1. Singer M, Deutschman CS, Seymour CW, Shankar-Hari M, Annane D, Bauer M, et al. The Third International Consensus Definitions for Sepsis and Septic Shock (Sepsis-3). JAMA. 2016; 315(8):801–10.
https://doi.org/10.1001/jama.2016.0287.

2. Fleischmann C, Scherag A, Adhikari NK, Hartog CS, Tsaganos T, Schlattmann P, et al. Assessment of global incidence and mortality of hospital-treated sepsis. current estimates and limitations. Am J Respir Crit Care Med. 2016; 193(3):259–72.
https://doi.org/10.1164/rccm.201504-0781OC.
3. Sakr Y, Jaschinski U, Wittebole X, Szakmany T, Lipman J, Namendys-Silva SA, et al. Sepsis in intensive care unit patients: worldwide data from the intensive care over nations audit. Open Forum Infect Dis. 2018; 5(12):ofy313.
https://doi.org/10.1093/ofid/ofy313.
4. Hu C, Li L, Huang W, Wu T, Xu Q, Liu J, et al. Interpretable machine learning for early prediction of prognosis in sepsis: a discovery and validation study. Infect Dis Ther. 2022; 11(3):1117–32.
https://doi.org/10.1007/s40121-022-00628-6.
5. Park H, Lee J, Oh DK, Park MH, Lim CM, Lee SM, et al. Serial evaluation of the serum lactate level with the SOFA score to predict mortality in patients with sepsis. Sci Rep. 2023; 13(1):6351.
https://doi.org/10.1038/s41598-023-33227-7.
6. van Doorn WP, Stassen PM, Borggreve HF, Schalkwijk MJ, Stoffers J, Bekers O, et al. A comparison of machine learning models versus clinical evaluation for mortality prediction in patients with sepsis. PLoS One. 2021; 16(1):e0245157.
https://doi.org/10.1371/journal.pone.0245157.
8. Oh N, Choi GS, Lee WY. ChatGPT goes to the operating room: evaluating GPT-4 performance and its potential in surgical education and training in the era of large language models. Ann Surg Treat Res. 2023; 104(5):269–73.
https://doi.org/10.4174/astr.2023.104.5.269.
9. Gilson A, Safranek CW, Huang T, Socrates V, Chi L, Taylor RA, et al. How does ChatGPT perform on the United States Medical Licensing Examination (USMLE)?: the implications of large language models for medical education and knowledge assessment. JMIR Med Educ. 2023; 9:e45312.
https://doi.org/10.2196/45312.
11. Jeon K, Na SJ, Oh DK, Park S, Choi EY, Kim SC, et al. Characteristics, management and clinical outcomes of patients with sepsis: a multicenter cohort study in Korea. Acute Crit Care. 2019; 34(3):179–91.
https://doi.org/10.4266/acc.2019.00514.
12. Rooke C, Smith J, Leung KK, Volkovs M, Zuberi S. Temporal dependencies in feature importance for time series predictions [Internet]. Ithaca (NY): arXiv.org;2021. [cited at 2024 Jul 10]. Available from:
https://doi.org/10.48550/arXiv.2107.14317.
13. Theissler A, Spinnato F, Schlegel U, Guidotti R. Explainable AI for time series classification: a review, taxonomy and research directions. IEEE Access. 2022; 10:100700–24.
https://doi.org/10.1109/ACCESS.2022.3207765.
14. Brown T, Mann B, Ryder N, Subbiah M, Kaplan JD, Dhariwal P, et al. Language models are few-shot learners. Adv Neural Inf Process Syst. 2020; 33:1877–901.
15. Liu H, Tam D, Muqeeth M, Mohta J, Huang T, Bansal M, et al. Few-shot parameter-efficient fine-tuning is better and cheaper than in-context learning. Adv Neural Inf Process Syst. 2022; 35:1950–65.
16. Min S, Lyu X, Holtzman A, Artetxe M, Lewis M, Hajishirzi H, et al. Rethinking the role of demonstrations: what makes in-context learning work? [Internet]. Ithaca (NY): arXiv.org;2022. [cited at 2024 Jul 10]. Available from:
https://doi.org/10.48550/arXiv.2202.12837.
18. Zhang Z, Zhao Y, Canes A, Steinberg D, Lyashevska O. written on behalf of AME Big-Data Clinical Trial Collaborative Group. Predictive analytics with gradient boosting in clinical medicine. Ann Transl Med. 2019; 7(7):152.
https://doi.org/10.21037/atm.2019.03.29.
