

 PDF
PDF Citation
Citation Print
Print


INTRODUCTION
The rapid advancement of generative artificial intelligence (AI) is transforming the landscape of scientific research and academic writing [1]. Large language models (LLMs), such as ChatGPT, Claude, Copilot and Gemini, have demonstrated remarkable capabilities in understanding and generating human-like text. These models are trained on vast amounts of data, allowing them to assist researchers with various tasks, from literature analysis and content generation to language translation and also peer review and publication processes [2,3]. The rapid improvements in model algorithms and the increasing computational power dedicated to running these models are outpacing Moore's Law [4]. As these LLMs are becoming more sophisticated and prevalent in academic publishing, its implications for research integrity and establishing appropriate policies and guidelines has become increasingly important.
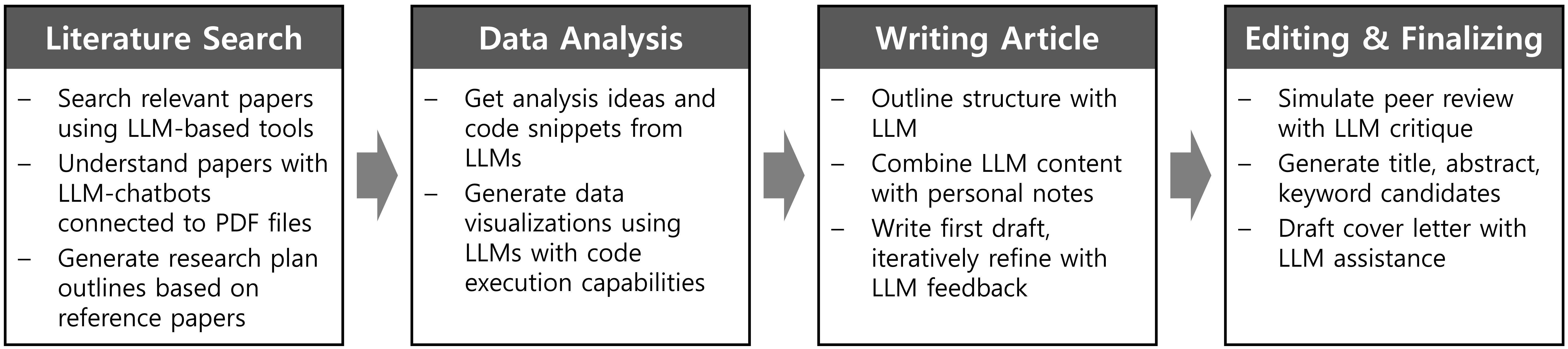
As LLMs become increasingly integrated into the research and writing process (Fig. 1), concerns have arisen regarding the quality, accuracy, and transparency of AI-generated content [5]. The scientific community has engaged in debates about the appropriate use of these tools, particularly in light of incidents such as the listing of ChatGPT as an author [6]. Despite the rapid adoption of LLMs, a recent study found that only 18% of the top 100 Korean medical journals had explicit policies addressing their use as of March 2024 [7]. This lack of clear guidelines highlights the need for the scientific community to develop well-defined, realistic, and coherent policies that promote the responsible and productive integration of AI in academic endeavors [8].
The aim of this review article is to provide a comprehensive overview of the current state of LLMs in medical writing and publishing, focusing on experimental evidence rather than perspective papers. By examining the actual capabilities and limitations of these tools, as well as the ethical considerations surrounding their use, this review seeks to inform policy decisions and guide the responsible integration of LLMs in research. The article will explore the applications of LLMs in various stages of the research process, including literature analysis, content generation, and peer review. Additionally, recommendations for researchers, reviewers, and editorial offices will be provided to ensure the integrity and quality of AI-assisted academic work.
PREVALENCE OF LLM USAGE IN SCIENTIFIC WRITING
Global surveys on LLM use in academia
The use of LLMs has become increasingly prevalent in academia, particularly in biomedical and clinical sciences [9]. A global survey conducted by Nature in July 2023 found that about one-third (31%) of postdoc respondents reported using AI chatbots for tasks such as refining text, generating or editing code, and managing literature in their fields [10]. Similarly, a global survey of 456 urologists in May 2023 revealed that 47.7% use LLMs [11]. There has been a significant increase in the suspected use of LLMs for writing articles submitted to an orthopedic journal, with 41.0% of articles having suspected AI use over 10% [12]. The median probability of AI-generated abstracts increased from 3.8% to 5.7% in 2022 and 2023 across Q1 journals in medical imaging [13]. Moreover, evidence of AI use in reviews was found in a study of AI conference peer reviews that took place after the release of ChatGPT, suggesting that between 6.5% and 16.9% of reviews have been substantially modified by LLMs [14].
