

 PDF
PDF Citation
Citation Print
Print



INTRODUCTION
There is an increasing interest in real-world data (RWD), known as medical big data.123 Clinical studies that use electronic medical record (EMR) data including a patient's history of symptoms, diagnosis, and treatment, are becoming more common.4567 However, the security measures required for EMR data are becoming more stringent to protect patients' privacy.68 As data security increases, the utilization of data inevitably decreases. It is almost impossible to obtain written consent when performing big data research; instead, we have to de-identify “personally identifiable information.”910 In terms of de-identification, a major controversy exists regarding the use of personally identifiable information for an analysis.
In Korea, revisions have been made to “three data-related bills,” which collectively refer to the three laws of the Personal Information Protection Act (PIPA), Information and Communications Network Act, and Protection of Credit Information Act.1112 Among these data regulation bills, the amended PIPA is the most interesting for the medical field.13 It introduces the pseudonymization of information for data use, reinforces the responsibility of honest brokers,14 and clarifies the ambiguous “personally identifiable information” criteria. An important aspect of this act is that if data are acquired for legal use (statistics, scientific research, and record for the benefit of society), it is permissible to use them “without the consent of the data subject” if the data are pseudonymized.1112
The Korean Personal Information Protection Commission (PIPC) published guidelines for pseudonymization.15 Subsequently, PIPC and the Korean Ministry of Health and Welfare published the “Guideline for Utilization of Healthcare Data”16 to clarify the ways in which clinical data can be used for research. However, some non-governmental organizations are still concerned about personally identifiable information being leaked17; therefore, researchers should be aware of these guidelines and conduct research carefully, because various unexpected problems may be encountered.
However, in practice, clinical researchers are not completely satisfied and are not able to easily comply with the government guidelines regarding the use of EMR data. In fact, the guidelines are primarily focused on processing and pseudonymizing existing medical data to suit personally identifiable information protection purposes. However, in terms of “operational definition” and “data quality management (DQM)” for actual clinical research, there are many cases in which large amounts of data must be randomly created, deleted, or are subject to secondary transformation.18 During this process, pseudonymized data are significantly modified compared with original medical records.819 The clinical data created by modifying the original data to a certain extent can protect patients' privacy. This means that the role of the researcher is important.
Furthermore, cooperation between those performing pseudonymization (honest brokers) and researchers is highly essential for accurate clinical research. An honest broker should understand the purpose of a researcher given that the quality of pseudonymized data could be insufficient to fulfill the aim of targeted research. Additionally, because the degree of pseudonymization varies according to the purpose of a clinical study, researchers should carefully choose the pseudonymization methods.
Because this process is not easy, active participation of a clinician is necessary in addition to the basic role of an honest broker. Therefore, in this study, we describe a specific DQM for the protection of personally identifiable information. However, this DQM is not covered under some of the guidelines based on what should be considered when used in actual clinical research.
PERSONALLY IDENTIFIABLE INFORMATION, PSEUDONYMIZED INFORMATION, AND ANONYMIZED INFORMATION
First, it is important to understand the concepts that define the levels of privacy protection. Based on the purpose of the investigation, researchers should clearly define in advance whether personal, pseudonymized, or anonymized information is needed. Personally identifiable information refers to information2021 that could help identify a specific individual. Pseudonymization is the process of processing data by deleting or replacing personally identifiable information, partially or completely, such that the individual is unrecognizable without additional information. Anonymized information refers to information that can no longer identify an individual, with or without other information combined, when time, cost, and technology are considered.
