

 PDF
PDF Citation
Citation Print
Print



I. Introduction
The significance of cancer information is widely acknowledged, particularly in light of the changing prevalence of the disease worldwide and its profound impact on families, economies, and societies [1]. With the rise of the internet, particularly social media platforms, cancer patients are increasingly turning to these channels to share their experiences, connect with support networks, and exchange information related to cancer. To alleviate the socio-economic burden on cancer patients, it is crucial to provide accurate and essential health information [2].
Cancer patients and their families actively seek medical information through various channels, leading to exposure to a wide range of sources. However, the spread of misinformation—incorrect or misleading information presented as fact—presents significant challenges for these individuals. A prominent example is the fenbendazole case in Korea [3]. Originally developed as an anthelmintic for dogs, fenbendazole became controversial due to the proliferation of false claims on social media about its supposed efficacy in curing cancer when ingested [4].
As the importance of monitoring the information that cancer patients access on the internet continues to grow, there is a corresponding need to develop technology that can enhance the accessibility and usefulness of information found in published literature through text mining [5]. Text mining involves automatically extracting information from various written resources and transforming unstructured text into a structured format to identify meaningful patterns and uncover new insights [6]. This technique has emerged as a potential solution for bridging the gap between free-text and structured representation of cancer information [7]. It enables the extraction of valuable information and knowledge from extensive textual data and is now widely applied in biomedical research [8]. Some studies have employed text-mining technology to uncover new insights, thereby contributing to advancements in biomedical research, particularly in the field of malignant diseases such as cancer [8].
An accurate understanding of the latest trends in cancer-related information consumption is crucial. In this context, “cancer-related information” refers to data spanning the entire cancer control continuum, which influences aspects of cancer prevention, screening, diagnosis, treatment, and survivorship [9]. Topic modeling has facilitated the identification of keywords in cancer-related information accessed by individuals, providing a comprehensive analysis and visualization of cancer-related messages [10]. As a widely utilized statistical methodology, topic modeling examines the words within original texts to uncover hidden themes or topics, and explores how each topic is interconnected and evolves over time [11]. This technique offers the advantage of producing objective and clear analytical results through the statistical analysis of research topics.
As online news consumption continues to grow, a variety of platforms for accessing news content have emerged, with portal sites being a notable example. Portal-based news acts as relatively unbiased aggregators, offering a broad selection of articles from various media outlets [12]. Additionally, online news is typically available free of charge, which enhances public accessibility. According to the Reuters Institute for the Study of Journalism, South Korea has the highest reliance on search engines, such as portal sites, for digital news consumption among 46 surveyed countries [13]. Specifically, 72% of Korean users reported using search engines as their primary source for online news, a proportion that is twice the average across the surveyed countries [13]. As the incidence of cancer increases among older adults, so does interest in cancer-related information, with portal-based news articles being the most widely consumed source for such information.
Therefore, this exploratory study aimed to collect and analyze internet articles posted on a portal site throughout 2023. The goal was to identify trends in the information available to cancer patients and to derive meaningful implications. The study focused on identifying keywords in cancer-related articles from 2023 to understand the types of information that cancer patients encountered during this period. The analysis provides a comprehensive analysis of cancer-related information consumption trends in South Korea in 2023, highlighting unique aspects such as the impact of portal-based news on public understanding and the role of text mining in uncovering insights not addressed in previous studies. By doing so, the study provides a basis for providing targeted information tailored to the specific informational needs of cancer patients.
II. Methods
1. Study Design and Data Collection
This exploratory study aimed to identify and evaluate the types of cancer-related information that the public encounters and consumes. Social media has significantly transformed how news is produced and consumed, influencing the public’s interpretation of various issues [14]. To examine trends in cancer-related news, we collected the titles of news articles published between January 1, 2023, and December 31, 2023, from Naver, a leading Korean portal site. For text analysis, we selected articles from Naver’s news section using the search term “am” (Korean for “cancer”). A total of 19,578 news articles were gathered and organized chronologically to ensure comprehensive monthly coverage. The text was then segmented into Korean word units for further analysis. All data were analyzed and visualized using Python 3.11.4 (Python Software Foundation, Wilmington, DE, USA)
This study was waived by the Institutional Review Board because it utilized online article data.
