

 PDF
PDF Citation
Citation Print
Print



INTRODUCTION
Satisfaction surveys are used to evaluate the effectiveness of services from the viewpoint of recipients and consumers. Survey protocols can be administered at intervals to large-scale groups in commercial settings or one-time to recipients at the conclusion of training [1], educational services [2], or behavioral interventions [3], among other activities. Quantitative calculation is the common means of analysis, resulting in evaluative materials that can be applied to improving services delivery. Qualitative satisfaction survey data in contrast are included less often in monitoring and evaluation analyses. This article aims to quantify the written comments from an agency-specific satisfaction survey and to examine their conversion to the imagery of Word Clouds through the use of frequency counts.
METHODS
Data collection
Data were collected by a community agency, National Community Health Partners, funded by the Centers for Disease Control and Prevention (CDC) to provide Capacity Building Assistance (CBA) to AIDS service organizations, and state/local health departments, across the United States and its territories. Programs follow the model of “prevention with positives” that emphasizes active enrollment and retention in HIV care and services with the goal of undetectable viral loads [4]. Training participants included medical personnel and auxiliary staff, such as patient navigators, retention case managers, clinical nurses, intervention specialists, HIV testers-counselors, and behavioral therapists, among other providers. Although data on status were not collected, it is known that some participants may be, and some might not be, HIV-positive.
Quantitative and qualitative data were collected through a satisfaction survey administered by trainers at each CBA event that they organized and delivered as on-site training. Evaluation focused on CBA delivery, based on participant responses to fixed-choice questions framed by a five-point scale. Beyond monitoring and evaluation of training events, the evaluator collected additional program data by on-site training observations, post-training focus group interviews (teleconference), and online quarterly follow-up survey. Focusing on qualitative data from the satisfaction survey, this analysis covers the final year of a five-year grant cycle. As the agency was funded for another five years to provide CBA to community organizations, the use of past tense reflects the completed project.
To improve evaluative rigor and complement quantitative satisfaction data, three open questions [5] asked participants what was most and least effective in the training, and what they would recommend to improve the learning experience. Question 16 (Q16) and Question 17 (Q17) focused on training elements that were considered by participants as most and least effective, respectively:
Q16: What were the MOST effective parts of this CBA event for you?
Q17: What were the LEAST effective parts of this CBA event for you?
These two questions plus Question 18 (Q18) on recommendations to improve training requested comments, after participants had completed a dichotomous agreement-disagreement checklist of eleven questions on Content and Facilitation, and for certain trainings, another four questions on Skills-Building for a total of fifteen. Collecting written comments immediately after training assured no intervening events to interfere with recalling a memorable learning experience that was perceived as appreciated, ineffective, most/least liked, different from similar encounters, and other reactions, before being filtered from immediate memory soon thereafter [6].
The five-point scale permitted calculation of mean and median scores, standard deviation, and analysis of variance, among possible metrics. Both statistical analysis and qualitative comments were used to identify what went well and particular aspects that might require review and revision. For presentation to stakeholders, written comments entered as textual data in SPSS (version 21) were sorted for coding and quantification, and made ready to prepare “input terms” to create Word Clouds.
As there were more than a thousand participants each of the final four years, this analysis is limited to the fifth and final year of the grant cycle. This circumscribes satisfaction data to the same group of trainers, guided by prevention-with-positives funding priorities initiated the fourth year, managed under the tenure of the same project director. In short, the analyzed data were collected under similar conditions.
Data coding
The first task was identifying which comments fit each question. That is, were respective comments on the most and least effective parts provided for Q16 and Q17? If not, they were coded by type and/or intent of comment, such as reflection on future utilization with clients and community members, and those unrelated to content or facilitation, e.g., distance to the training or someone “new” to the topic. This review of the qualitative data provided a perspective into participant language that facilitated code generation beyond what was “most” and “least” effective in the training.
The next step was coding. Comments varied. Most named one element such as “Interaction among participants” and “Hands-on activities were most effective.” Several persons wrote paired comments, such as “Role-play and discussion” and “Discussion with facilitator and activities,” where pairing might reverse order of the same elements. A few participants identified three elements, succinctly, “Writing, collaboration, and teamwork,” or elaborately, “Round-Table discussion – Examining myself [refers to self-reflection activity] – How one can handle stigma language.” Hyphens and capitalization were conventions several respondents used to differentiate one training element from another. For all coding, each element was listed in order of appearance.