While anonymized information is the strongest in terms of data security, followed by pseudonymized and personally identifiable information, personally identifiable information is the most valuable, followed by pseudonymized and anonymized information. Although PIPA recommends using anonymized information first whenever possible, pseudonymized information is used when the purpose of the study cannot be achieved with anonymized information, and personally identifiable information is used when the purpose of the study cannot be achieved with pseudonymized information.222324
It is crucial to use personally identifiable information for rare diseases because the researchers need to identify the individuals23; therefore, the patient's consent is required in such cases. However, anonymized information is usually sufficient for studies based on the frequency of drug use according to age.25 On the other hand, pseudonymized information should be accurate or comprise enough personally identifiable data to determine the blood sugar control rate according to the age, sex, or prevalence of the individual. Therefore, it is necessary to consider the purpose and direction of the research before choosing the EMR data. For example, if a researcher plans and conducts a study using anonymous information during data collection, and additional information is required later, the study will have to be conducted again from scratch. It is also essential to distinguish between a situation in which it is necessary to specifically identify an individual and a situation in which a 1:1 matching (singling out) occurs. Strictly speaking, identifying an individual is “identification” and 1:1 matching is “individualization.” If the researcher attaches additional information to the individualized object and finds out who it is, it is referred to as identification. However, from a research point of view, individualization is mainly used when connecting different databases. It is not possible to attach additional information in EMR because individualization alone does not allow for attaching information. Some level of identification (e.g., the researcher knowing the patient number) is required to attach additional information. In addition, a mechanism capable of matching the same person in time-series data prepared differently with time differences may also be required. Most importantly, the quantity and quality of information that can be extracted decrease significantly as the data approaches anonymization.8 However, considering that PIPA has strict punishment criteria, it is safer to proceed conservatively.1112
Recently, anonymization was strictly required to publish highly ranked papers26 with all identifiable data deleted and the sex, coded. Additionally, the patient's age was specified as “in their 20s/30s/40s” to eliminate the possibility of estimating a particular patient based on the birth year.
DIFFERENT PSEUDONYMIZATION TECHNIQUES FOR THE SAME CLINICAL DATA
Identifiable information such as the patient's name, phone number, social security number, e-mail ID, passport number, driver's license number, alien registration number, and contact information must be suppressed on pseudonymization. For epidemiological studies, the address could be included, but the specific number must be pseudonymized regardless of the purpose of the analysis (partial suppression or masking). While it is advisable to delete the date of birth, in cases where the year of birth is reflected, the month and day are deleted. Typically, the age is preferred over the date of birth in clinical studies because the age at which an event occurred is more important than the date of birth. As mentioned above, some renowned journals recommend expressing age in decades (i.e., the 20s, 30s, etc.).26
The guidelines stipulate those values measured by physical conditions, such as height and weight, do not require separate pseudonymization as there is no guarantee that repeated measurements would result in the same number.1112 However, this is the only method to protect a patient's personally identifiable information, and secondary processing must be performed separately for research purposes.
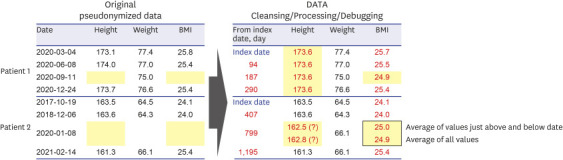
Generally, when a patient visits the hospital more than once, the different values of the measured height do not match (Fig. 1). While this may not be problematic for pseudonymization-based studies, it is difficult for researchers because it is their concern whether to use the average height value or the actual height. Using the average height alters some or all personally identifiable information is changed, thus reducing the amount of missing data and ensuring pseudonymization. If the average height value is not used, the data are missing if the height was not checked during the visit. Therefore, for the actual height, entering the average value is beneficial when there are many missing data. However, care should be taken in the case of elderly patients (as in osteoporosis studies) because height may decrease over time.27 Therefore, it is not always possible to recommend using only the average value. That is, to process statistics, the opinions of clinical experts associated with the research purpose are required. For example, if height was measured four times and one value is different from the other three, we can delete it and replace it with the average of the other three values. However, in actual clinical practice, many cases demonstrated two values differing from the other two values. Although the judgment of the clinician is essential, it is necessary to consider it deeply because it might be viable to simply delete ambiguous values.
Fig. 1
Example of changing the height of the patient. Based on the BMI value of 25.0 kg/m2, which is the criterion for obesity, it is important for researchers to consider that the treatment method may be completely different because of this simple conversion of values.
BMI = body mass index.