2. Natural Language Processing in Text Mining
Text mining and natural language processing (NLP) have received extensive attention for their advanced capabilities in managing and analyzing text-based information [15]. Considering that text is the predominant data type in all stages of data construction management, with over 80% of data being unstructured, it is crucial to effectively retrieve specific textual information from documents [15]. Moreover, NLP includes techniques such as morpheme analysis, and word and sentence generation, which are essential for text mining applications. Once relevant text documents are retrieved, the character strings must be processed to enable computer analysis. Therefore, the input must be specifically formatted to allow computers to understand natural language in the same way humans do [16]. NLP utilizes a range of linguistically inspired techniques, including syntactic parsing with formal grammar and lexicons, which aid in the semantic interpretation of textual data [17].
3. Data Analysis
1) Data preprocessing
In the data preprocessing phase, article titles were retrieved using the BeautifulSoup and Pandas libraries (version 2.1.4). Special characters, except for Korean, numbers, and English, were removed using regular expressions. Unnecessary spaces were also eliminated, resulting in a clean corpus that enhanced data quality and facilitated subsequent text analysis. Nouns were extracted from the corpus using the Mecab module from the KoNLPy library (version 0.6.0). To concentrate on meaningful terms, single-character nouns were excluded, and noun frequencies were calculated using the Counter object.
To address the issue of out-of-vocabulary (OOV) words that were not captured by the Okt module, we employed the LRNounExtractor_v2 algorithm from the Soynlp library (version 0.0.493). Proper management of OOV words is crucial because their omission can significantly impact the performance of NLP models [18]. The LRNounExtractor_v2 algorithm identifies noun candidates from large corpora using unsupervised learning and calculates a reliability score based on word frequency and contextual information.
2) Frequency analysis
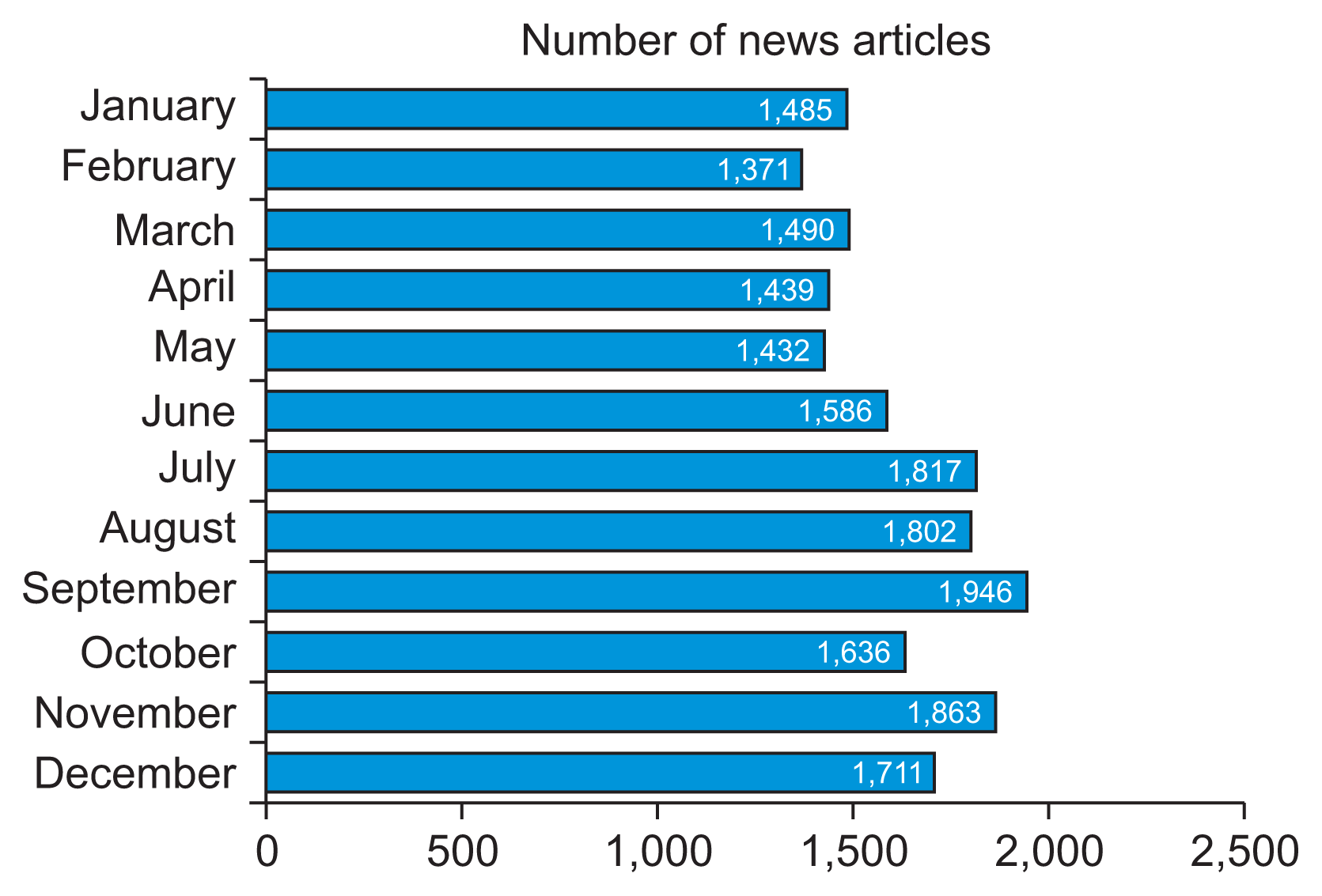
The primary objective of this study was to identify prominent keywords for each month, as well as for the entire year of 2023 (Figure 1). Text mining, a technique that transforms unstructured text data into a structured format, was employed to analyze hidden patterns and relationships, thereby extracting meaningful insights.
