

 PDF
PDF Citation
Citation Print
Print



INTRODUCTION
According to the Diabetes Fact Sheet published by the Korean Diabetes Association in 2020, one in six Korean adults aged over 30 years (16.7%) and three out of 10 aged over 65 years (30.1%) had diabetes [1]. The pathophysiology of diabetes is explained by insulin resistance and a deterioration in the insulin secretory function of pancreatic β-cells [2]. Previous population-based prospective cohort studies have described their roles in the natural history of type 2 diabetes with different conclusions depending on races and measures of insulin resistance and insulin secretory functions [3]. The Whitehall II study, a prospective cohort of 6,538 civil servants (91% Caucasian) in the United Kingdom followed up for 13 years, reported that the group with initially high insulin resistance had significantly more diabetes than those with low insulin secretory function [4]. Similarly, a study of 94,952 Chinese individuals in a nationwide, population-based cohort showed that insulin resistance was more strongly associated with incident diabetes than β-cell dysfunction measured with homeostasis model assessment of β-cell function (HOMA-β) which was more prominent among adults with obesity [5]. In contrast, in East Asians, several prospective cohort studies of Koreans and Japanese individuals have concluded that the decrease in insulin secretory function, as measured by the insulinogenic index from oral glucose tolerance tests, contributes more to the incident diabetes than insulin resistance [6,7].
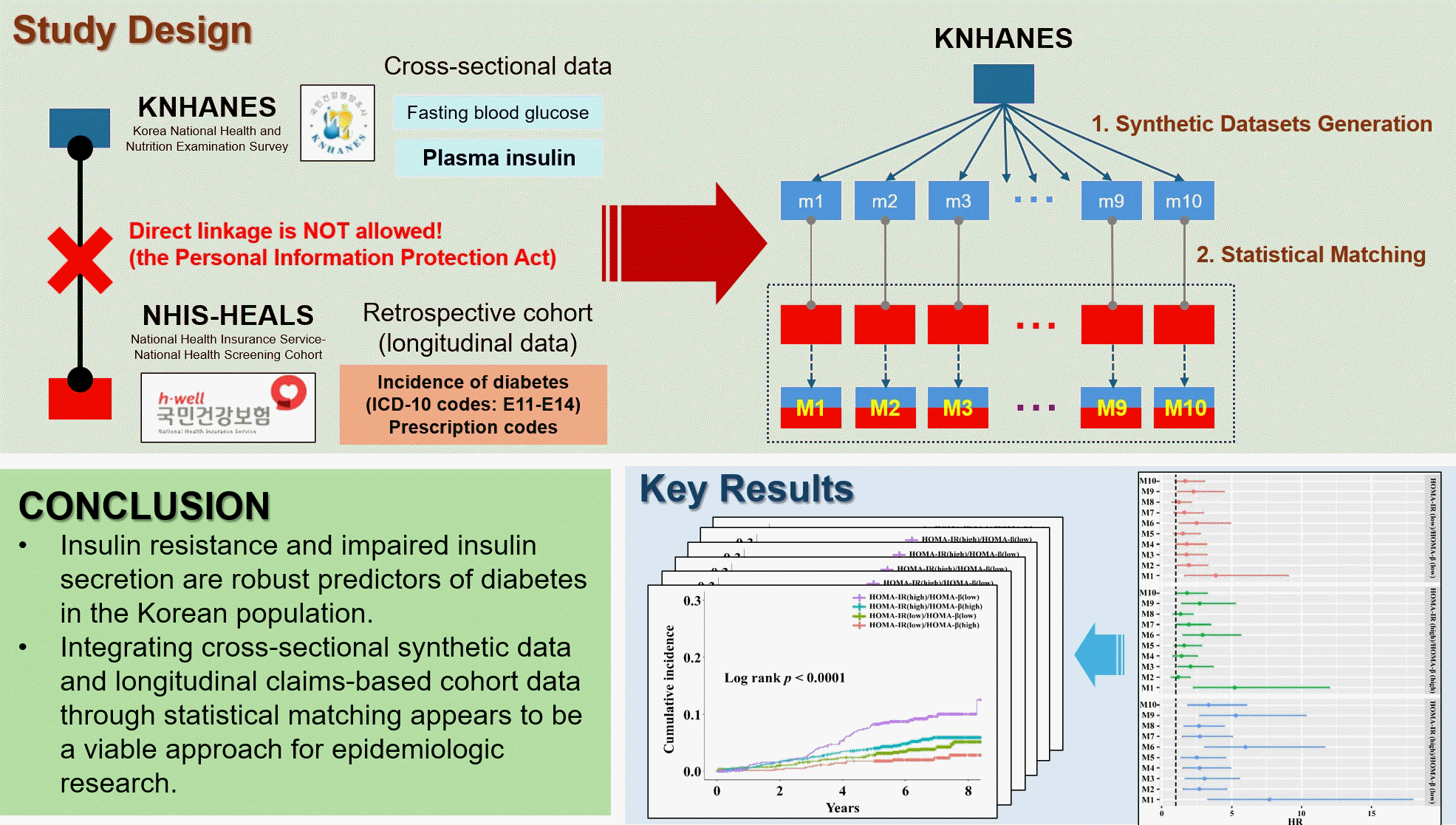
Prospective cohort studies on the pathophysiology of diabetes can yield results with strong evidence. However, establishing and maintaining large prospective cohort studies on diabetes is costly and time-consuming. The Korea National Health and Nutrition Examination Survey (KNHANES) is a complex, stratified, multistage probability-cluster survey used to obtain a representative sample of South Koreans. KNHANES includes several health examinations, such as medical history-taking, physical examination, administration of a questionnaire, and anthropometric and biochemical measurements. As these surveys were conducted by well-trained visiting medical staff, objective and precise results were achieved [8-10]. The National Health Insurance Service-National Health Screening Cohort (NHIS-HEALS) provides nationwide annual claims data, including prescription and diagnosis code information provided by specialists, which enables researchers to infer the incidence of a specific disease [11,12]. Diabetes incidence was extracted from the NHIS-HEALS using International Classification of Disease (ICD) code diagnosed by physicians, and plasma insulin and glucose levels were obtained from the KNHANES data. The nature of the cross-sectional KNHANES can be expanded upon by incorporating longitudinal outcomes into the NHIS-HEALS; however, owing to privacy issues, integrating two datasets with a direct identifier is very limited.
In the present study, synthetically generated KNHANES datasets were matched with NHIS-HEALS. To date, there have been a community-based longitudinal study and a nationwide cross-sectional study in Korea [6,13]. However, this is the first study to conduct a longitudinal analysis of diabetes occurrence using the nationwide population-representative cohorts. Also, we hypothesize that the statistically matched cohort could confirm epidemiologically relevant results, a combination of insulin resistance and insulin secretory increased risk of diabetes.
METHODS
Study participants
This study incorporated synthetic data from the KNHANES and NHIS-HEALS. KNHANES is a nationwide survey conducted annually by the Korea Centers for Disease Control and Prevention (KCDC) to investigate the health and nutritional status of the population. Data were obtained by proportional allocation systematic sampling with multistage stratification to achieve representativeness of the whole population. A professional survey team consisting of nurses, clinical pathologists, radiologists, nutritionists, and dentists investigated four areas every week, and each area was surveyed for 3 days via standardized mobile check-up vehicle visits. We chose the 2007–2010 and 2015 KNHANES years when insulin levels were measured.
The NHIS is the single health insurance provider in South Korea and covers the entire South Korean population. The NHIS-HEALS is a subpopulation of individuals who participated in the health screening programs provided by the NHIS. To construct the NHIS-HEALS database, a sample cohort from the 2002 and 2003 health screening participants aged between 40 and 79 years was first selected in 2002 and followed up until 2015. This cohort included 514,866 participants chosen randomly from 10% of all health screening participants in 2002 to 2003 [14]. NHIS-HEALS includes public data on healthcare utilization, such as disease diagnoses, drug prescriptions, interventions, medical procedures, and physical health examination results. All data were provided only for studies approved by the Institutional Review Board and were anonymized prior to assessment.