Potential benefits and challenges of LLM usage in academic writing
The use of LLM tools in academic writing has been associated with perceived benefits and efficiency gains in the research and writing process [10]. A quantitative study found that incorporating ChatGPT into the workflow for professional writing tasks reduced the average time taken by 40% and increased output quality by 18% [15]. This potential for increased productivity and output quality has been a driving factor in the adoption of LLMs, especially given the growing pressure on researchers to increase their research productivity and output [16].
However, the ease with which LLMs can generate convincing academic content has raised concerns about the potential for misuse and fraud. One study demonstrated that GPT-3 can create a highly convincing fraudulent article resembling a genuine scientific paper in terms of word usage, sentence structure, and overall composition, all within just 1 h and without any special training of the user [17]. Similarly, another study in early 2023 used ChatGPT-4 to generate 2 fake orthopedic surgery papers, with one passing review and being accepted, and the other being rejected but referred to another journal for consideration [18].
The challenges in detecting AI-generated content further complicate the issue. In a study where ChatGPT-3.5 generated 50 fake research abstracts from titles, only 8% met specific formatting criteria, yet achieved a 100% originality score in plagiarism detectors [19]. While AI detectors identified them as AI-created, human reviewers correctly spotted only 68% as AI-crafted and mistakenly tagged 14% of original abstracts as such. This highlights the nuanced challenges and considerations in integrating AI into academic writing while upholding scientific rigor.
The lack of unified guidelines and unclear policies regarding the extent of AI tool usage considered acceptable has left researchers in a state of uncertainty [8]. The term "use of AI" encompasses a wide spectrum of applications, ranging from providing a keyword to generate an entire manuscript, listing items to be mentioned and converting them into paragraphs, or strictly using AI for typo and punctuation correction only. The difficulty in detecting AI-generated content and the high risk of false-positives, especially for non-native English writing, further compound the issue [20]. The varying results of LLM usage rates in studies from the previous section underscore the challenges in detection and the need for more robust and standardized methods.
APPLICATIONS IN RESEARCH AND WRITING
Literature search and research design
AI tools have demonstrated potential in assisting researchers with literature searches and systematic reviews (Table 1). For instance, ChatGPT-3.5 and ChatGPT-4 were used to generate PICO-based search queries in the field of orthodontics, showcasing their ability to aid the systematic review process [21]. In another study, ChatGPT-3.5 was employed to generate 50 topics in medical research and create a research protocol for each topic, with an 84% accuracy rate of references [22]. Additionally, ChatGPT-4 was used to analyze 2,491 abstracts published in European Resuscitation Council conferences, highlighting its capabilities in bibliometric analysis of academic abstracts and its potential impact on academic writing and publishing [23].
Writing assistance and quality assessment
LLMs have been extensively applied in various aspects of writing assistance, particularly in abstract generation (Table 1). ChatGPT-3.5 demonstrated the ability to generate high-quality abstracts from clinical trial keywords and data tables, showcasing impressive accuracy with minor errors [24]. However, its performance varied significantly when tasked with writing abstracts on broad, well-documented topics compared to more specific, recently published subjects [25]. The low plagiarism scores and difficult detection of AI-generated abstracts and the ethical boundaries of using such technology in academic writing have also been discussed [19]. Although ChatGPT-3.5 could generate abstracts that were challenging to distinguish from human-written ones in the arthroplasty field, the quality was notably better in those written by humans [26]. Using both ChatGPT-3.5 and ChatGPT-4 to write abstracts for randomized controlled trials revealed that, despite their potential, the quality was not satisfactory, highlighting the need for further development and refinement in generative AI tools [27].