Coded comments were reviewed by sorting variables in SPSS. This step facilitated a cross-check on coding accuracy by alphabetizing common phrases, such as “All was…” (36 times in total), variation across terms such as “role playing” (95 times in Q16; 19 times in Q17), processes such as “learning” (96 times in Q16 but not a term in Q17), activities by “group” (66 times in Q16; three times in Q17). Recommendations to improve training (Q18) were few in number and often began with “Needs more…” (33 times) or “Too long/brief” (28 times).
A few respondents inverted the intent of Q16 by responding critically on one element or the entire training, as one person who wrote, “This one did not ‘click’ for me,” with no comments on Q17 or Q18. More respondents, however, inverted the intent of Q17 on what was least effective, such as “Nothing came to my mind,” “None, it was all great,” “I enjoyed and learned from every part,” “I felt all parts were effectively implemented.” Those inverting Q17 on what was least effective more often responded to the contrastive question on what-was-most-effective (previous question), in contrast to Q16 inverters that infrequently wrote comments for what-was-least-effective (next question).
Many respondents utilized common terminology in expressing their concerns. Some used terms that varied slightly (plural or singular), such as “role play” and “role plays,” sought precision in their descriptions, such as “small-group” vs. “group,” and/ or favored stylistic variations. These differences however slight as writing are important, as they determine the outcome of inserting input terms to create a Word Cloud. Stylistic variations were too infrequent to be captured by technology that identifies and sorts common words for proportional graphic representation as a Word Cloud.
Technical Information
“Double entries” [7] were not relevant in this analysis. Each respondent had a unique alpha-numeric identifier within a training encounter. Should someone attend more than one CBA event, each experience differed with respect to content. No more than 148 persons among 1,286 participants were duplicated across training during the project’s fifth year; in addition, ten persons attended three, and five attended four training events (12.7% total repeaters).
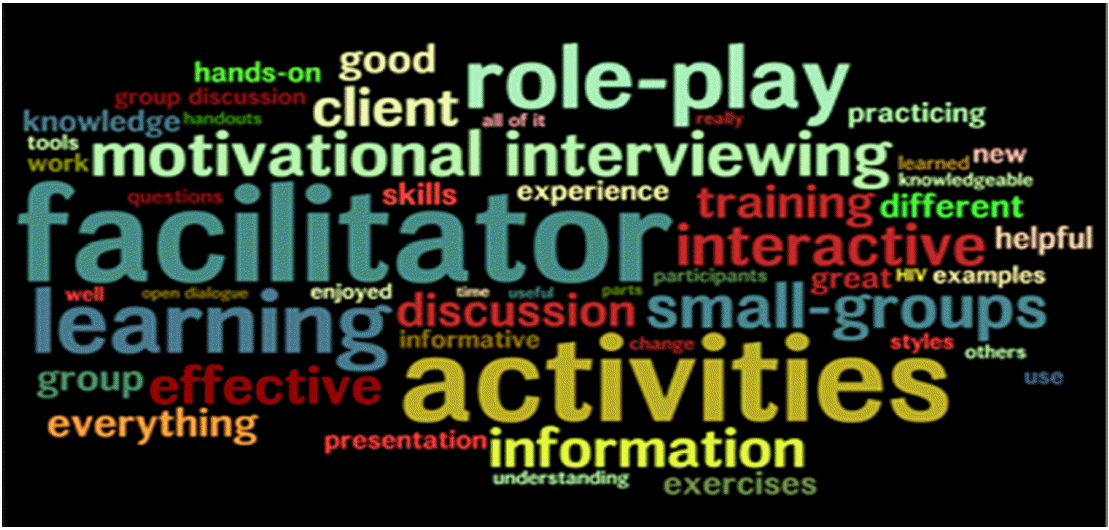
Language variability required adjustment to prepare input terms for Word Cloud technology. Respondents in Q16 and Q17 varied most in identifying “facilitator,” using close synonyms such as “trainer,” or related term, “instructor,” or possessive (e.g., trainer’s skills), and in some instances, a personal name. No more than one of 143 persons referred critically to a facilitator in Q16, compared to eight of 14 in Q17. Other common terms included “activities,” “learning,” “role-play,” “discussion,” and “interactive,” usually within favorable comments in Q16; “activities” and “role playing” were common in Q17 with less than half in critical comments. Frequent phrases in Q17 referred to dimensions of learning, such as “all was okay” and “everything was effective” (alternative terms: useful, beneficial, and informative).