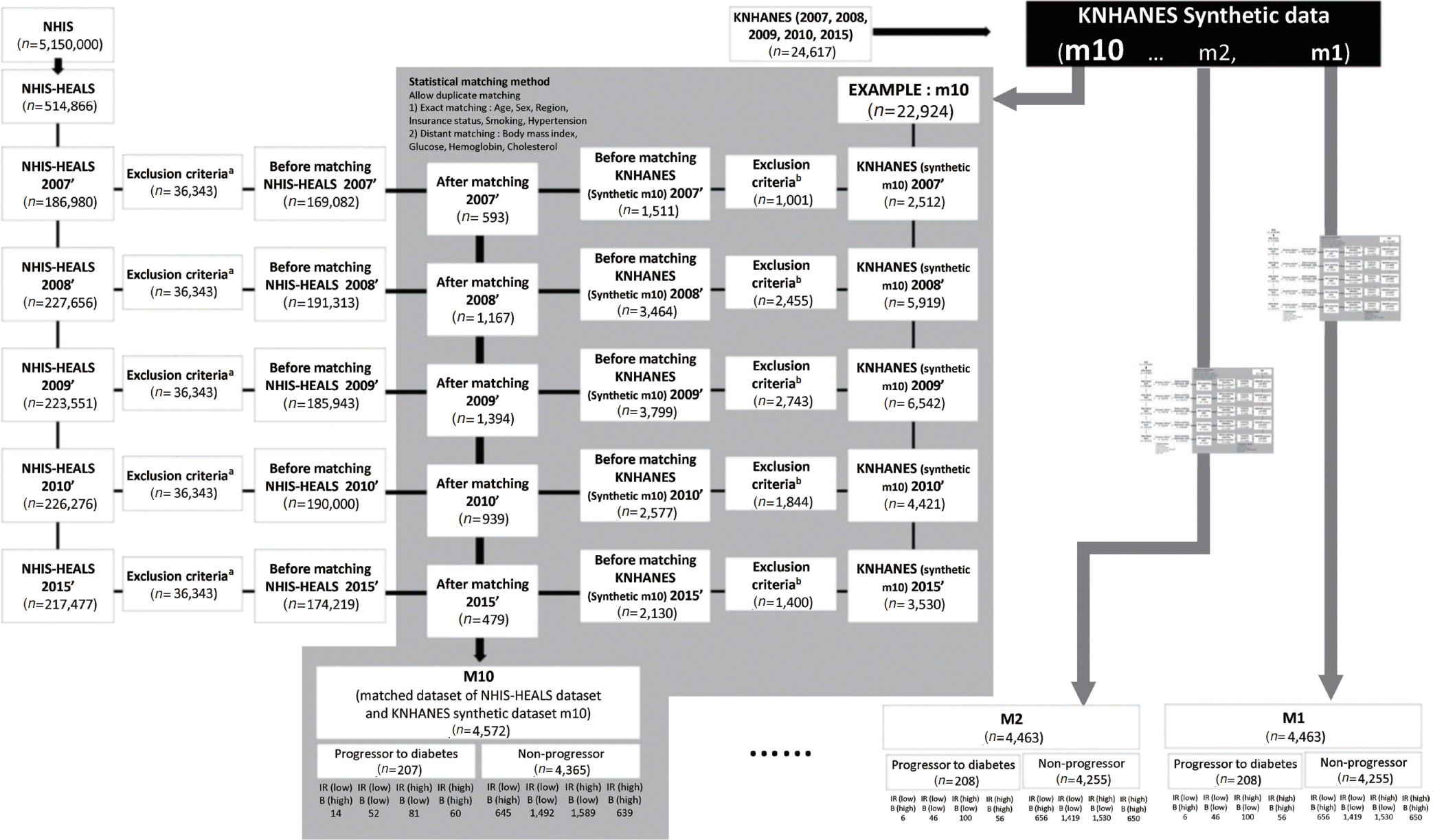
A total of 24,617 individuals from the KNHANES (for example, one synthetic dataset [m10] included 2,512 in 2007; 5,919 in 2008; 6,542 in 2009; 4,421 in 2010; and 3,530 in 2015) and 514,866 individuals from the NHIS-HEALS (186,980 examinees in 2007; 227,656 examinees in 2008; 223,551 examinees in 2009; 226,276 examinees in 2010; and 217,477 examinees in 2015) were investigated. As each individual surveyed in the KNHANES is likely to also participate in the NHIS survey as a South Korean citizen, we attempted to combine the KNHANES with the NHIS. However, due to the Personal Information Protection Act, it was impossible to both import KNHANES data into the data analysis center and establish a direct linkage. Consequently, we generated synthetic KNHANES data and constructed well-designed statistical matching to overcome these limitations. Participants from the same year as the NHIS-HEALS and KNHANES were matched to ensure high-quality matching. As the NHIS medical examination is conducted for those aged 40 years or older, participants aged over 40 were included. To exclude participants with diabetes at baseline, participants who exceeded a fasting glucose level of 126 mg/dL or had checked their previous diabetes history in the survey in both the NHIS-HEALS and KNHANES were excluded. Participants with missing data on the matching variables or medical beneficiaries were excluded. The flowchart shows details of the exclusion criteria (Fig. 1). Because the NHIS data includes tests that patients can undergo annually, duplicate data may occur; therefore, the previous year’s NHIS-KNHANES matched data were removed before the corresponding year’s matching.