As another example, systolic blood pressure and diastolic blood pressure require DQM. In actual EMR data, many of these values are recorded in reversed order. While medical staff may recognize a mistake in the values, a researcher cannot change the data arbitrarily. When values are out of range, a data table specification is created through operational definition prior to the study to change or delete that information.5 Additionally, modifying these data also prevents the re-identification of personally identifiable information.
The most significant problem is that it modifies data quality, and we need to apply different techniques for the same clinical data based on the context.28 This has already been carefully emphasized in various studies.2829 We cannot overlook the fact that the clinical quality of data suitable for a research purpose reduces with the increase in the level of pseudonymization and anonymization.8 If the researcher changes the value according to the purpose of the study, the data are also altered. This limits the ability to identify a particular individual. For example, if a researcher changes a person's height from 180 to 170 cm, it could identify a completely different person. Moreover, clinically sensitive areas may be affected. If the body mass index (BMI) changes owing to a change in height, it may result in a change in the clinical criteria. When BMI changes, the boundaries between normal and obesity also change, and the diagnosis and treatment may change accordingly. Utmost care should be taken when changing a value from the patient's original data.
SECONDARY DATA PROCESSING BY CLINICIANS, NOT BY THE HONEST BROKER
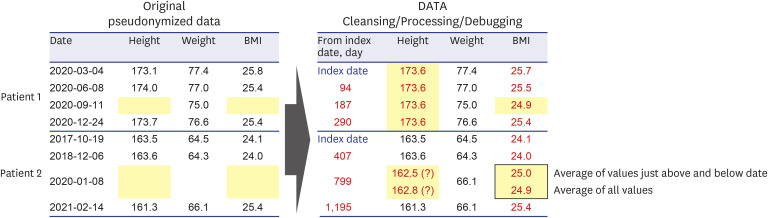
In some cases, new data are added by the researcher. For example, if one value out of the four values for total cholesterol (TC)/triglyceride (TG)/high-density lipoprotein cholesterol (HDL-C)/low-density lipoprotein cholesterol (LDL-C) is missing, the null data can be filled (official example; LDL-C = TC − TG/5 − HDL-C) (Fig. 2).30 Values outside the range that can be measured by medical devices in hospitals need to be treated according to the purpose of the study. The most typical case is when it is expressed as a string or outlier, not a number, such as “TG < 5 mg/dL” or “TG > 1,995 mg/dL.”18 This requires a deep understanding of RWD. RWD are not intended for clinical research purposes. Therefore, to conduct clinical research on RWD, it is necessary to understand their limitations.2 In fact, looking at changes in LDL-C levels in retrospective cohort studies is not a good idea. This is because, in RWD, there are many limitations in viewing the average change in laboratory findings owing to differences in drug compliance and visit intervals. Rather, in RWD, it is more advantageous to check the target achievement rate rather than the average change (Fig. 2). For example, if we want to check the target rate of less than 200 mg/dL, we can change it to “0” for less than 200, and “1” for more than 200. According to this method of operation, no data omission occurs, and data security is improved. If we want to know the overall distribution of a certain value rather than the target rate, a more subdivided group can be created (less than 200 is “1,” 200–300 is “2,” 300–400 is “3,” 400–500 is “4,” and 300 or more is “5,” etc.). If we want to compare the average values in various situations, it is recommended to delete the string; however, reliability will decrease.
Fig. 2
Real clinical example of transformation of data according to research purpose. There was a clinically significant difference in the number of datapoints added from the number of initial baseline data (from 267,979 to 280,127 points, P < 0.001).
HDL-C = high-density lipoprotein cholesterol, LDL-C = low-density lipoprotein cholesterol, TC = total cholesterol, TG = triglyceride.