In addition to abstract generation, LLMs have been used to assist in various other writing tasks. For example, GPT-4 was used to generate introduction sections for randomized controlled trials, with non-inferiority confirmed and higher readability scores compared to human-written introductions [28]. ChatGPT was also used to write medical case reports [29] and to write a clinical summary containing patient situation, case evaluation and appropriate interventions [30]. In a study regarding human reproduction, ChatGPT could produce high-quality text and efficiently summarize information, but its ability to interpret data and answer scientific questions was limited [31].
LLMs have been employed to generate cover letters for abstracts, with non-inferiority confirmed by randomized trials and higher readability scores [32]. These tools have also been used to facilitate language learning and improve technical writing skills for non-native English speakers, which is particularly meaningful for scholars using English as a non-primary language [33]. However, it is important to note that the effectiveness of these tools may vary, as one study found that the free version of ChatGPT-3.5 was not an effective writing coach [34]. Interestingly, fine-tuning a language model to an author's previous works can also enhance academic writing, especially for generating text and ideas related to the scholar's prior work, offering a personalized approach to writing assistance [35].
Citation and reference generation
Citation and reference generation is another area where LLMs have been applied, albeit with varying levels of success (Table 1). In a study conducted in early 2023, researchers generated 50 references for 10 common topic keywords relevant to head and neck surgery, finding that only 10% of the generated references were accurate [36]. However, in a study comparing the performance between multiple LLM-based tools, ChatGPT-3.5 outperformed Bing Chat (old version of Microsoft Copilot) and Google Bard (old version of Google Gemini) with a 38% accuracy rate in nephrology reference generation [37]. ChatGPT-4 showed substantial improvements, achieving a 74.3% correct reference rate for otolaryngology topics [38] and a high accuracy rate ranging from 73% to 87% for generating full citations of the most cited otolaryngology papers [39].
Despite these advancements, the lack of a fact-checking step in the text generation algorithms of LLMs leads to inherent inaccuracies in reference generation, suggesting that incorporating techniques such as retrieval-augmented generation is crucial to enhance reliability [40]. Specific tools tailored for article search, such as Perplexity, Elicit and Consensus can be used instead of LLM chatbots for general purpose. These tools analyze the researcher's input using LLMs and retrieve related articles from a scholarly database, thereby reducing the likelihood of generating non-existent references. A tutorial on how to utilize LLM-based tools for each stage of article writing is provided in Supplementary Data 1.
Code generation and data analysis
LLMs have shown promise in code generation and data analysis, potentially impacting life sciences education and research by allowing researchers to collaborate with such models to produce functional code [41]. For example, ChatGPT-4 was tested to build two cancer economic models, demonstrating that AI can automate health economic model construction, potentially accelerating development timelines and reducing costs [42]. Furthermore, the Code Interpreter feature in ChatGPT allows users to upload data files and ask the chatbot to perform data analysis using natural language interactions. The chatbot can read the data, plan steps for data analysis, write python code to perform the analysis, and visualize the results, effectively democratizing bioinformatics by breaking down the barrier of code writing [43,44]. These advancements suggest that when integrated with tools, LLMs have the potential to revolutionize the way researchers approach code generation and data analysis in science, making these processes more accessible, efficient, and cost-effective (Table 1).
Automation of scientific discovery
Recent advancements in LLMs have demonstrated their potential to automate and accelerate scientific discovery across various domains. An approach for automatically generating and testing social scientific hypotheses using LLMs and structural causal models has been introduced [45]. This method enables the proposal and testing of causal relationships in simulated social interactions, providing insights that are not directly available through LLM elicitation alone. In the field of mathematics, an evolutionary procedure called FunSearch has been developed, which pairs a pretrained LLM with a systematic evaluator to surpass best-known results in complex problems [46]. Applying FunSearch to the cap set problem in extremal combinatorics led to the discovery of new constructions of large cap sets, pushing the boundaries of existing LLM-based approaches.
Moreover, an AI system driven by GPT-4, named Coscientist, has been showcased to autonomously design, plan, and perform complex experiments in chemistry [47]. Coscientist successfully optimized palladium-catalyzed cross-couplings, demonstrating the versatility and efficacy of AI systems in advancing research. These examples highlight the transformative potential of LLMs in automating and accelerating scientific discovery across various disciplines, from social sciences and mathematics to chemistry. As LLMs continue to evolve and become more sophisticated, their impact on research and scientific discovery is expected to grow, potentially revolutionizing the way researchers approach complex problems and accelerating the pace of innovation across multiple fields.