This study utilized term frequency (TF) and term frequency-inverse document frequency (TF-IDF) analyses to identify keywords from cancer-related articles following text preprocessing. The Counter function from the Collections library (version 2.1.1) was used to compute TF values, and the top 100 high-frequency keywords were selected for further analysis. The data were then transformed into a data frame, and visual word clouds were created using an online tool (https://www.wordclouds.com) to emphasize prominent cancer-related terms for each month (Figure 2).
TF-IDF values were calculated for the top 100 TF-based keywords from the news title dataset. TF-IDF, a common tool in morphological analysis, evaluates the importance of specific terms by integrating a two-dimensional TF matrix with a scalar IDF value [19]. Words that appear frequently in a single document or a small group of documents typically achieve higher TF-IDF scores. It is crucial to recognize that while TF-IDF considers word frequency, it does not incorporate regularization [19]. The TfidfVectorizer class from scikit-learn (version 1.5.2) was utilized in Google Colab to compute the TF-IDF values, which were then stored in a sparse matrix format. This matrix was aggregated by column to assess the overall significance of each word across the dataset.
3) Network analysis
Network analysis is a set of techniques used to visualize relationships among actors and analyze the social structures that emerge from these interactions. From the perspective of network analysis, the relationships between variables contribute to the formation of underlying phenomena [20]. In this study, the top 50 nouns were selected to examine and visualize the relationships between keywords, as shown in Figures 3 and 4. The analysis was enhanced by incorporating missing OOV words using the LRNounExtractor_v2 algorithm. Only nouns that appeared at least 15 times and had a reliability score of 0.5 or higher were considered key terms.
An undirected, weighted graph G = (V, E) was constructed using the networkx library (version 3.1). In this graph, nodes (V) represent individual keywords, and edges (E) represent co-occurrences, indicating that two keywords appeared together within the same article title. The weight of the edges was determined by the frequency of co-occurrence, providing an intuitive representation of the relationship between keywords.
Keyword clusters were identified using the Louvain algorithm from the community module (version 0.16), which detects communities by optimizing modularity for efficient clustering [21]. The weight and length of edges were inversely related; higher weights corresponded to shorter edge lengths, indicating stronger relationships between keywords. The network structure was visualized using the Spring layout algorithm, which arranges nodes based on the physical forces acting between them. Each cluster was visually distinguished by assigning distinct colors to the nodes of each community detected by the Louvain algorithm, facilitating clear differentiation between keyword clusters.
