used. Survival analysis was done using lifelines 0.22. Chi-square test and Mann-Whitney tests were calculated using SPSS software ver. 20.0 (IBM Corp., Armonk, NY). A two-sided p < 0.05 was considered statistically significant.
Results
The number of identified patients was 364,316 in the SEER registry and 1,572 in the Korean dataset with median age at diagnosis of 68 and 62 years, respectively. Among 12 variables included in this study, all parameters except histology showed significant difference between the SEER and the Korean datasets (Table 1).
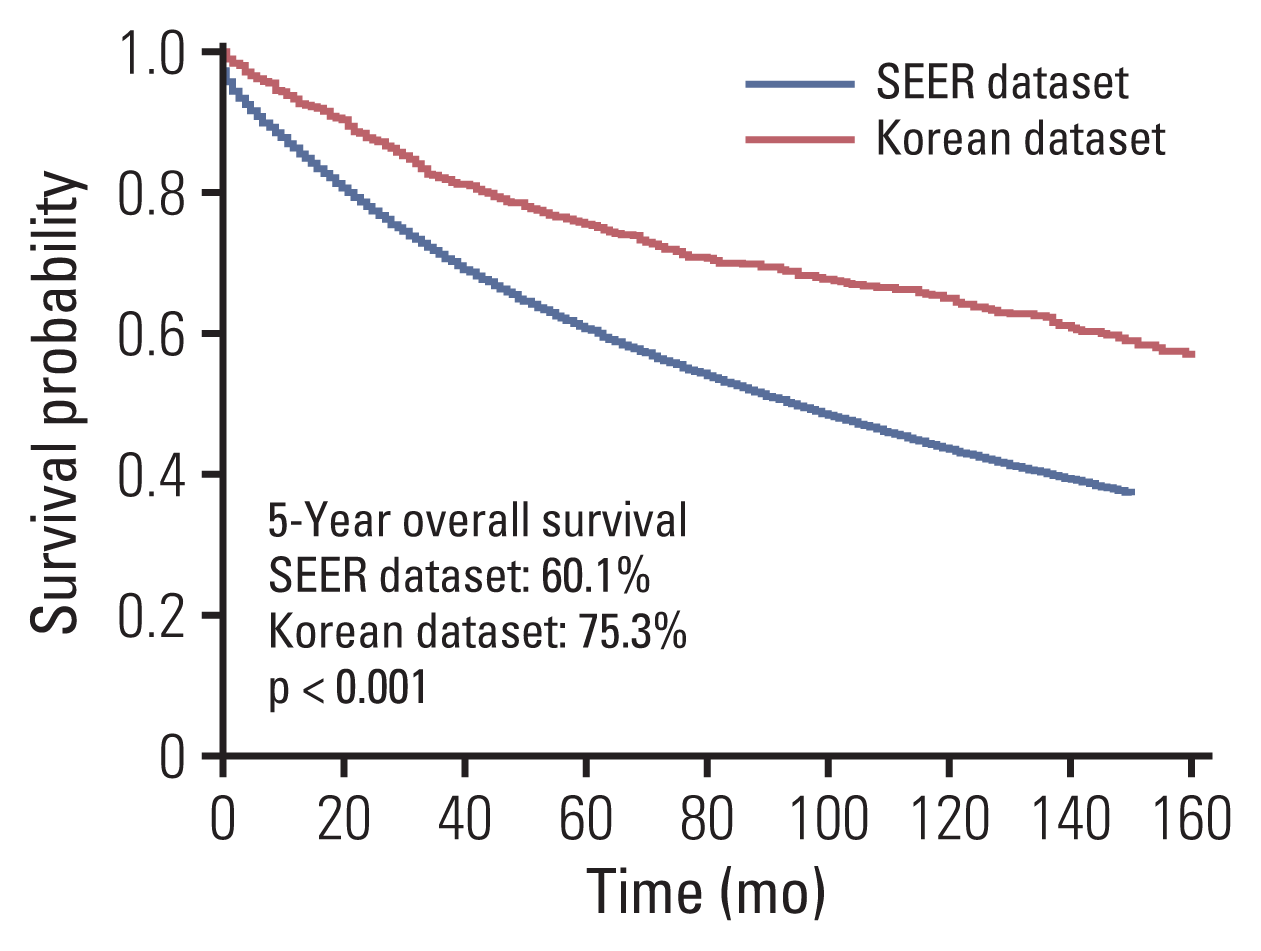
There were about 0%–48% and 0.1%–7.4% of missing values in the SEER and the Korean dataset respectively. Missing rate was different according to the respective variables between the two datasets (S3 Fig.). The SEER showed significantly lower overall survival rate than that of the Korean dataset (Fig. 1, S4 Table). When comparing survival of each stage respectively, the SEER had lower overall survival rate compared to the Korean dataset in all stages (all p < 0.05) (S5 Fig.). Kaplan-Meier analysis showed significant differences between subgroup of each features in both the SEER and Korean datasets (S6 Fig.).