APPLICATIONS IN PEER REVIEW AND PUBLICATION
Manuscript screening and quality assessment
LLMs have shown potential in assisting with manuscript screening and quality assessment (Table 2). Studies have demonstrated their effectiveness in proofreading and error detection [48], as well as predicting peer review outcomes [49]. LLMs can also be used to assess the quality and risk of bias in systematic reviews [50] and develop grading systems for evaluating methodology sections [51]. These applications could be particularly beneficial for researchers from underprivileged regions who may lack access to timely and quality feedback mechanisms [52].
Generating review comments and feedback
LLMs can assist reviewers in generating opinions and comments on manuscripts, potentially reducing reviewer fatigue and streamlining the peer review process [53]. A large-scale retrospective study comparing GPT-4 generated comments with human reviews found that AI-generated comments had a 31%–39% overlap with human reviewers, while inter-human overlap was 29%–35% [54]. Additionally, a prospective study revealed that 70% of scholars found AI comments to have at least partial alignment with human reviews, and 20% found AI feedback more helpful than human comments [54].
However, a relatively small study using 21 research papers and having 2 human reviewers and AI to give review comments showed that while ChatGPT-3.5 and ChatGPT-4.0 demonstrated good concordance with accepted papers, they provided overly positive reviews for rejected papers [55]. While these limitations should be acknowledged, the overall evidence suggests that LLMs hold great promise in revolutionizing the peer review process by generating valuable insights and reducing the workload of human reviewers, leading to a more efficient and comprehensive evaluation of manuscripts in the era of review shortage (Table 2) [56].
Potential biases and limitations in AI-assisted peer review
Despite the promising applications of LLMs in peer review, it is crucial to be aware of potential biases and limitations (Table 2). Studies have identified gender bias in LLM-generated recommendation letters [57], as well as biases related to nationality, culture, and demographics [58]. The overreliance on LLMs in peer review may lead to linguistic compression and reduced epistemic diversity, an essential element for the advancement of science [54]. Furthermore, LLMs may lack deep domain knowledge, especially in medical fields and may fail to detect minute errors in specific details [59,60]. To mitigate these issues, human oversight and final decision-making remain essential in the peer review process.
Editorial office applications
LLMs can be employed in various editorial office applications to manage submissions, detect plagiarism, and disseminate research findings (Table 2). AI-assisted tools can be used to prescreen manuscripts for quality and suitability, provide initial screening results to reviewers, and develop automated reviewer recommendation systems based on expertise. High-level plagiarism checks can be performed using LLMs, and can also help identify and address ethical issues.
To engage readers and promote broader dissemination of research, generative AI tools can generate plain language summaries, graphical abstracts, and personalized content recommendations. These tools can help break down complex scientific concepts into easily understandable language, making research findings more accessible to a wider audience with varying levels of scientific knowledge. Moreover, LLM-powered translation tools can help overcome language barriers by providing accurate translations of research articles, abstracts, and summaries, enabling the dissemination of scientific knowledge across different languages and cultures. This increased accessibility and reach can foster greater public engagement with science and facilitate interdisciplinary collaborations. As a demonstration of this application, the Chatbot Claude 3 Opus was provided with the abstracts of the recent issue of The Korean Journal of Physiology & Pharmacology (Volume 28 Number 3), and has been prompted to write both an editorial review article (Supplementary Data 2) and a plain language summary article in English and Korean (Supplementary Data 3).
However, it is important to consider data privacy concerns, such as the potential for manuscripts to unintentionally become training data for language models if proper precautions are not taken [8]. As LLMs continue to advance, its integration into the peer review and publication process is expected to grow. However, it is essential for the academic community to establish clear guidelines and best practices to ensure the responsible and ethical use of these tools, while maintaining the integrity and quality of scholarly publishing.
RECOMMENDATIONS FOR RESPONSIBLE LLM USE IN MEDICAL WRITING
Recommendations for researchers
To ensure the responsible use of LLMs in medical writing, researchers should prioritize verifying the accuracy and reliability of LLM-generated content. A recent study on GPT-4V, a state-of-the-art LLM, highlights the challenges in this domain [61]. While GPT-4V outperformed human physicians in multi-choice accuracy on the New England Journal of Medicine (NEJM) Image Challenges, it frequently presented flawed rationales even when the answer was correct. This underscores the need for thorough fact-checking and cross-referencing with reliable sources, as well as being cognizant of subtle errors or inconsistencies that can be challenging to detect, especially in the medical context.
