

 PDF
PDF Citation
Citation Print
Print



INTRODUCTION
Patient-based real-time QC (PBRTQC) uses routine patient sample analysis results to generate parameters that represent both the patient population and the analytical performance [1]. PBRTQC does not rely on results generated from manufactured QC materials and avoids the associated concerns regarding commutability. With the recent improvements in information technology, the cost of the computing power required to perform increasingly sophisticated PBRTQC analyses has been steadily declining. Therefore, performing PBRTQC each time a new result is generated and before releasing it for patient care is feasible, thereby achieving real-time QC.
Current PBRTQC methods apply statistical techniques to patient results to detect changes in analytical performance (e.g., bias and imprecision) amid pre-analytical and biological variation. Demographic parameters such as age, sex, season, and activity can influence certain biomarkers. Furthermore, differences between reagent lots or calibration activities may induce variations in assay bias or imprecision. In a healthcare setting, advanced pathology in patients in wards or clinics may yield outliers for specific analytes, which can be excluded from PBRTQC calculation. In general, patient populations, subpopulations, and PBRTQC parameters are more stable in primary care and community settings.
PBRTQC is currently an acceptable alternative to conventional QC methods based on episodic repeat testing of a (often commercial) stable material [2]. Significant issues hampering implementation include the requirement for increased staff familiarity, information technology (IT) connectivity issues, and suboptimal laboratory information system software, middleware, or onboard instruments to perform the calculations [3, 4]. Patient-based QC models developed in the 1960s and 1970s used moving averages (MAs), moving medians, average of normal returns, or exponentially weighted MAs (EWMAs). Because of the lack of computing power at that time, the parameters of these models were not optimized for local laboratory data characteristics. In this study, we used these models retrospectively.
In the last decade, newer models have been developed using the moving sum of abnormal returns, moving percentiles, moving standard deviation (MovSD), or average of delta [5-8]. These models focus on specific errors that conventional and earlier patient-based QC models may not optimally detect. Increased computing power coupled with advanced IT capabilities has enabled the real-time application of these models (i.e., before a result is released), aiding the optimization of parameters according to local laboratory data characteristics through simulation [9, 10]. Such an in-silico analysis significantly enhances the understanding of how parameters interact and affect PBRTQC performance. A standardized performance evaluation of PBRTQC has been introduced [11].
Calculations that generate and interpret results from traditional PBRTQC models are relatively straightforward. Classical PBRTQC approaches are generally based on moving statistics such as means or medians. Adjustable model parameters include the block (window) size over which the moving statistics are calculated, control limits, and truncation or winsorization limits to reduce the effects of extreme values/outliers on the calculation of moving statistics. Instead of simulating all variable permutations, which is time- and resource-intensive, a significant advancement in PBRTQC is the use of a simulated annealing algorithm to optimize various parameters and models by minimizing a pre-defined cost function, i.e., reducing the false-detection rate and number of patients affected before error detection (Nped) [11].
PBRTQC algorithms have developed alongside advancements in computer science and the increased availability of more powerful computers. Artificial intelligence (AI), including neural networks and machine learning models, has been applied to PBRTQC [12-15]. The complexity of these newer models poses challenges for laboratory staff in terms of learning and requires more expensive computational hardware and a larger amount of training data for model optimization, which may not be a viable option for smaller laboratories [16]. Therefore, caution must be exercised when determining whether the enhanced performance offered by the more complex models justifies their adoption and feasibility for most laboratories.
In this review, we have described these new models, as well as their advantages and disadvantages.
PBRTQC
Problems faced by traditional PBRTQC models
Most clinical laboratory QC methods have been studied using statistical process control (SPC) methodologies, including internal QC, external quality assurance, and PBRTQC. In traditional SPC theories, a process is generally assumed to be identically and independently distributed, with patient results being considered independent random samples from the same underlying distribution [5, 17]. In traditional PBRTQC, this distribution may be normal or (more commonly) skewed for patient results. When a system is under control, the mean of new samples or test results from this process will not exceed the limits determined based on the underlying distribution. However, a shift or change in the underlying distribution can cause the sample mean to exhibit different behavior and exceed the determined limits, resulting in the detection of an out-of-control event [5, 9]. Traditional PBRTQC models were established based on these assumptions.