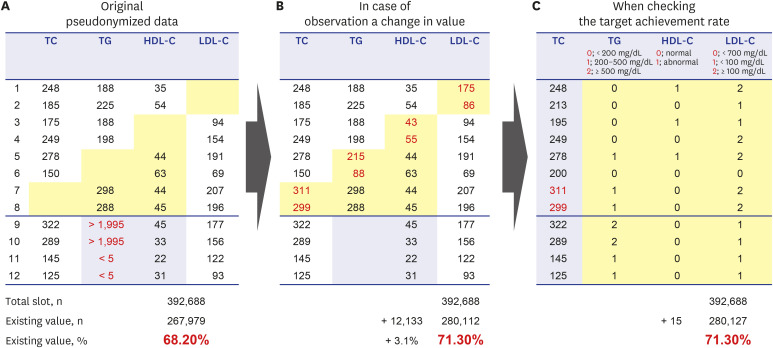
In addition to subdividing the groups mentioned above, group consolidation is also frequently used (Supplementary Table 1). As the date of visit is also identifiable, it is deleted or processed, but it cannot be done mechanically or automatically. For various reasons, even when de-identifying, the clinician must be careful to do it in accordance with the purpose of the study. For example, suppose we want to check the effects of a specific drug for three months and later in RWD. From the RWD, it can be observed that some patients visited after a month instead of three months, some patients visited at four months, and some patients discontinued visits. There is no definite three-month time point, as in the randomized control study. Even if a patient visits the hospital on a regular basis within three months, there is no evidence that the patient has taken the specific drug as prescribed. It is difficult to properly comprehend the effects of the drug after three months. RWD cannot determine the inherent effects of the drugs. In this case, to protect personally identifiable information and minimize data loss, the patient's visit date is segmented to lower the possibility of identification. After the visit is segmented, all patients visit dates are deleted. It is possible to reduce de-identification of data by grouping similar diseases based on patient's “disease information (International Classification of Diseases, 10th Revision [ICD-10] classification),” as well as the patient's visit date (Fig. 3). New disease definitions can be created and written by combining ICD-10 codes with various treatment codes. This secondary processing of data not only minimizes data loss but also contributes to data security. However, at the moment, this work is not done by clinicians, but by honest brokers, which can lead to various unpredictable problems.
Fig. 3
Example of emphasizing anonymization by consolidating diagnosis names. Anonymization is emphasized, but the quality of the data is not affected. All data has been completely changed or added differently from the original data.
HF = heart failure, MACE = major adverse cardiac events, MI = myocardial infarction.
FIRST CASE EXAMPLE: CHANGING PATIENT'S DATA TO AN AVERAGE VALUE
Patient 1
After determining the first visit as an index date, all subsequent visit dates were numerically indicated by the interval from the index date. This allows the data to be anonymized. As a result of changing the height, a new height value that was not included in the original data was created. As a result, the measured BMI values also changed from 25.8/25.4/null/25.4 to 25.7/25.5/24.9/25.4 kg/m2). Numerical values that are different from the original data clearly help to protect personally identifiable information. In addition, the method of changing null data to an average value is the most advantageous for minimizing data loss (Fig. 1).
Patient 2
We cannot always recommend an average value for older people, because there is a gradual decrease in their height. However, when one value is missing, it is worth considering the average of the values immediately before and after it. It is also necessary to properly view and calculate the back-and-forth interval. Before the study, it is also necessary to remove the abnormal values that contradict common sense.18 It should be noted that owing to methodological differences, one BMI value is 25.0 kg/m2 or more, and the other BMI value is less than 25.0 kg/m2. Based on the BMI value of 25.0 kg/m2,31 above which indicates obesity, this simple conversion of values can completely change the treatment method. This is a serious consideration for clinicians. Finally, the most important point is that clinical researchers need to scan the data directly (Fig. 1).
SECOND CASE EXAMPLE: REAL CLINICAL EXAMPLE OF TRANSFORMATION OF DATA ACCORDING TO RESEARCH PURPOSE
Let us consider the example of a statin data mart built for research purposes at St. Mary's Hospital in Seoul (Fig. 2).5 We extended the extraction time in the previous statin data mart to obtain a larger number of samples. Because there are four lipid profiles (TC/TG/HDL-C/LDL-C) and 98,172 patients, there should be a total of 392,688 data points (4 × 98,172), but only 68.2% of the data points were present (61,497 in LDL-C + 62,209 in HDL-C + 71,324 in TG + 72,949 in TC = 267,977). As shown in Fig. 2B, a total of 12,133 data points could be newly generated using the expression, LDL-C = TC − TG/5 − HDL-C.30 Certainly, these values did not exist in the original dataset. In the case of a study on the target achievement rate rather than the change in the average value (Fig. 2C), 15 new data points were applied without being deleted. An additional 3.1% {(15 + 12,133)/392,688} of data were generated. There was a clinically significant difference in the number of data points added from the number of initial baseline data points (from 267,979 to 280,127 points, P < 0.001). This is the result of preventing data loss and ensuring proper anonymization. In conclusion, this is a way to increase the number of data samples while enhancing anonymization.