This study excluded personal identification information, and the Institutional Review Board waived the requirement for informed consent. This study was approved by the Institutional Review Board of Seoul National University Bundang Hospital (IRB No. X-2004-608-905).
Matching variables
The variables used in matching were age, sex, residential area, smoking status, insurance type, hypertension, body mass index (BMI), hemoglobin, total cholesterol, and fasting glucose levels. Age was recorded based on the initial assessment year, but all ages ≥80 years were marked as 80 years old in the KNHANES; therefore, in the NHIS, those aged ≥80 years were also truncated as 80 years old before matching. Residential area was divided based on KNHANES, following 13-city code tables: Seoul, Busan, Daegu, Incheon, Gwangju, Daejeon, Ulsan, Gyeonggi, Gangwon, Chungcheong (Chungcheongbuk-do, Chungcheongnam-do, and Sejong city in NHIS city code were combined into Chungcheong), Jeolla (Jeollabuk-do and Jeollanam-do in NHIS city code were combined into Jeolla), Gyeongsang (Gyeongsangbuk-do and Gyeongsangnam-do in the NHIS city code were combined into Gyeongsang), and Jeju. Insurance types were divided into employment and local health insurance groups. Hypertension data were collected from the NHIS health examination history code table and KNHANES health interview questionnaire. Participants were considered current smokers, nonsmokers (having smoked less than 100 cigarettes in their lifetime), or past smokers, with smokers defined as both current and past smokers.
Height and weight were measured in the KNHANES health examinations to the nearest 0.1 cm and 0.1 kg, respectively, wearing light clothing and no shoes. BMI was calculated as weight in kilograms divided by the square of height in meters (kg/m2). Blood samples were collected from the antecubital vein of each participant in the morning after overnight fasting for at least 8 hours, processed, transferred in cold storage (2°C to 8℃) to the central laboratory of Neodin Medical Institute (Seoul, Korea), and analyzed within 24 hours. Fasting plasma glucose (FPG) measurements were performed using a Hitachi automatic analyzer 7600-210 (Hitachi Ltd., Tokyo, Japan).
Definition of incident diabetes mellitus
Data on incident diabetes were captured from the NHIS-HEALS database. As FPG, 2-hour postprandial plasma glucose from 75 g oral glucose tolerance test, or glycated hemoglobin (HbA1c), were not available, diabetes mellitus at NHIS-HEALS was defined by the combination of E11–14, ICD-10 codes for type 2 diabetes, and the use of medications for diabetes. The occurrence of diabetes was defined as a history of prescribing diabetes drugs, having more than two diabetes diagnoses (E10–14, ICD-10 codes) within the 90-day period, where any consecutive prescriptions occurred at least 28 days apart but no more than 1 year, and diagnosis cases other than E10 were included in at least one prescription to exclude type 1 diabetes cases. If multiple events were available, the date of the preceding event was designated as the date of diabetes occurrence.
Definition of HOMA-IR and HOMA-β
Fasting glucose and insulin levels in the KNHANES were used to measure insulin resistance and insulin secretion. Homeostasis model assessment of insulin resistance (HOMA-IR) and HOMA-β were calculated using the following formula [15]:
HOMA-IR=FPG (mg/dL)×fasting insulin (μU/mL)/405
HOMA-β=360×fasting insulin (μU/mL)/[FPG (mg/dL)–63].
We categorized the participants into four groups: low–HOMA-IR/high–HOMA-β, low–HOMA-IR/low–HOMA-β, high–HOMA-IR/high–HOMA-β, and high–HOMA-IR/low–HOMA-β using cutoff values of HOMA-IR (1.93) and HOMA-β (100.20) obtained as median values from the original KNHANES data collected between 2007–2010 and 2015.
