

 PDF
PDF Citation
Citation Print
Print



We sincerely appreciate the insightful suggestions and comments provided by Dr. Bo Mi Seo and Dr. Jong Wook Choi on our manuscript [1]. We have reviewed Dr. Choi’s publications on diabetic kidney disease (DKD), and are impressed by his extensive expertise in this field. We are grateful to the Diabetes & Metabolism Journal for facilitating this valuable discussion on our paper published in Diabetes & Metabolism Journal. It is an excellent opportunity for learning and communication.
Deep learning enables machines to autonomously identify and rank features based on their significance. Although factors may associated DKD, their informational value might be subsumed by others, more salient features. During model training, factors with insufficient predictive power, due to competition with more critical factors, may not be selected as significant by the model. We have selected only the top 20 features with the highest weights for DKD prediction. This approach is grounded in the principle that predictive tools benefit from data simplicity while still ensuring optimal predictive performance.
To ensure that our data collection included as many predictors of DKD as possible, we conducted a systematic review of DKD risk/predictive factors. Nonetheless, it is inherent in such reviews that some factors may be omitted. Despite this, our deep learning model was trained with a diverse set of data, encompassing not only the predictors derived from the systematic review, but also additional variables such as patient demographics (e.g., gender, educational attainment, and income), and clinical measurements (e.g., white blood cell count, platelet count, hemoglobin levels, comprehensive liver function tests, and lipid profiles). The model assessed the importance of various predictors based on their computed weights, with gender not emerging as a significant feature.
The model was specifically developed for application to Chinese or Asian diabetes patients. Given the predominance of East Asian individuals in China and the challenges associated with obtaining extensive data from other ethnic groups, such as Black or White populations, these groups were not included in the initial model development. However, we appreciate the feedback from Dr. Choi and Dr. Seo. We plan to conduct external validation and application of the model in regions with diverse ethnic minorities within China.
Large-scale cross-sectional studies have identified associations between aspartate transaminase (AST)/alanine transaminase (ALT) ratios [2] and platelet counts [3] with DKD. Although our model included AST, ALT, and platelet data, these factors were not selected by the machine learning algorithm as significant predictors. Similarly, the usage of antidiabetic, antihypertensive, and lipid-lowering medications was incorporated into the training dataset, but none of these medications were identified as important features by the model. While individual medications may indeed influence the development of DKD, their weights in the model are lighter compared to more critical factors such as serum creatinine (SCr), high-density lipoprotein cholesterol, low-density lipoprotein cholesterol, disease duration, and age. This does not imply that these medications lack relevance to DKD; rather, it reflects their comparatively lower predictive significance within the context of our model.
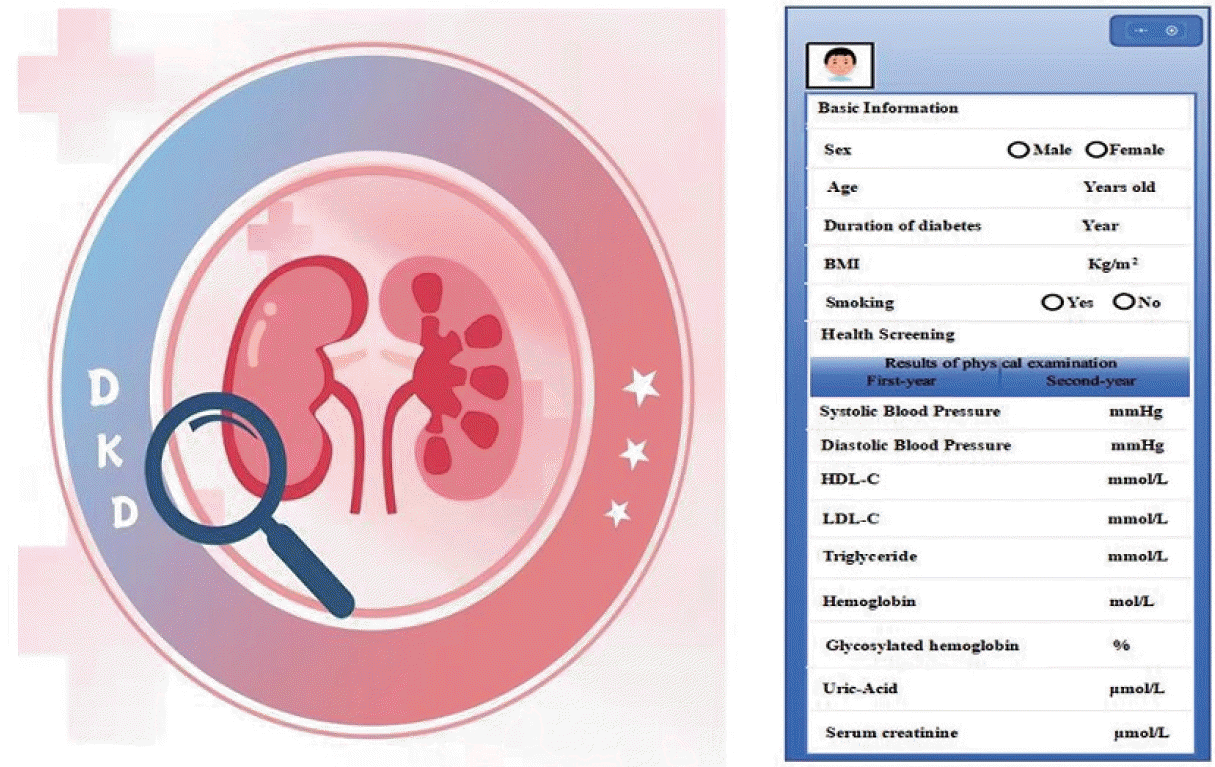
In our study, we evaluated only the long short term memory (LSTM) model and the support vector machine (SVM) due to the superior predictive capabilities of deep learning models in disease diagnosis [4,5] and prognosis [6,7] compared to traditional machine learning approaches (such as random forests, decision trees, SVM, and Bayesian methods). The consensus within the field is that deep learning models generally outperform conventional machine learning models. As pointed by Seo et al., studies reported that CatBoost Classifier and Gradient Boosted Tree (GBDT) demonstrate strong accuracy and area under the curve (AUC) performance [8,9]. In collaboration with an information technology (IT) firm, we developed models using Light Gradient Boosting Machine (LightGBM) and CatBoost Classifier—both enhancements of GBDT in 2023. We also excluded that with less than 7 years of follow-up for model training and testing. Finally, the LightGBM model exhibited the best predictive performance. Consequently, we have developed the LightGBM model into a Mini Program, a clinical application tool, as illustrated in Fig. 1.