Presentation conventions in this analysis included lower case in Word Clouds for affective-supportive, and capitalization for critical-negative, comments. Too few of the latter in Q16 meant that none appeared in the corresponding Word Cloud. Some appeared in Q17 in proportions less than that for comments appreciative of the training. As one person wrote, “I can’t imagine any of it out” (Q17). Proportional appearance in each Word Cloud highlighted differences in the frequency of responses to the two qualitatively dichotomous questions. Hyphens hold compound terms together in a Word Cloud (e.g., “small-groups”). The ~ symbol between terms performs the same action without a trace (e.g., “need more time”). Non-response codes were removed from input text. The code “xxx” (no response), e.g., is treated by Word Cloud technology as a word; to have it not appear, these cells were left blank.
Statistical analysis
Descriptive statistics were utilized. Coding multiple elements became cumbersome in frequency tables. Initially separated, singular elements were merged with combination statements to generate a list of elements that caught participant attention, tallied by a frequency count of identical elements.
RESULTS
Some 1,096 responses were offered by 1,286 participants at training delivered Year 5 (Table 1). Two-hundred-twenty-eight persons left blank Q16 (eight were “N/A”); 692 left blank Q17 (238 were “N/A,” 15 were “don’t know”); 190 skipped both questions. By far, more respondents in Q16 expressed appreciation and/or offered an affective-supportive comment (654/1,286: 50.9%) and identified training strengths (371/1,286: 28.8%), than those in Q17 providing criticism (155/1,286: 12.1%) and/or commenting negatively (71/1,286: 5.5%). A larger proportion (270/1,286: 21.0%) inverted the intent of Q17 that asked them to identify what was least effective than those inverting what-was-most-effective in Q16 with criticism (10/1,286: 0.8%). Thus, comments for what-was-most-effective were more frequent in Q16 than training elements reported as least effective in Q17. Altogether, four-fifths of respondents offered comments to Q16 on what-was-most-effective in the training they had attended (1,035/1,286: 80.5%) vs. less than half that commented in Q17 on what they felt was least effective (560/1,286: 43.5%). Extraneous responses were minimal (23 in Q16; 34 in Q17, or 1.8% and 2.6%, respectively).
The rationale for constructing each Word Cloud was to illustrate written comments by participants. Alterations followed the direction of each question (enumerated above). To prepare Word Cloud input terms certain words were combined in Q16, such as “role play” (singular and plural), “roll play” (misspelled) and “role playing” into role-play; “group work” into small-groups, and “exercises” and “break-out” into activities, among others. Each trainer was mentioned at least once by name (naming someone typically indicates appreciation for that person); these nominalizations with the synonyms, “instructor” and “trainer,” were converted into the term, facilitator. Words were similarly combined in Q17. The altered appearance of certain synonyms and misspelled words assured appearance validity in the Word Cloud. Thus, proportion of terms within a Word Cloud occasionally approximated rather than replicated numerical counts of respondent terms. Nonetheless, they followed respondent intent in what they wrote. In a narrative story, repetition adds emphasis to an intense experience, signals “sequential fit” to previous commentary or “repair” within conversational turn-taking, and assists in “sourcing” effective components (Table 2).
Respondents simplified responses in Q17 (148 times) usually to “none” and “nothing,” or rare comments, such as “Can’t think of any,” to invert the question intent to collect information on what was least effective. Less frequent terms, “no” and “nope,” were merged with “none” and “nothing,” respectively. Truncated statements, such as “everything was effective” and “all was good” (“okay,” “great”) were similarly merged. To generate phrases of similar length, ‘everything’ and ‘all’ were switched to “everything was okay” and “all was effective” (Table 3).