Synthetic data generation and statistical matching
We generated synthetic data from the KNHANES for statistical matching with NHIS-HEALS. The concept of synthetic data generation is provided in Supplemental Fig. S1. A classification and regression tree method was applied to generate synthetic data. The following covariates were considered: year of examination; age; residential area; insurance type; smoking; hypertension; height; weight; BMI; waist circumference; hemoglobin, total cholesterol, HbA1c, fasting glucose, and insulin levels. The synthetic datasets were generated 10 times, with 23,741 records generated each time for the given covariates.
Both the KNHANES and the NHIS-HEALS were blocked into a combination of age, sex, residential area, insurance status, smoking, and hypertension, and records within each block were compared using Gower’s distance of the other continuous variables (BMI, fasting glucose, hemoglobin, and total cholesterol) to select nearest-neighbor 1-1 matched participant. To maximize the matching yield, we allowed unconstrained matching, where two or more participants in the NHIS-HEALS could match one participant in the KNHANES [16].
Statistical analysis
Data are presented as means with standard deviations, number (%), or hazard ratios (HRs) with 95% confidence intervals (CIs). We compared means using the Student t test and frequencies using chi-square tests for categorical variables. The Cox proportional hazards regression was used to estimate the adjusted HR (aHR) and 95% CI for the incidence of diabetes in three groups (low–HOMA-IR/low–HOMA-β, high–HOMA-IR/high– HOMA-β, and high–HOMA-IR/low–HOMA-β) relative to the low–HOMA-IR/high–HOMA-β groups. Data were adjusted for age, sex, systolic blood pressure, BMI, and cholesterol levels. All data were analyzed using R version 3.3 (R Foundation for Statistical Computing, Vienna, Austria). The ‘synthpop’ package for synthetic data generation and the ‘StatMatch’ package for statistical matching were used [17]. P values were two-tailed; those less than 0.05 were considered statistically significant.
RESULTS
Baseline characteristics of the study participants
A summary of the original data characteristics before and after matching is presented in Supplemental Tables S1, S2, respectively, corresponding to the synthetic datasets m1–m10 of the KNHANES and the NHIS-HEALS datasets. Characteristics of the original data after matching are presented to compare the baseline characteristics between the two groups (non-progressors and progressors to diabetes) in Table 1, Supplemental Table S3.
Among them, m10 data were chosen for the representative table for presentation purposes. In the M10 matched dataset, after synthetic KNHANES (m10)-NHIS-HEALS matching, diabetes developed in 207 (4.52%) of the 4,572 total participants; the mean follow-up duration was 5.8 years; age, hypertension, BMI, waist circumference, FPG, fasting insulin level, and HOMA-IR were significantly higher in the progressor to diabetes group than in the non-progressor group (Table 1). Similar results were observed for the remaining datasets (M1–M9, see Supplemental Table S3), indicating that the synthetic data shared a comparable distribution. In addition, higher hemoglobin levels (m2, m3, m6, m8, Supplemental Table S3), a higher proportion of smokers (m6–m8, Supplemental Table S3), and lower high-density lipoprotein cholesterol (HDL-C) levels (m2, m6, m8, Supplemental Table S3) were observed in the progressor to diabetes group. The m10 dataset showed no significant differences in sex, insurance, residence, smoking history, systolic and diastolic blood pressure, hemoglobin, total cholesterol, HDL-C, triglycerides, and HOMA-β levels.