In order to find the highest-performing algorithm, they were trained and tested on SEER dataset to predict survival using 5-fold-cross-validation. The differences in performance between the four algorithms (logistic regression, Decision Tree, Random Forest, and LightGBM) was small in terms of AUROC with a maximum difference of 2.1% (S7 Table). The difference between LightGBM and logistic regression which is commonly used in statistics ranged from 1.3% to 1.5%. A previous study comparing different algorithms revealed LightGBM as the best among other algorithms in terms of accuracy, precision, and AUROC [19]. Taking these into consideration, LightGBM was used as the algorithm of choice for creating the model and for the internal and external validation.
To evaluate the prognostic value of each feature alone, a univariate modeling in the SEER registry was constructed in which each feature alone is used to predict survival at different time periods. When evaluating each feature using internal validation, age at diagnosis had the highest performance when predicting 1-year survival with AUROC of 0.689 (95% confidential interval [CI], 0.673 to 0.705). When predicting all other survival periods, stage had the highest AUROC among all other features with 0.696 (95% CI, 0.683 to 0.709) and 0.667 (95% CI, 0.652 to 0.682) for 5- and 10-year survival, respectively (S8 Table). In external validation using the Korean dataset, stage had the highest prediction performance in all survival periods with AUROC of 0.751 for 1-year survival and 0.702 for 10-year surival (S9 Table).
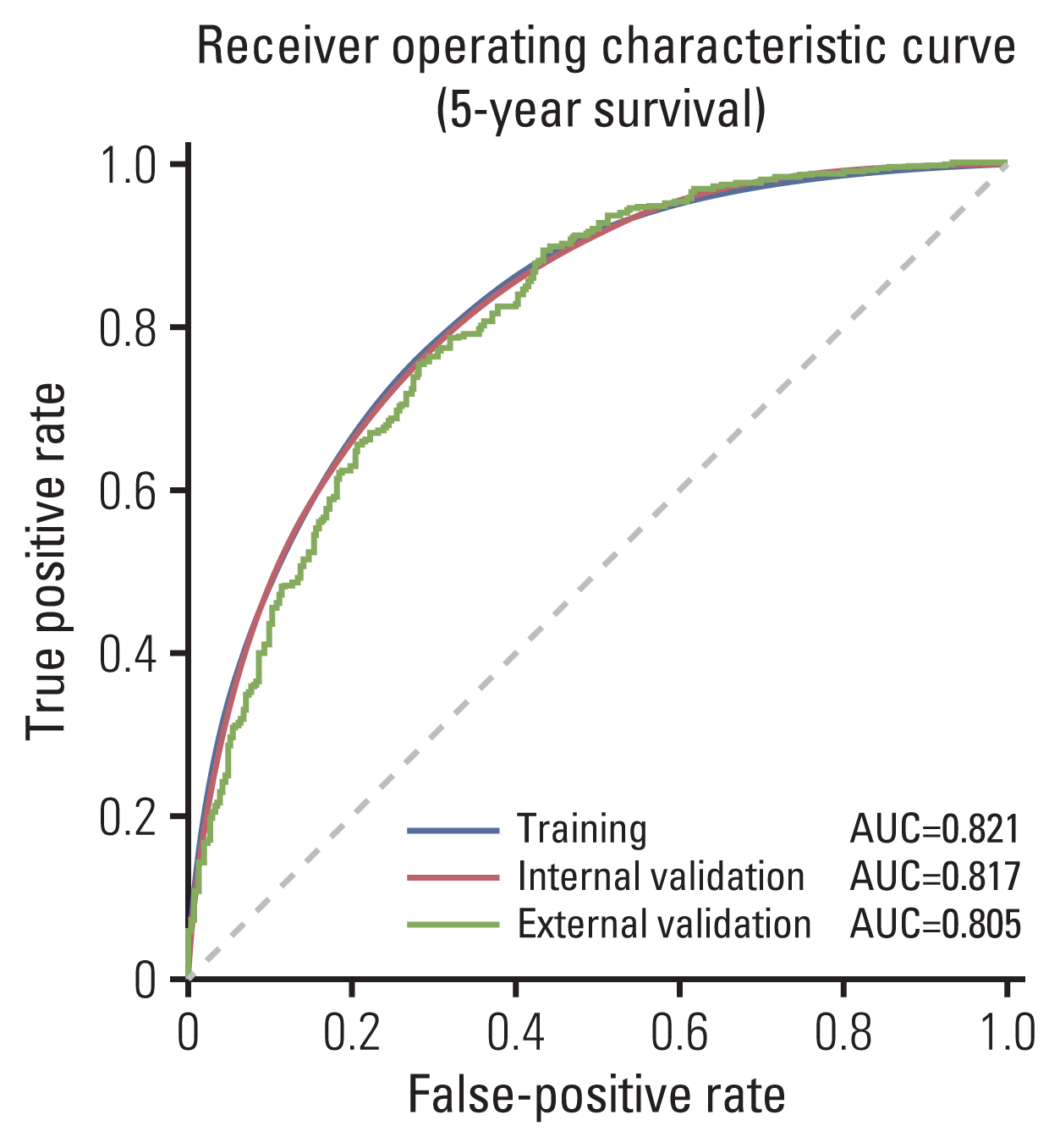
In terms of internal validation, the model achieved average AUROC of 0.817 (95% CI, 0.803 to 0.831) and 0.828 (95% CI, 0.816 to 0.840) for predicting 5- and 10-year survival respectively. The average accuracy of predicting 1-year survival and 5-year survival was 0.763 (95% CI, 0.734 to 0.792) and 0.744 (95% CI, 0.728 to 0.760), respectively. In terms of external validation, the model trained on the SEER registry and validated on the Korean dataset achieved AUROC of 0.825 and 0.804 and accuracy of 0.800 and 0.750 when predicting 1 and 5-year survival respectively (Table 2, Fig. 2). Aside from 2-year survival in which AUROC of external validation was higher than internal validation (0.824 vs. 0.836), the difference in performance between internal and external validation in terms of AUROC ranged from 0.71% to 5.1% and was the highest in 10-year survival and the lowest in 1-year survival (Table 2).