DISCUSSION
Word Clouds are dependent on holistic perception. They reinforce word recognition with the mathematical principle of proportions. Laura Ahearn [8], e.g., used Word Clouds to analyze thematic output in a professional journal. She collated keywords from American Ethnologist and converted these to frequency tables accompanied by Word Clouds.
Describing her process for creating Word Clouds, Ahearn noted the need to disaggregate phrases into core terms that represent author-chosen keywords. Based on two years of articles from each of the four past decades, she found that keywords were repeated no more than seven times over eight years, except for the descriptive terms, “anthropology” 36 times, and “social” 31 times. The frequency of common keywords diminished from early to recent decades [8].
Training elements mentioned in quantitative questions on the satisfaction survey had minimal influence on qualitative responses. Two were specific phrases, “hands-on activities” (Q12) and “questions and answers” (Q3); three were general, “materials” (Q4), “content” (Q5), “skills” (Q13-Q14-Q15); and one was global, namely, “CBA event” (ten questions). A few terms that preceded qualitative questions re-appeared in the qualitative comments, such as “activities,” (140 times), “skills” (39 times), “hands on” (11 times), “materials” (9 times), whereas others seldom were re-used, such as “content” (twice) and “questions and answers” (once). Participants in their written comments on what was most and least effective went beyond this vocabulary by repeatedly using thirteen original terms in responding to Q16 and twelve to respond to Q17. Thus, respondents demonstrated knowledge of training elements through those they repeated and those appearing as original language in their written comments.
Training element frequencies were used to prepare input terms to generate Word Clouds. Based on review of the qualitative data, close synonyms and terms of related meaning were replaced with more common root terms having the same meaning. Otherwise, synonyms would have diluted the visual impact of frequently-mentioned training elements in the Word Cloud. As Jonathon Friedman, who created the technology for Word Clouds, explains, “The size of the word in the visualization is proportional to the number of times the word appears in the input text” (http://Wordle.com). The program clusters each word according to frequency. Capitalized and lower case words and those spelled correctly and incorrectly, appear separately.
Generated patterns are automatic in Word Clouds at the discretion of the online program. They are guided not manipulated. Choice of script and letter size, color schemes, number of words, and placement (horizontal, vertical, in-between) are what generate visible para-textual variation in pictorial Word Clouds [8]. Rethinking the reason for the Word Cloud as a visual display of responses led to placing the label at the top, as the question answered by the Word Cloud (Appendix). Participants identified effective elements in Q16, and for Q17 the words left no doubt that they appreciated the training and were responding figuratively against the notion of “least effective”.
A data table below the Word Cloud followed by summary text adds second and third components. The number table with each Word Cloud centers the satisfaction survey as a data-gathering tool to remind the viewer that the Word Cloud displays quantitatively converted qualitative data. Visible terms in the Word Cloud above a data table initially draw viewer attention, as ordered space above/below catches attention quicker than left/right or front/back [9]. Making the survey words “visual” [10] reveals overall participant intent.
Abbreviated text at the bottom summarizes the table data, whereas visual imagery on top receives prominent consideration. Comments that summarize and/or clarify aspects of the Word Cloud (e.g., totals and sub-totals) are embedded in a horizontal-vertical table of rows in two columns followed by an across-the-page textual summary. Word Cloud multiplicity, then, eases the task of accessibility of meaning in going from top to middle to bottom. The three-tier display format facilitates cognitive processing of the qualitative participant responses.
The project described herein, similar to that reported by Laura Ahearn, generated an individualistic display of visual multiplicity [8]. A Word Cloud brings us closer to the truth of what participants wished to communicate versus the reality of frequency counts. When responding to qualitative question-prompts, training participants who receive CBA services are likely to produce a multiplicity of written comments that parallels the authors in Ahearn’s analysis of keywords published in professional articles from American Ethnologist. As social beings presented with opportunity for self-expression, cognizant of an indeterminate audience, people seek to engage others by communication with novel meanings and aesthetic forms [11]. An intensive training experience motivates learners to move words and ideas around in their heads, gain from the experience, and later place them together in meaningful comments. I confirmed the efforts of training participants by arranging their qualitative comments into Word Clouds, and through coding and counting the terms they used to verify that I constructed a reasonable approximation that is true to their intentions.


 XML Download
XML Download