Association between HOMA-IR/HOMA-β status and the risk for diabetes
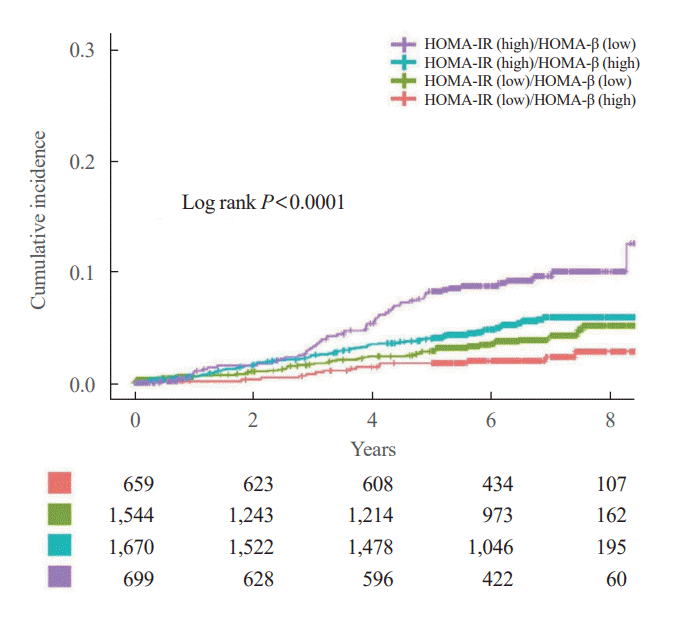
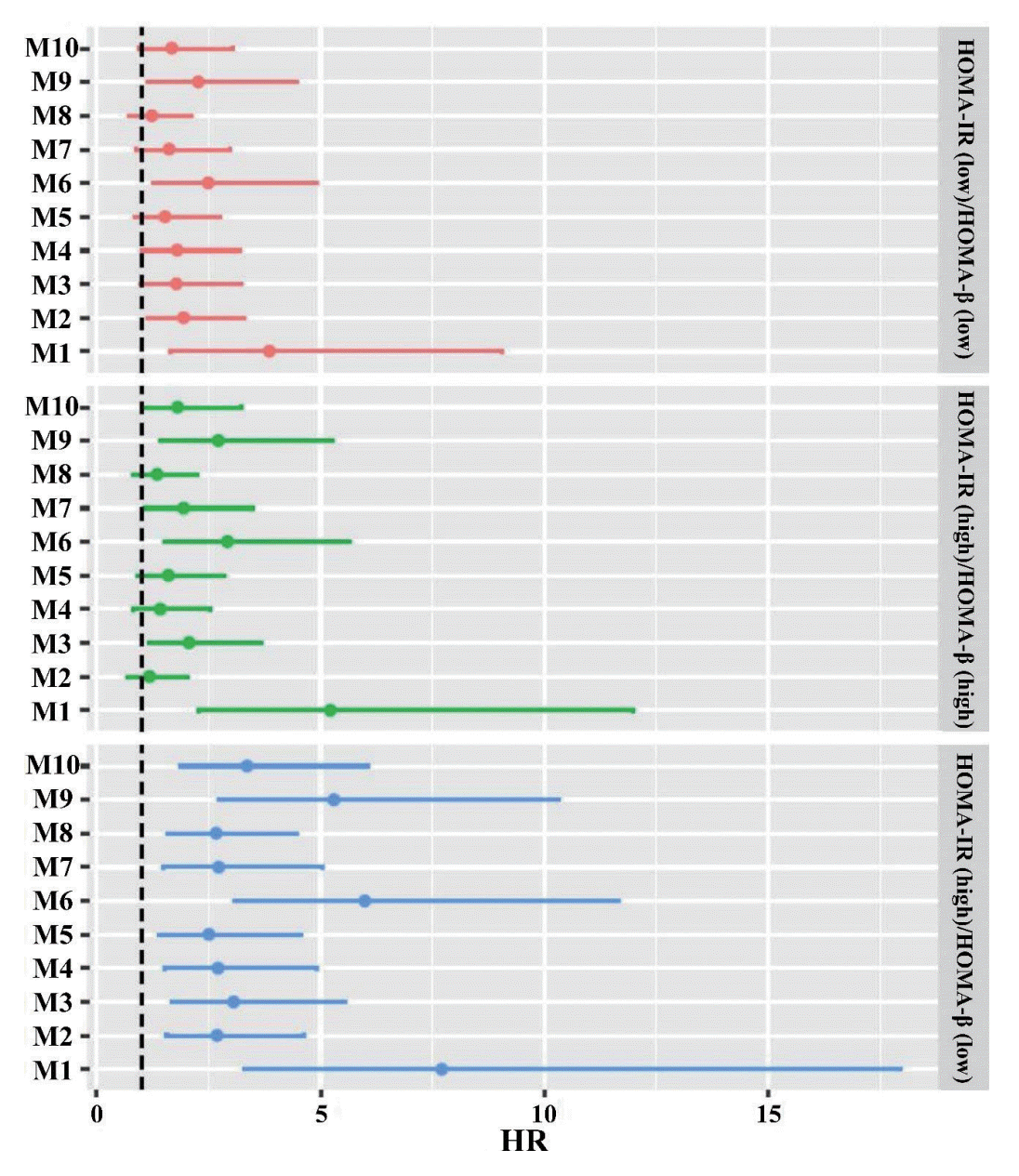
Next, we evaluated the risk of diabetes according to HOMA-IR and HOMA-β statuses using the 10 matched datasets (M1–M10) (Table 2, Supplemental Table S4). In the matched dataset of KNHANES synthetic dataset m10 and the NHIS-HEALS dataset, compared with the reference group (low–HOMA-IR/high–HOMA-β), the high–HOMA-IR/low–HOMA-β group showed the highest risk for diabetes (aHR, 3.36; 95% CI, 1.86 to 6.05) (Table 2), which is also observed in the remaining nine matched datasets (range of aHR, 2.67 to 7.71) (Supplemental Table S4). The high–HOMA-IR/high–HOMA-β group had an aHR of 1.81 (95% CI, 1.01 to 3.22), which was higher than that of the low–HOMA-IR/low–HOMA-β group (aHR, 1.68; 95% CI, 0.93 to 3.04) (Table 2). This trend was also evident in most of the remaining datasets, except for the two matched datasets (M2 and M4), which showed higher aHR in the low–HOMAIR/low–HOMA-β group than in the high–HOMA-IR/high– HOMA-β group (Supplemental Table S4). The Kaplan-Meier curves are presented in Fig. 2 (M10). In addition, forest plots of aHRs with 95% CIs for the 10 matched datasets are summarized in Fig. 3, Supplemental Fig. S2.
DISCUSSION
To the best of our knowledge, this is the first nationwide population-representative retrospective cohort study to investigate the contributions of insulin secretory function and insulin resistance to incident diabetes in the Korean population by generating synthetic data from the nationwide cross-sectional KNHANES and employing statistical matching with nationwide longitudinal claims data. Diabetes occurred in 4.5% of the participants over a mean follow-up of 5.8 years. This study, comprising properly generated synthetic data, revealed consistent trends across datasets for age, hypertension, BMI, waist circumference, FPG levels, and fasting insulin levels between progressors and non-progressors. In the 10 matched datasets, the high–HOMA-IR/low–HOMA-β group exhibited the highest risk compared to the reference group (low–HOMA-IR/high–HOMA-β group).