However, these assumptions are violated in numerous instances in the real world. First, in most laboratories, the test order is generally not random or independent. For example, most samples in the early morning are typically from hospitalized patients with higher-than-normal values, resulting in false alarms in PBRTQC models [18]. In addition to the type of patient care (inpatient, outpatient, ward, or clinic), factors such as sex, age, and biological and pathological variables can influence the value of an analyte for a patient [19]. These factors can skew or widen the underlying distribution if the test order is not independent. The increased biological variation in the data can overwhelm the model and mask the variation caused by smaller analytical errors; therefore, when a small out-of-control event occurs, the detection power of the PBRTQC model may be compromised.
Among the various factors that can influence the test result and reduce PBRTQC model performance, time is a critical but often ignored factor [19]. In time series data, in which test results are ordered in time, time-dependent variation is a common problem [20, 21]. There are three common types of time-dependent variation: trend, seasonality, and autocorrelation, which likely affect PBRTQC model performance. Trend is the tendency of data to gradually increase or decrease over a long period. For example, test values from a poorly maintained chemistry analyzer may show a decreasing trend because of an aging light source inadequately compensated for by calibration activity. Seasonality occurs when data are affected by seasonal factors at a known time. For example, vitamin D measurements vary across seasons in temperate climates [22]. Autocorrelation measures the relationship between the current and past values of a variable. The carryover effect is an example of autocorrelation in clinical laboratories. A sample with a high analyte concentration may affect the test values of later samples when the analyzer is not thoroughly cleaned between tests. Time-dependent variation increases biological variation in data, thus lowering PBRTQC model performance in practice.
Improving PBRTQC with next-generation methodologies
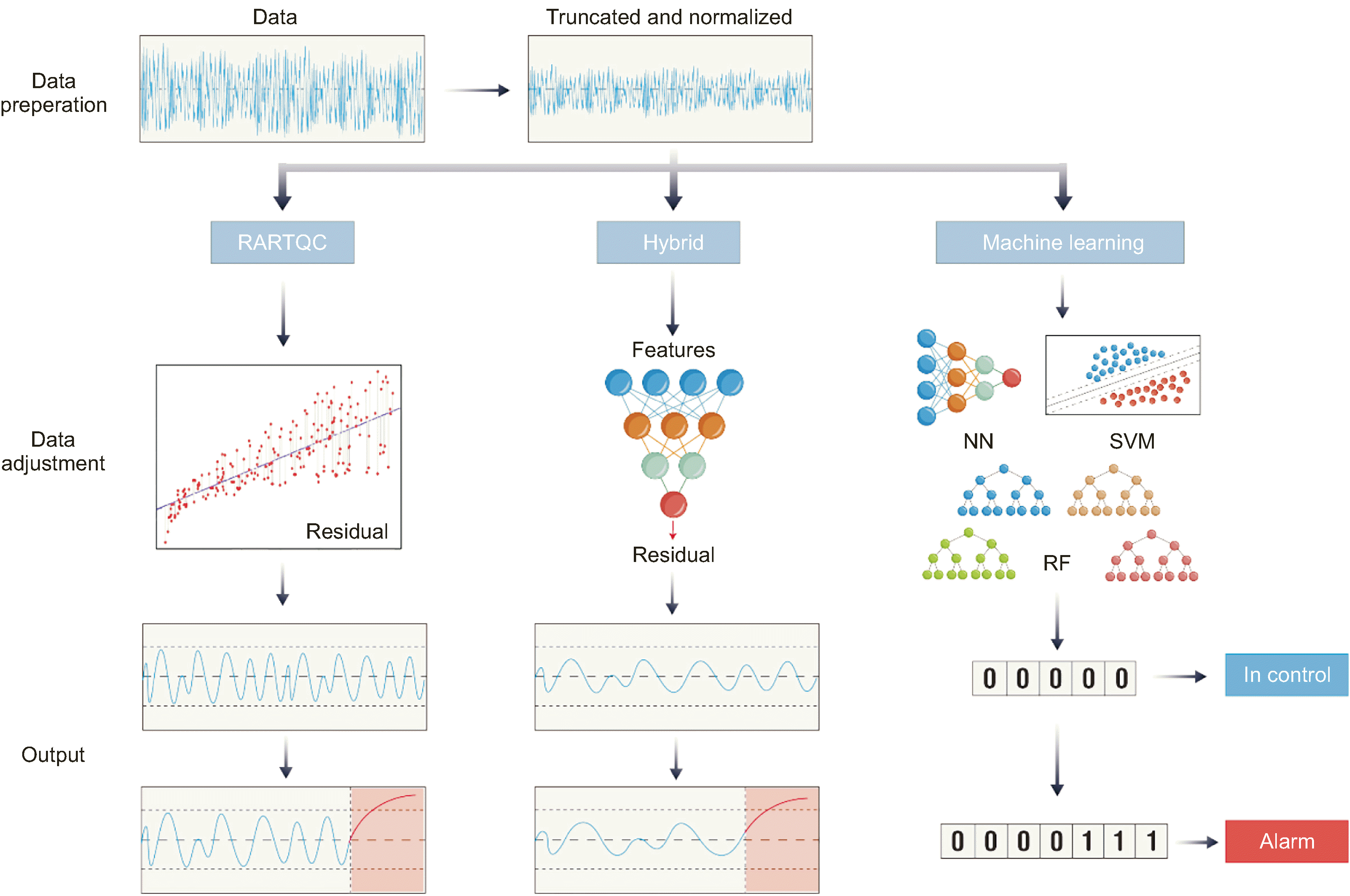
Recently, different research groups have adopted several strategies to solve the aforementioned challenges, including the creation of a subgroup-specific model, an improved SPC framework termed regression-adjusted real-time QC (RARTQC), a machine learning-based strategy, and a hybrid RARTQC/machine learning strategy. The last three strategies are depicted in Fig. 1. Table 1 summarizes the major differences between traditional and next-generation PBRTQC methods.
Subgroup-specific model
One straightforward method to solve data variation between two subgroups is to create a specific PBRTQC dataset for each subgroup. Ng, et al. [18] showed that dividing data into hospitalized and ambulatory subgroups improved PBRTQC model performance. However, our evaluation of the subgroup-specific model revealed that the performance metric used to measure PBRTQC model sensitivity, the average Nped (ANped), was calculated by excluding samples in another subgroup that may have been concurrently tested [18]. Therefore, the actual performance of the subgroup-specific model was overestimated. A similar phenomenon can be observed when using separate models for tests performed on multiple instruments in the same laboratory [10].