In terms of enhancing the research capabilities of individual researchers, it is recommended to utilize AI to generate advice or thought-provoking questions rather than to generate answers [62]. For instance, instead of asking the LLM chatbot to generate a manuscript from an outline or list of ideas, it is more beneficial to request guidance and explanations on how to improve a manually crafted draft. Considering that a scientific article holds value as an author's writing, the choice of words or expressions may be an integral part of its identity and possess unique value.
Maintaining transparency in the use of LLMs is crucial, and researchers should disclose the use of these tools in the research and writing process, providing details on the extent and nature of LLM assistance. Developing a collaborative human-AI workflow that leverages LLM's strengths while recognizing their limitations can help optimize the quality of the output. Researchers should iteratively work with LLMs and ensure proper human intervention and oversight in each step [7].
Recommendations for reviewers
As LLMs become increasingly integrated into both the writing and review processes, and as AI tools can effectively screen for trivial errors such as grammar and formatting, reviewers should shift their focus to higher-order reviewing skills. This includes critically analyzing the overall significance, novelty, and impact of the work, providing nuanced feedback and domain-specific insights, and focusing on the "human" aspects of review [54]. It is important to note that while poor writing quality was previously associated with poor scientific quality, in the era of LLMs, the quality of writing may not necessarily reflect the scientific rigor of the work. Reviewers may also inevitably incorporate LLM-based tools in the peer review workflow, but need to keep in mind that proper vigilance is needed. There is evidence that in cases of overreliance, high-performance AI tools result in worse outcomes than low-performance AI tools with proper human stewardship [63]. Reviewers should be aware of the potential use of LLMs in manuscripts and ensure that conclusions are well-supported by data and analysis, rather than "hallucinated" claims. In cases of suspected unethical AI use, such as plagiarism or undisclosed LLM assistance, reviewers should act according to established reporting procedures and guidelines.
Recommendations for editorial offices
Editorial offices play a crucial role in promoting responsible LLM use in academic writing. Rather than banning AI based on fear, editorial offices should experience the capabilities of LLMs firsthand and develop evidence-based policies and guidelines that align with international standards (e.g., ICMJE, COPE, WAME). These policies should address key components such as AI authorship, disclosure of AI use, and human author responsibility [64]. Implementing robust screening and detection tools while embracing new technology and maintaining rigorous peer review standards is also important [65]. Editorial offices should acknowledge the prevalence of LLM use and focus on content quality and integrity. Providing training and resources for editorial staff and reviewers can help them navigate the challenges and opportunities presented by LLM technology.
Fostering open dialogue and collaboration within the academic community is another key responsibility of editorial offices. This can be achieved by promoting the exchange of ideas and experiences related to LLM use across different fields and disciplines, organizing workshops, seminars, or conferences to discuss challenges and opportunities, and engaging with AI researchers and developers to better understand LLM capabilities and limitations.
CONCLUSION
The rapid adoption and integration of LLMs in various stages of research and publishing have signaled a growing impact on academic writing and publishing. While LLMs offer potential benefits, they also present challenges for researchers, reviewers, and editorial offices. To harness the transformative potential of AI while maintaining the integrity of scholarly work, it is crucial to establish clear policies and guidelines that promote responsible and transparent use, fostering a culture of transparency and accountability, and encouraging open dialogue within the academic community. Future directions should focus on addressing the limitations and biases of current generative AI technologies, exploring innovative applications of LLMs, and continuously updating policies and practices. Collaborative efforts among researchers, reviewers, editorial offices, and AI developers will be essential in navigating the challenges and opportunities presented by LLMs. Ultimately, while embracing the potential of LLMs, it is important to prioritize the integrity of academic writing and publishing, emphasizing the importance of human judgment and expertise in the era of AI-assisted research and publishing.
SUPPLEMENTARY MATERIALS
Three supplementary data can be found with this article online at https://doi.org/10.4196/kjpp.2024.28.5.393
 XML Download
XML Download