In the Asian population, where β-cell dysfunction is a predisposing metabolic disturbance, obesity-related insulin resistance that an increase in insulin secretion cannot offset is considered the pathogenesis of type 2 diabetes [18]. While the study observed a trend across the 10 datasets suggesting that both HOMA-β and HOMA-IR significantly impact the incidence of diabetes, the conclusion regarding the prioritization between the two was challenging. Out of 10 synthetic datasets, there were two datasets (M2 and M4) where aHR for incident diabetes was higher in low–HOMA-IR/low–HOMA-β than that in high– HOMA-IR/high–HOMA-β. Our study could not investigate the relative contribution of insulin resistance and insulin secretory function because regular follow-up data of HOMA-IR and HOMA-β were missing, and trajectory analyses of insulin resistance and insulin secretory function were not feasible.
Research using synthetic data has been employed in recent studies [19,20], which have been evaluated in various studies through classification models and have shown reliable results compared to real data [21,22]. Additionally, the evaluation of statistical matching methods remains an area of ongoing research. The adjusted HRs from the statistically matched datasets, which were the main outcome of this study, could be compared to those from the linked data using identifiers, such as ID, name, sex, and date of birth. In our study setting, because direct linkage of data was not possible, this concern could not be addressed. Nevertheless, the application of statistical matching using non-parametric methods to the synthetic data of KNHANES and NHIS-HEALS without identifiers did not show significant differences compared to previous research [23-25]. The resulting coefficients appear to be consistent, and our results are consistent with previous research findings, which supports the validity of our results. Research that uses synthetic data and statistical matching methods has implications for pilot studies. Analysis using synthetic data and statistical matching methods can yield novel and clinically significant findings. Although the supplementary analysis was conducted to demonstrate the consistency of plasma insulin values after synthetic data generation and statistical matching used in this study using the KNHANES dataset (Supplementary Fig. S3), which shows the consistency of insulin values despite the process of generating synthetic data and performing statistical matching, they should be validated by requesting direct data linkage using an identifier.