19. Ray PP. ChatGPT: a comprehensive review on background, applications, key challenges, bias, ethics, limitations and future scope. Internet Things Cyber Phys Syst. 2023; 3:121–54.
https://doi.org/10.1016/j.iotcps.2023.04.003.
20. Sanderson M, Chikhani M, Blyth E, Wood S, Moppett IK, McKeever T, et al. Predicting 30-day mortality in patients with sepsis: an exploratory analysis of process of care and patient characteristics. J Intensive Care Soc. 2018; 19(4):299–304.
https://doi.org/10.1177/1751143718758975.
21. Burdick H, Pino E, Gabel-Comeau D, McCoy A, Gu C, Roberts J, et al. Effect of a sepsis prediction algorithm on patient mortality, length of stay and readmission: a prospective multicentre clinical outcomes evaluation of real-world patient data from US hospitals. BMJ Health Care Inform. 2020; 27(1):e100109.
https://doi.org/10.1136/bmjhci-2019-100109.
22. Wu Y, Huang S, Chang X. Understanding the complexity of sepsis mortality prediction via rule discovery and analysis: a pilot study. BMC Med Inform Decis Mak. 2021; 21(1):334.
https://doi.org/10.1186/s12911-021-01690-9.
23. Islam MM, Nasrin T, Walther BA, Wu CC, Yang HC, Li YC. Prediction of sepsis patients using machine learning approach: a meta-analysis. Comput Methods Programs Biomed. 2019; 170:1–9.
https://doi.org/10.1016/j.cmpb.2018.12.027.
25. Li K, Shi Q, Liu S, Xie Y, Liu J. Predicting in-hospital mortality in ICU patients with sepsis using gradient boosting decision tree. Medicine (Baltimore). 2021; 100(19):e25813.
https://doi.org/10.1097/MD.0000000000025813.
26. Jiang LY, Liu XC, Nejatian NP, Nasir-Moin M, Wang D, Abidin A, et al. Health system-scale language models are all-purpose prediction engines. Nature. 2023; 619(7969):357–62.