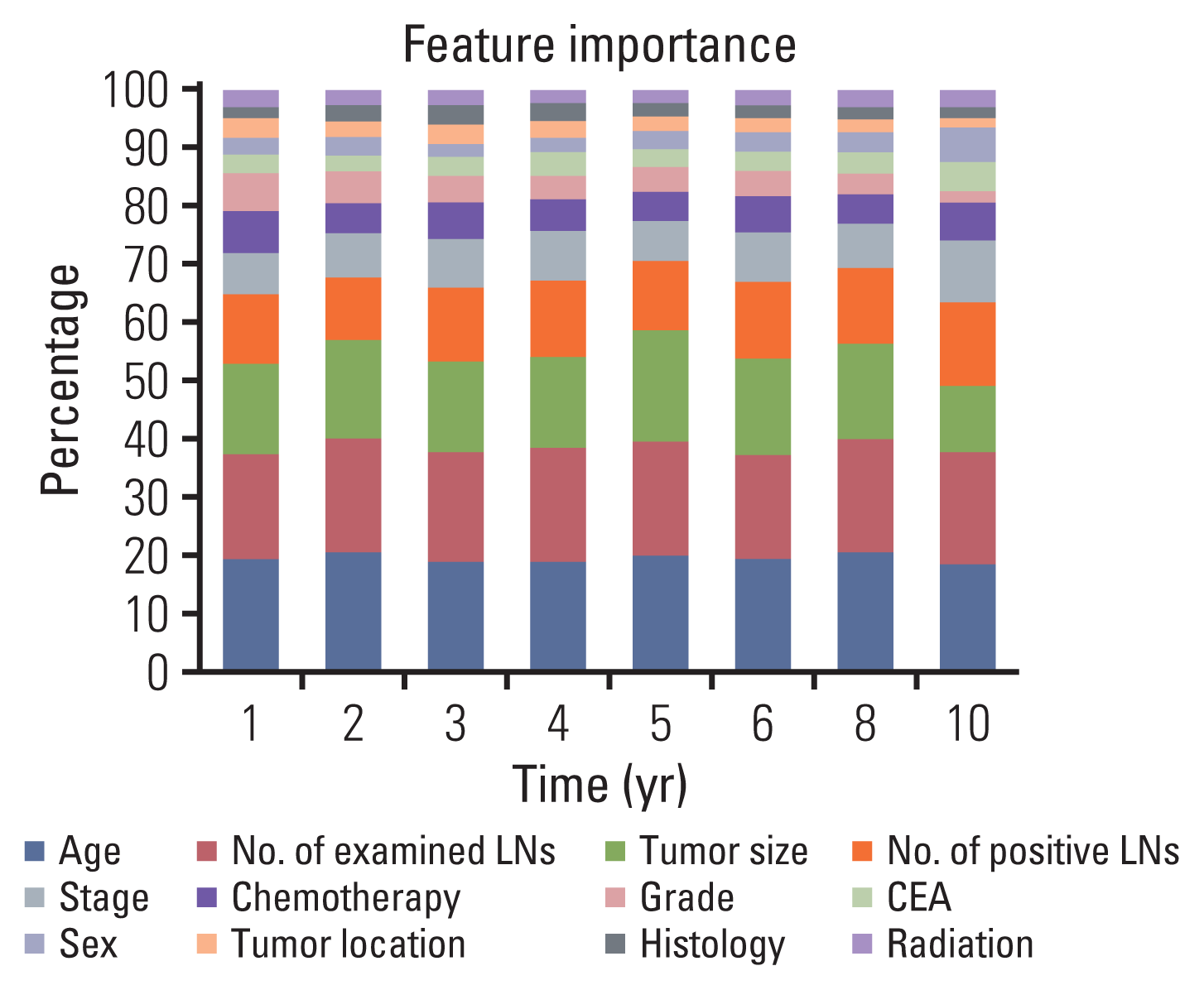
The most important features which influenced model performance in predicting survival were age at diagnosis, the number of examined LNs, and tumor size (Fig. 3).
The model showed a significant higher performance in predicting survival compared to the stage with p < 0.05 in all time periods. Especially, in predicting 5-year survival, the model achieved better AUROC than the stage (0.804 vs. 0.736, p < 0.001) (Table 3).
The model was able to maintain a good class balance when predicting 5-year-survival with sensitivity for both classes such as dead or alive of 69.28% and 77.78% in internal validation and 68.14% and 77.51% in external validation (S10 Table). Positive predictive value for both classes were 67.0% and 79.67% in internal validation and 49.88% and 88.1% in external validation when predicting 5-year-survival (S10 Table).
Discussion
Our study demonstrated that ML-based model using LightGBM developed using clinical data from SEER database can produce robust predictive model of survival in patients with CRC, and that this model was shown to outperform significantly the current gold standard in the form of AJCC stage. Thus, we believe that ML model have the potential to significantly improve individualized estimation of survival.