Due to the structure of the healthcare system in mainland China, many diabetes patients do not do regular follow-up or monitor their glycosylated hemoglobin (HbA1c), estimated glomerular filtration rate (eGFR) or urine protein-creatinine ratio (UACR). Patients often seek medical attention only when experiencing significant symptoms or when their medication is depleted, and they may not consistently visit the same healthcare facility due to the flexibility in choosing among various hospitals. This situation complicates the collection of continuous data. A study from Chongqing revealed that annual proportions of HbA1c testing, blood lipid testing, and screenings for nephropathy and eye conditions were 8%, 54%, 45%, and 44%, respectively [10]. Another national cross-sectional survey conducted in China indicated that the rates of UACR, eGFR, and HbA1c testing among Chinese patients with type 2 diabetes mellitus (T2DM) were notably low, with only 21.12% of patients having HbA1c measured semi-annually and 13.11% and 9.34% undergoing UACR and eGFR tests annually, respectively [11]. Consequently, collecting continuous, 7-year datasets encompassing a range of DKD risk factors proves challenging. To ensure the robustness of our model, we utilized data from the Li’s United Clinics in Taiwan for model training. This choice is a limitation of our study; however, it can be mitigated through independent external validation. Independent external validation involves assessing the model using data from different sources or researchers not involved in the original model development [12], which is crucial for evaluating the model’s reliability. Such validation is necessary to confirm the model’s stability and generalizability, thereby enhancing its credibility for clinical use [12,13].
To assess the stability and generalizability of the model, we initially intended to conduct independent external validation using data from 800 cases across five hospitals in mainland China. Unfortunately, three of these hospitals had updated their electronic madical system within the past 7 years, preventing us from acquiring continuous longitudinal data. As a result, we obtained data from the remaining two hospitals, located in Zhejiang Province and Hainan Province, and collected a dataset comprising 488 cases with continuous records spanning 7 years. We used the initial 2 years of this data to predict the incidence of DKD over the following 5 years. The LightGBM model was then validated using this dataset, achieving an accuracy of 0.94, precision of 0.88, recall of 0.87, F1 score of 0.91, and an AUC of 0.85. These results indicate strong performance of the model among patients with T2DM in mainland China. Furthermore, the top 20 predictive features identified by the LightGBM model differed significantly from those of the original LSTM model. Detailed information on the key features and their weights used in the LightGBM model for DKD prediction is provided in Table 1.
We extend our sincere gratitude to Dr. Choi and Dr. Seo for their valuable input regarding the variability of SCr, an aspect we had not previously considered. We have now computed the variability of SCr and integrated this data into the model and found that SCr variability is an important feature in predicting DKD.
To enhance the robustness of our model, we plan to increase the sample size by incorporating data from two to three additional hospitals in mainland China that offer continuous 7-year follow-up records for patients with T2DM. This will allow us to conduct further independent external validation and apply the model to diverse patient populations, including ethnic minorities.
The development and refinement of predictive models is a dynamic and iterative process. As deep learning technologies advance, new and superior neural networks will continuously emerge. It is crucial for clinicians to engage in ongoing collaboration with IT specialists to optimize model performance. Additionally, successful model development is only the initial step; to facilitate clinical application, further efforts are required, including the creation of user-friendly platforms such as mobile applications or software tools.
 XML Download
XML Download