https://doi.org/10.1038/s41586-023-06160-y.
27. Haleem A, Javaid M, Singh RP. An era of ChatGPT as a significant futuristic support tool: a study on features, abilities, and challenges. BenchCouncil Trans Benchmarks Stand Eval. 2022; 2(4):100089.
https://doi.org/10.1016/j.tbench.2023.100089.


 PDF
PDF Citation
Citation Print
Print



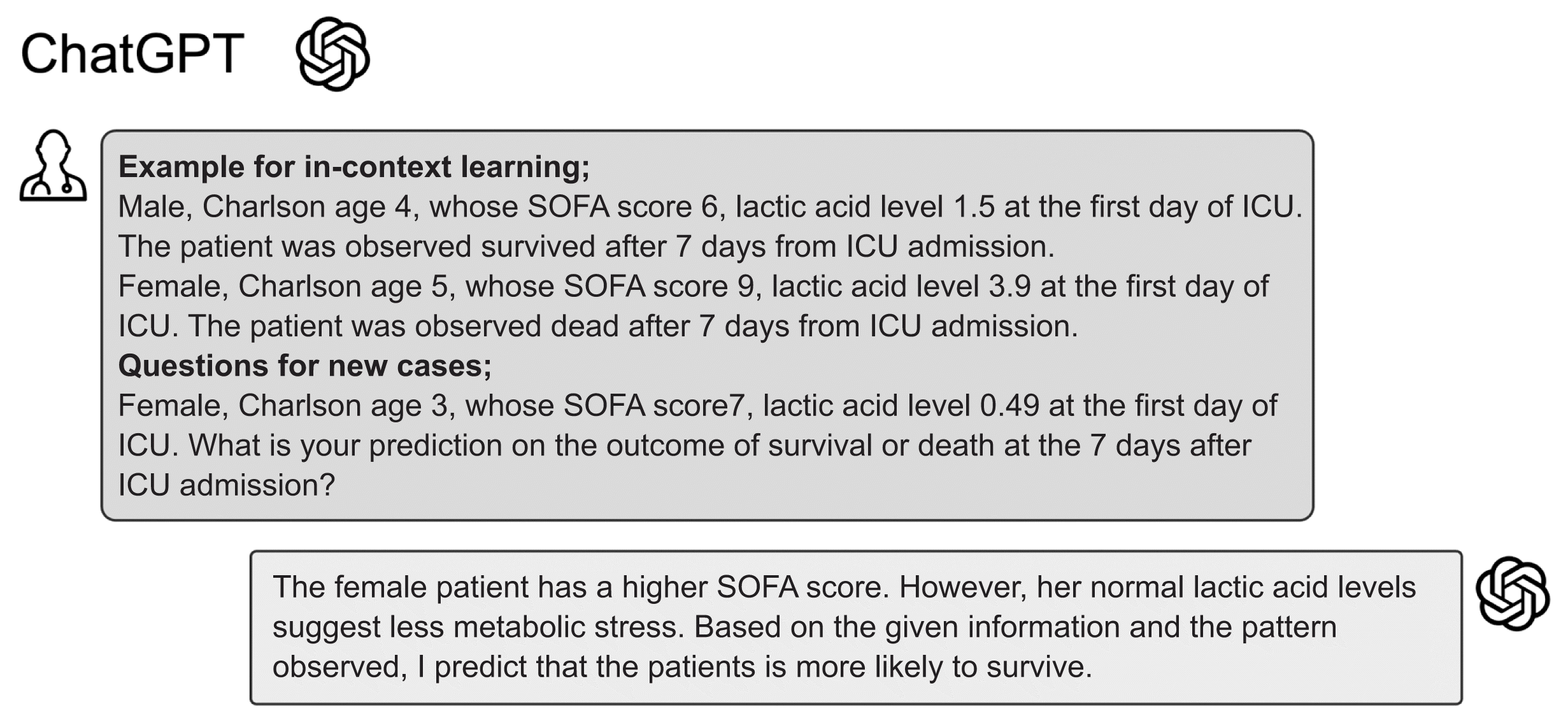
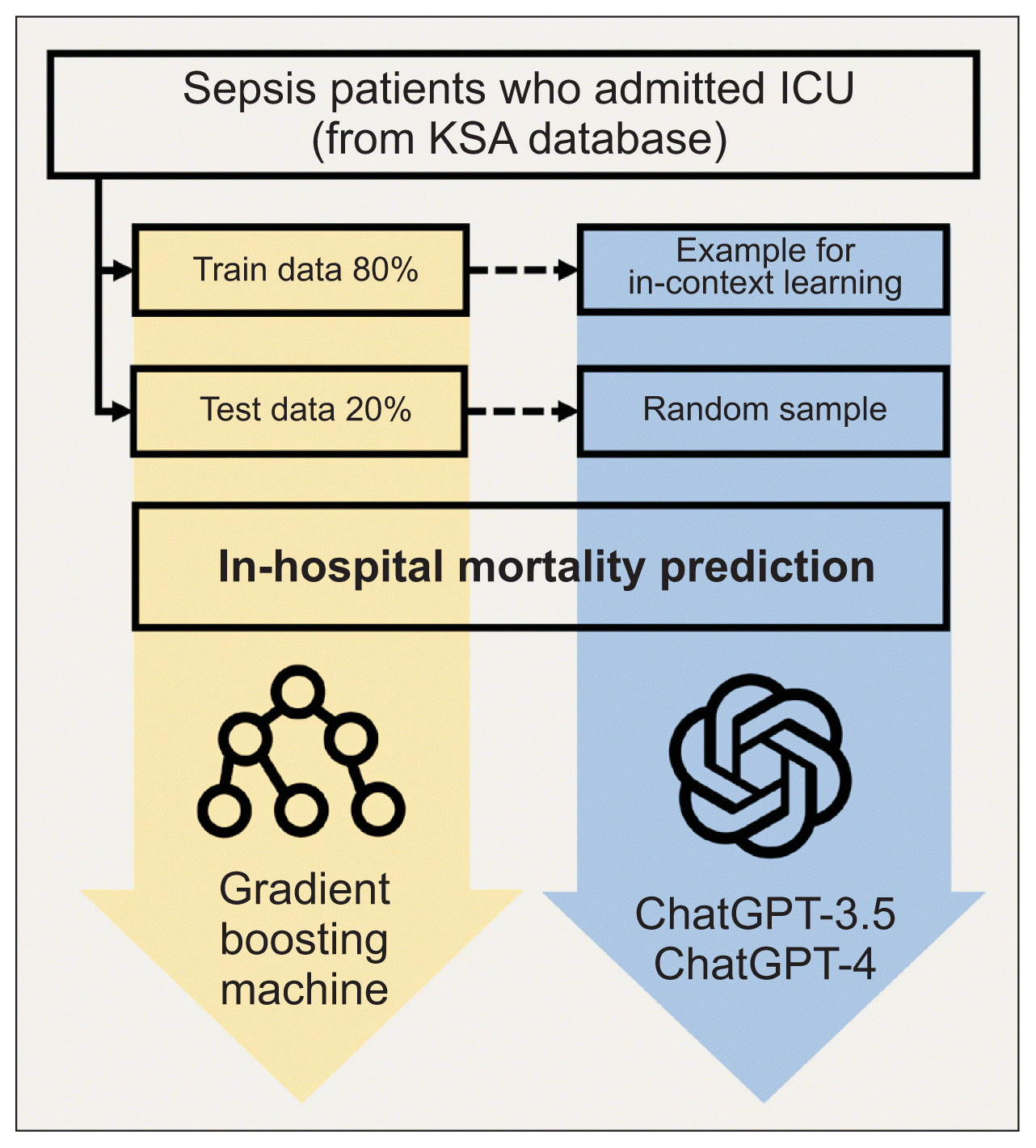
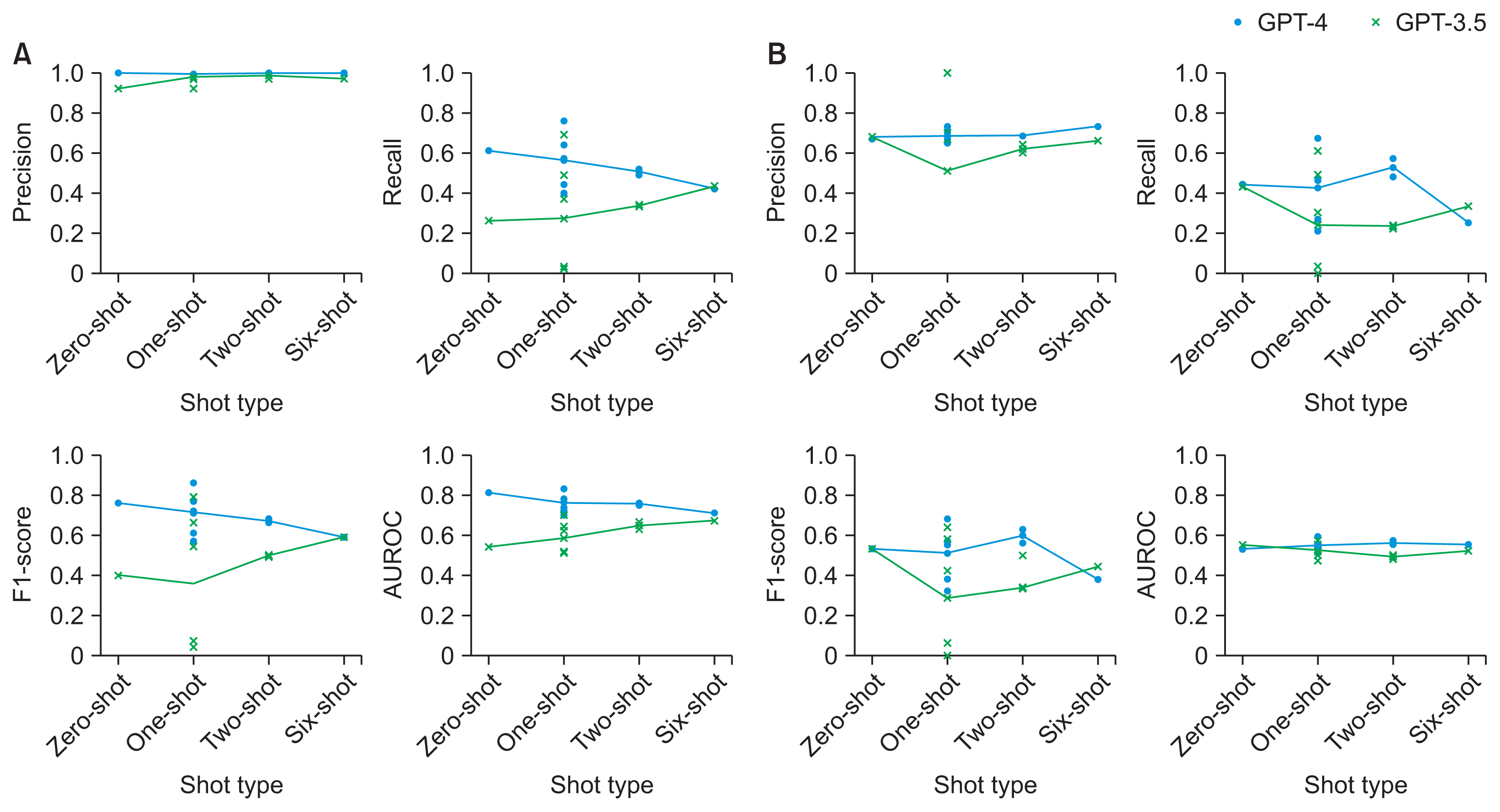
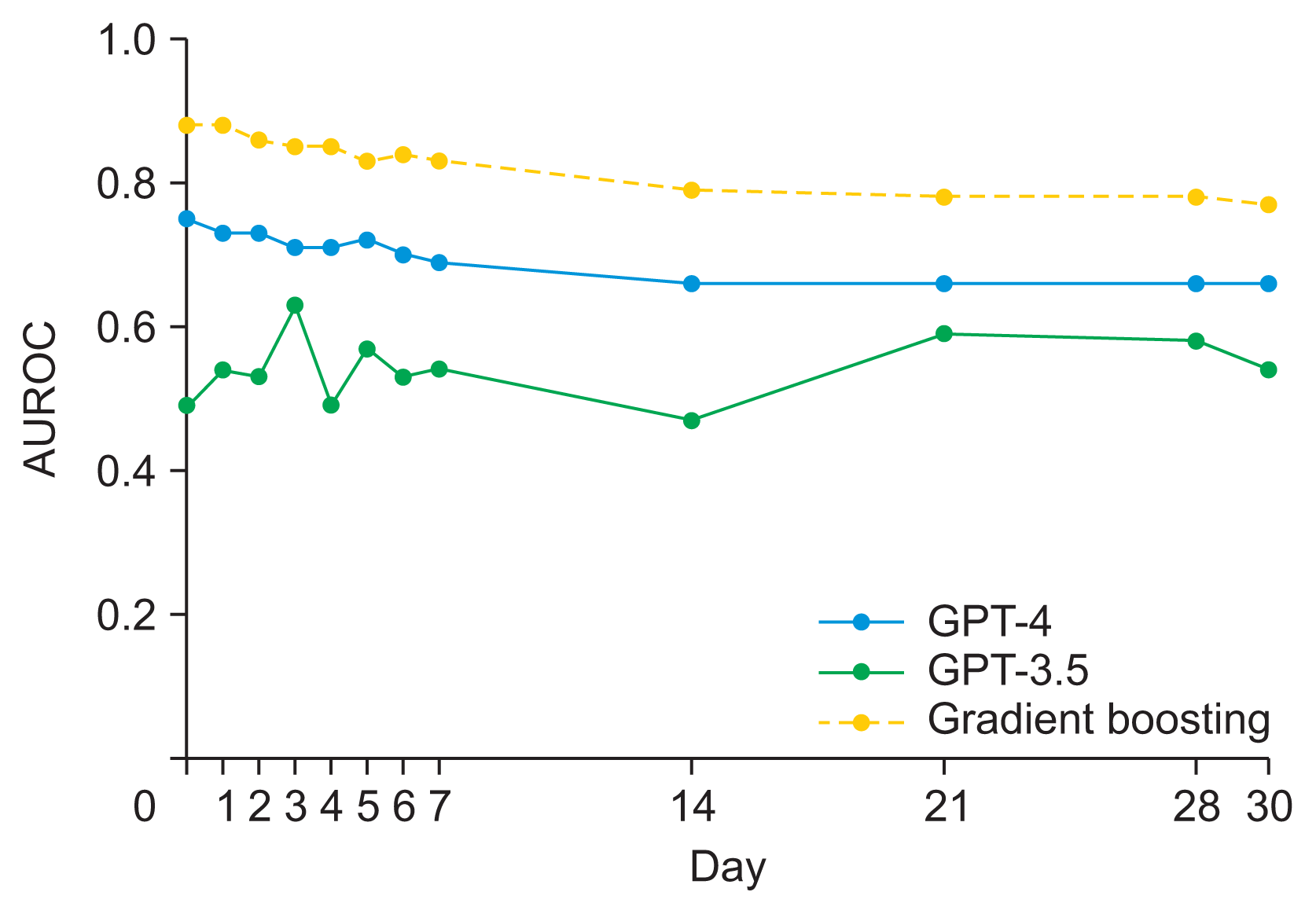
 XML Download
XML Download