A previous study demonstrated that machine-learned Bayesian belief network accurately estimated overall survival with AUROC of 0.85 in colon cancer patients based on clinical data from 146,248 patients from the SEER registry [12]. However, these models were validated using only internal cross-validation, without independent external validation. It is an important issue to demonstrate generalizability of ML model. In our study, the two cohort used for development and validation of algorithm showed markedly differences in terms of ethnicity, clinicopathological variables and especially overall survival rates. Although we cannot explain the exact reason of survival gap, the fact that Korean dataset was derived from a tertiary referral center specialized for treatment of patients with CRC could be one of the reasons. However, the reason might be multifactorial, and differences in mortality by race are also seen in data analyzed within the United States, that mortality rate of CRC from 2013 to 2017 were 19.0%, 13.8%, and 9.5% for non-Hispanic black, non-Hispanic white and Asian/Pacific Islander, respectively [20]. In general, huge difference for survival outcomes can be a disadvantage when comparing two groups in a conventional clinical study. In contrast, a consistent performance of our new ML model when applying to datasets with such different baseline characteristics could be an evidence of the robustness and generalizability of our model.
Analysis using large scale clinical dataset has been regarded as a good way to reduce a selection bias. Nevertheless, a lot of missing data can occur in reporting and collecting systems based databases. In our analysis, the SEER registry had a higher percentage of missing values in different features. If we wanted to undergo conventional linear regression based multivariable analysis, these missing values had better be omitted before entering into a statistical analysis. Excluding cases with missing data would reduce included number of patients and could be an important source of selection bias. On the other hand, there are different methods for imputing missing values in order not to lose valuable information [21].
In terms of feature importance, age, number of examined LNs, and tumor size were the most important prognostic features for survival prediction than the AJCC stage. It is undeniable that several reports have proven that age, and examined number of LNs are meaningful as prognostic predictors in CRC [22,23]. With respect to tumor size, although a recent study demonstrated that tumor size had a high prognostic value of survival in T1 colon cancer, this discriminatory power did not last with more advanced T stages [24], and tumor size wasn’t found to be a significant factor to predict survival outcomes in other studies [25,26]. Although it is impossible to rule out the possibility that these three variables play certain roles in predicting survival outcomes in patients with CRC, the evidence published to date does not support the use of these parameters in the AJCC stage or current clinical practice [3,4]. Interestingly, the LightGBM didn’t consider stage as one of the most important factors when it comes to feature importance despite the stage showed higher AUROC values in the univariate analysis depicted in S8 and S9 Tables compared to other variables. One of the distinguishing characteristics of ML or artificial intelligence approaches is that we cannot inspect or explain how the algorithm works [10].
Several limitations should be acknowledged as this study is retrospective and selection bias cannot be completely avoided. We included 12 elementary clinicopathological variables to develop and validate a new ML model. Clinical significance of lymphovascular invasion, perineural invasion, or circumferential resection margin status in colon and rectal cancer respectively have been investigated already in various studies [26–28]. However, we couldn’t include those information in our prediction model as they weren’t reported in the SEER database. Moreover, many researchers tried to incorporate radiologic and molecular information in estimating survival outcomes [29,30]. Incorporating these additional features could improve performance of predictive models which should be investigated in the future. On the other hand, technical requirements when it comes to genomic and transcriptomic data demand additional cost and time. In this regard, our model had its own clinical benefit because of using only relatively easy-to-get clinicopathological data. Moreover, including more than 360,000 patients along with an external validation using a different registry and using Bayesian optimization when tuning parameters can build a robust model. Also, a web-based prediction platform was developed to provide easy access to help patients and physicians to benefit from this model in clinical practice.
In conclusion, a ML-based prediction model was developed for predicting survival of CRC patient. The model achieved a significant better performance that the AJCC stage. Clinical usefulness of further detailed stratification should be evaluated using data from prospective studies.
 XML Download
XML Download