One of the strengths of our study lies in pioneering new approaches to big data research, particularly in overcoming privacy issues in the aggregation of nationwide big data. In South Korea, individuals can be uniquely identified through their resident registration numbers. Korea provides nationwide health insurance services to all citizens, meaning that the nation has accumulated high-quality health information for the entire population. Despite the capability to combine high-quality health data through resident registration numbers, stringent legal regulations exist at the national level, as defined by the “Personal Information Protection Act,” which prevent the unrestricted combination and linkage of data for various purposes, including research. These regulations are actively monitored by civic organizations, making it challenging to freely utilize such data for research purposes. The present study was conducted within the framework of these laws. Consequently, in accordance with South Korea’s Personal Information Protection Act, we could not directly analyze publicly available KNHANES data for data integration purposes. Instead, we analyzed it in the form of synthetic data. The generation of synthetic data is subject to physical constraints, limited to a closed server in specified locations, and extracting and exporting data is not straightforward within a restricted timeframe. Because we could use synthetic data without identifiers from the KNHANES, we attempted statistical matching between the NHIS and KNHANES synthetic datasets. Nevertheless, achieving consistent results with a certain trend holds significant meaning. In essence, synthetic data generation and matching, as in this study, can provide cost-effective and timely results while protecting personal information. This novel approach, which utilizes high-quality nationwide health insurance service data, has the potential to yield representative outcomes for the entire population, serving as an alternative to prospective cohort studies. In South Korea, only a limited number of public interest studies have undergone careful review, allowing for analysis using names and birthdates. In the case of analyzing two combined datasets in such a population, our statistical matching method, as employed in this study, could be used for validation through comparison. Validation studies may enhance the robustness of the research methodology.
Our study had several limitations. First, the study included participants with normal glucose tolerance and prediabetes but could not differentiate between the two groups due to the lack of 75 g oral glucose tolerance test data in the KNHANES. Therefore, we could not further investigate the predictive value of HOMA-IR and HOMA-β for incident diabetes in two distinct subgroups of normal glucose tolerance and prediabetes. The second limitation arose from the nature of the NHIS-HEALS dataset. The sample was drawn from individuals aged 40 years and older eligible for nationwide health check-ups. However, this approach may have limitations in addressing conditions, such as early-onset diabetes in younger individuals. Furthermore, due to the truncation of patients aged 80 years and above in the KNHANES datasets, there may be potential errors in calculating the average age. Third, as the definition of diabetes was not based on criteria set by the American Diabetes Association [26] or the World Health Organization but rather on diagnostic codes or prescription records in national claims data (NHIS-HEALS), the prevalence of diabetes could be underestimated because fasting, prandial plasma glucose, and HbA1c were not included in the definition of incident diabetes. Additionally, when excluding cases of previous diabetes mellitus from the KNHANES datasets, although all diabetes questionnaires were based on a standardized evaluation by experts, there remains the limitation of not using standard diagnostic criteria for diabetes. In this study, we were only allowed to access the data on the closed server for a limited period of up to 6 months. Due to this restricted access and the difficulty of reconstructing the data after it was deleted, we couldn’t perform subgroup analysis for high-risk populations (i.e., individuals with impaired fasting glucose [IFG]). Since individuals with IFG already experience compensatory changes in insulin resistance and insulin secretory function, HOMA-IR and HOMA-β may not provide additional predictive benefits for the future development of diabetes. Therefore, further studies are needed to clarify this issue. Moreover, we used HOMA-IR as an indicator of insulin resistance and HOMA-β as an indicator of insulin secretion. From the limitation of HOMA indices as surrogate measures of insulin resistance and β-cell function, these findings should be interpreted with caution [27,28]. Lastly, this research encountered constraints due to the unavailability of the primary data in the analysis laboratory, resulting in the generation of synthetic data for examination on a closed server within a limited timeframe. Nevertheless, there is a substantial demand for methodologies similar to ours. This study, centered on meeting these demands, makes a noteworthy contribution by implementing synthetic data and statistical matching in authentic clinical research.
In conclusion, our study on the Korean population confirmed that both insulin resistance and impaired insulin secretory function are crucial factors in the development of diabetes. Furthermore, non-identifying statistical matching with synthetic data produced similar results and trends even without using key identifiers, indicating the potential efficacy of non-identifying statistical matching. Hence, synthetic data generation and integration of these two large datasets is expected to become a reliable method in diabetes research. Continuous validation and supplementary studies are required to further enhance and refine this approach.
 XML Download
XML Download