III. Results
Frequency analysis quantifies the number of cancer-related articles published on the portal throughout 2023. A higher frequency indicates a greater number of articles addressing cancer during specific periods, reflecting heightened attention to particular issues. In total, there were 19,578 news articles containing the keyword “cancer” (“am” in Korean). A monthly breakdown showed an average of 1,631 cancer-related articles per month (Figure 1), with the highest frequency in September (1,946 articles) and the lowest in February (1,371 articles).
In 2023, a total of 132,456 keywords were identified across all cancer-related news articles. Table 1 lists the top 20 most frequently occurring keywords, with the original Korean terms translated into English. The most common keywords included “cure,” “struggle,” “patients,” “lung cancer,” “antitumor,” “hospital,” “breast cancer,” and “pediatric cancer.” Notably, “cure” appeared 2,218 times, “struggle” 1,844 times, and “patients” 1,777 times. Among the types of cancer, “lung cancer” was mentioned 1,652 times and “breast cancer” 1,235 times, making them the most frequently discussed. The TF-IDF analysis assigned the highest importance score to “struggle” (1064.172), followed by “lung cancer” (839.988) and “breast cancer” (744.840). While there was a slight difference in the ranking of terms between TF and TF-IDF, both analyses consistently emphasized these key terms.
Figure 2 visualizes the top 100 keywords using a word cloud representation. Table 2 displays the monthly frequency of the top 20 keywords, highlighting not only the major cancer-related topics for 2023 but also the dominant terms for each specific month. All keywords have been translated from Korean into English to enhance clarity.