THIRD CASE EXAMPLE: EMPHASIZING ANONYMIZATION BY CONSOLIDATING DIAGNOSIS NAMES
This method is often used to determine the occurrence of a specific disease (Fig. 3). Several diseases were combined into one category. For example, nonfatal stroke, nonfatal myocardial infarction, and cardiovascular death were integrated into “3-point major adverse cardiac events (MACE),” or hospitalization due to heart failure and unstable angina are added to the “3-point MACE” and integrated into a “5-point MACE.”3233 If there is an index date for a specific research purpose, the index and disease onset dates can be calculated and expressed. In this case, the data were anonymized. A negative value denotes the patient's history because it is the disease before the index date, and a positive value denotes the interval from the index date to the occurrence. If there is no history before the index date, it can be replaced with “null (or other value),” and if there is a past history, it can be replaced with “0.” Thus, data anonymization was strengthened, but the quality of the data remained unchanged.
REQUEST DATA ANALYSIS FROM OTHER ORGANIZATIONS
Another aspect to be considered is whether the researcher will conduct the study with the data extracted from the hospital, or whether the data were requested from an analysis institution other than the hospital. This is because it is necessary to determine the pseudonymization/anonymization method and the application environment suitable for research purposes and methods. When data analysis is entrusted to an institution other than the hospital, not only a pledge not to provide the data to a third-party is specified in the guidelines but also a contract with additional details is required. To prevent the risk of leakage, the following statements are required: a statement that the data will be stored in a secure in-house network that cannot be accessed from outside, a statement that the data will be managed in such a manner that only authorized personnel among internal employees can access them, and that the person who accesses the data as well as the access history are also recorded. This includes a statement that the company should write an accurate list (specify the number of people) of the personnel who can access the data, and a statement that if anyone other than people in this list accesses the data, the company will be responsible. From the story of ownership of the results after analysis, the statement that the provided pseudonymized data will be completely destroyed after the end of the study, and the liability for damages in case of data leakage should be mentioned. As many of these measures must be prepared in advance, it is recommended to continue to move conservatively until dismissal, precedent, and interpretation of the rules.
CONCLUSION
Anonymization of medical data is essential for protecting personally identifiable information in the field of medicine, and for promoting the development of new medical products and techniques. Excessive or weak pseudonymization can result in the loss of data or the inability to provide an adequate level of protection for the data. Information that was absent in the original dataset could be added or modified when pseudonymizing data, which can make a significant difference compared to the actual data because modified data may span most of the data (Figs. 2 and 3). Therefore, when considering such factors, the most suitable approach is to solve them internally instead of using an analysis agency. However, data analysis institutions are excellent in terms of equipment and facilities (e.g., artificial intelligence), and it is inevitable to engage them. Considering the laws that have been in force, it is better for each hospital to immediately establish an internal management plan considering it is important to be observant of the interpretation and precedents of data. Moreover, it is better to emphasize more on proper DQM along with data security when considering the fundamental purpose of clinical research.18
Although the level of pseudonymization and clinical use of data have a trade-off relationship, it is possible to create pseudonymized data while maintaining the quality of data for the given research purpose. However, while pseudonymization can be performed by the honest broker, researchers should carefully guide the process. Because both privacy and practical use of clinical data, and a harmonious balance are required, the active participation of clinicians is essential as it can induce data generation instead of the loss of data while maintaining the level of data security based on the research purpose. Furthermore, depending on the degree of active participation of the clinician, data anonymization can be strengthened without affecting the data quality.
 XML Download
XML Download