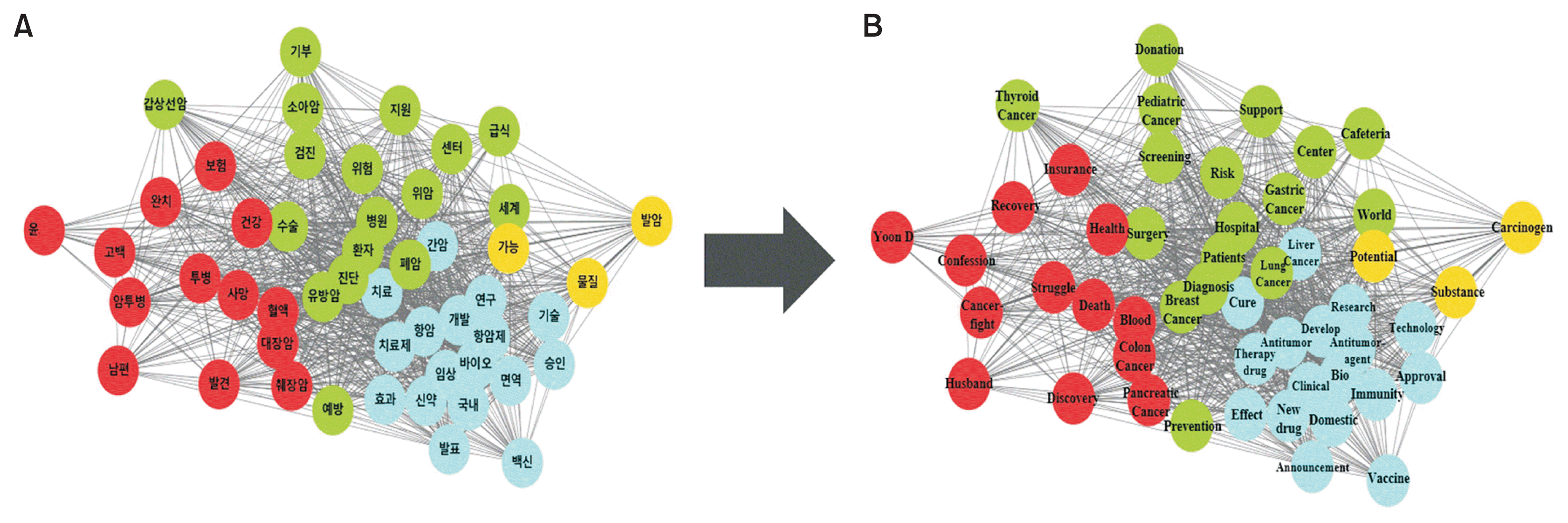
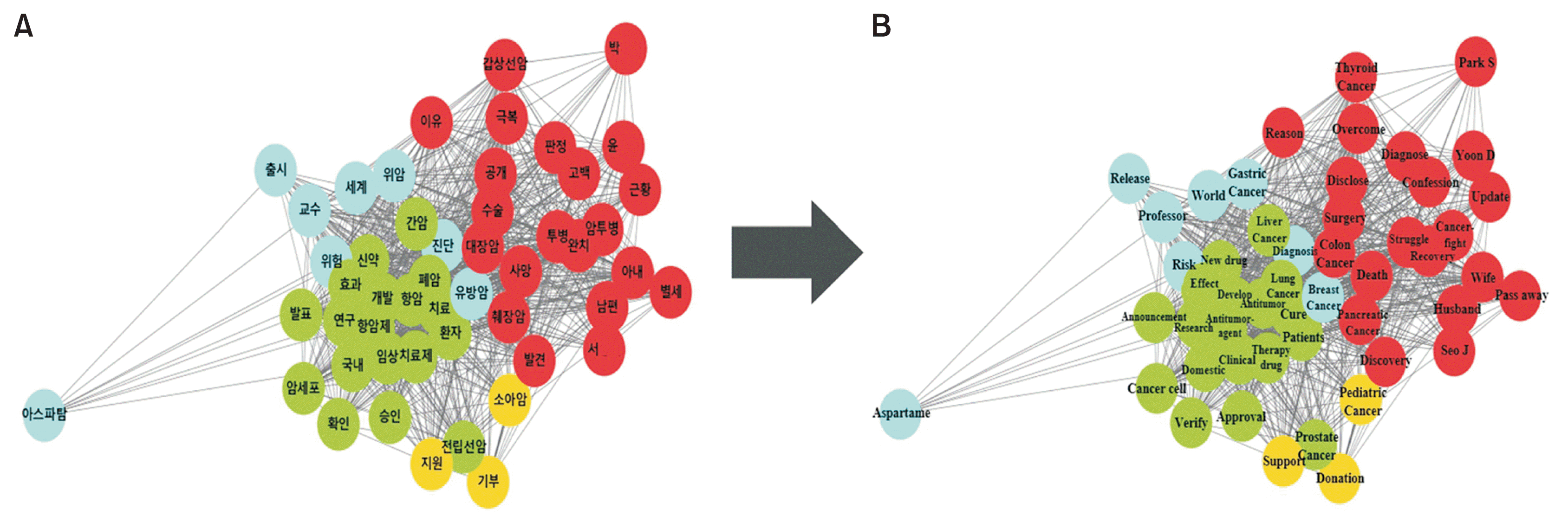
Network analysis of the top 50 keywords, based on term frequency, identified clusters of related terms depicted in distinct colors; proximity within the figure indicates the degree of relevance (Figure 3). We identified four distinct clusters, each centered on different themes: treatment-related discussions including new drug development, celebrity-related issues, major cancer concerns, and factors contributing to cancer such as carcinogenesis. Keywords like a celebrity’s name, “donation,” “carcinogen,” and “vaccine” served as hubs, demonstrating strong direct connections to other nodes. A similar network analysis, focusing on keyword importance, is shown in Figure 4, with a comparable classification.
IV. Discussion
Accurate and reliable information about cancer is crucial for patients to manage their condition effectively [3]. For cancer communication to effectively disseminate information, it is essential to understand the context in which this information is obtained. Studies have indicated that health information on social media often lacks quality and can be biased, potentially leading to harmful consequences for users [22]. Monitoring the dissemination of online information and reviewing related research are crucial steps in addressing this issue. Therefore, this study aims to collect and analyze internet news articles posted on major portal sites in South Korea throughout 2023, to identify the cancer-related information accessible to and consumed by cancer patients. By examining the information that has been consumed, this study seeks to establish a foundation for determining the information that is still needed.
Based on our results, the majority of the top-linked and exposed keywords were related to common cancers such as lung and breast cancer. This suggests that most articles focus on common cancers, indicating a lack of information on rare cancers despite the demand for them. This implies that articles aimed at capturing attention based on public interest and importance, rather than reflecting the true demand and facts for rare cancers, are rapidly circulating [23]. This trend could potentially exacerbate the information gap regarding rare cancers, leading to discrepancies in the volume, accuracy, and relevance of the information provided [24]. Furthermore, our network analysis revealed that when related keywords were connected, articles featuring celebrity gossip were more prevalent than those providing factual information. This underscores a significant limitation in the dissemination of information via internet articles
According to our findings, another significant keyword for 2023 was “childhood cancer.” This term was frequently associated with content that focused on celebrities’ donations to childhood cancer patients, highlighting public interest in such philanthropic acts. Additionally, there have been numerous discussions aimed at improving the medical system for children, particularly due to concerns about the shortage of dedicated personnel for childhood cancer. Despite the well-developed childhood cancer treatment environment in South Korea, the provinces face a significant lack of dedicated treatment facilities. Efforts are underway to address this issue, including proposals to establish a pediatric cancer base hospital in the region to facilitate the efficient formation of a pediatric cancer treatment team [25]. Thus, articles addressing these issues dominated the related content landscape.
News articles often feature content that is easily accessible and gossip-oriented, which differs from the information sought by the general public, including cancer patients. This discrepancy is also reflected in the deviation from keywords commonly used in online cafés frequented by cancer patients. This shift can be attributed to news outlets no longer merely delivering information, but rather engaging in the creation and dissemination of content to garner wider interest across various online platforms [26]. By examining the results of the network analysis, it becomes clear that when each node is clustered, the network centers around interest-inducing keywords such as new drug announcements and celebrity content. In other words, many articles received more clicks for their entertainment value than for the informative content they provided. The abundance of related articles indicates a strong public interest in these topics. However, mere interest does not guarantee accurate information, and caution is needed.
Additionally, the results reflect a substantial public interest in cancer-related keywords, particularly those that became significant issues in South Korea in 2023. Lung cancer has received heightened attention due to various concerns, including the health risks associated with humidifier disinfectants and the incidence of lung cancer among school cafeteria workers. Humidifier disinfectants, widely used in South Korean homes to inhibit microbial growth in humidifier tanks, have become controversial after studies showed that inhaling these chemicals could cause severe lung damage [27]. In 2023, public concern escalated when a potential link between these disinfectants and lung cancer was officially recognized. Additionally, exposure to cooking oil fumes generated from frying at high temperatures has been linked to lung cancer, highlighting occupational health risks. The issue of occupational lung cancer among school cafeteria workers has also gained considerable attention in South Korea [28]. Thus, lung cancer-related issues were prominent throughout 2023.
The frequent mention of certain cancer-related keywords in news articles on portal sites can often be linked to sociocultural factors, such as the well-publicized cancer struggles of celebrities and the recent discovery of carcinogens. In South Korean society, the public’s fascination with celebrities significantly influences their attitudes and behaviors, as people often experience a sense of connection and belonging through their perceived relationships with these public figures [29]. Moreover, the heightened exposure of socioeconomically disadvantaged groups to environmental carcinogens further increases the visibility of these issues [30]. The extensive media coverage of these topics indicates a growing public concern across different demographic groups. Analyzing the prevalence of these keywords offers valuable insights into the types of information that capture public attention, underscoring the urgent need for accurate and reliable health information dissemination to ensure effective public health communication.
This study has several limitations that highlight potential areas for further research. First, the data collection was confined to news articles from specific internet portals. However, by focusing on Naver, the leading portal site in Korea, we ensured broad coverage of major national issues. Additionally, this study was limited to news articles, which may have restricted the diversity of information sources. Future studies could broaden the scope by incorporating content from a wider range of platforms. It is important to note, however, that many online platforms, such as internet cafés, contain personal information, which could compromise data integrity. Therefore, the focus on news articles, which typically provide more objective cancer-related information, facilitates the extraction of valuable insights. Lastly, this research is limited to articles published in 2023. While some details may vary in subsequent years, the general trends identified are expected to remain relevant. Thus, this study provides important insights into cancer-related information consumption and serves as a foundation for future inquiries in this area.
This study identified patterns in the consumption of cancer-related information and highlighted topics of public interest through keyword analysis in 2023. The findings from this text mining analysis provide essential foundational data that can inform future policy directions and strategies, enabling a more proactive response to misinformation. The use of network analysis facilitated the identification of associations between keywords. Further research should focus on monitoring both emerging keywords and those frequently used in cancer-related content. Ultimately, this study underscores the importance of understanding the nature of cancer-related information consumed by the public and offers valuable insights that can guide official policies and healthcare practices.

 XML Download
XML Download