RARTQC
RARTQC was the first method to solve time-dependent variations and those caused by different factors in PBRTQC. Many studies have focused on solving time-dependent variation in SPC models [23, 24]. Alwan and Roberts used an autoregressive model to describe the time-dependent variation in time series data and removed the variation by calculating the residuals of the regression model prediction [25]. The residuals were then used in traditional SPC models, significantly enhancing performance. Alwan and Bisell later applied this technique to internal QC [20].
Duan, et al. [19] improved the aforementioned method using a simplified moving average time structure as a baseline. They added influencing factors such as age, sex, patient care type, and feature-engineered diagnostic information to the regression model [19]. The residuals of the regression model were then input into traditional SPC models. Establishing and evaluating RARTQC aligns with the traditional SPC methodology, enabling quick validation using existing methods. RARTQC improves the ANped of traditional PBRTQC by nearly 50% for several analytes [19]. Further, it provides a basic framework for researchers to enhance model performance by improving regression model performance. The better the regression model fits the data, the more non-analytical variation can be removed, thereby improving the model’s performance in detecting analytical errors.
MACHINE LEARNING
The rapid growth of machine learning and AI has shifted the public opinion on the true capabilities of these technologies. Machine learning has been used to improve SPC models since the 1990s. Artificial neural networks (ANN) and deep learning algorithms have been modified for SPC models in manufacturing. Therefore, applying a machine learning algorithm to PBRTQC is a well-established approach for improving model performance. In machine learning, a PBRTQC model should be categorized as a time series classification model that uses time series as data input and output values that indicate whether the assay is in or out of control. Time series classification has been extensively studied in applied statistics and computational sciences for decades. Many existing machine-learning algorithms and techniques can potentially be applied to PBRTQC to improve current state-of-the-art methods [26-29].
Building a well-thought-out time series model requires expertise and experience. The time structure for each dataset is unique and requires exploration of the data and testing different hypothetical time structures to develop the most appropriate statistical model. The rise of neural network-based machine learning models, such as convolutional neural networks, long short-term memory, recurrent neural networks, and attention models, has provided a new direction for solving time series problems [28-30]. Machine learning algorithms eliminate the need for prior knowledge of the time structure as they can automatically identify the best time structure model. A straightforward application of machine learning to PBRTQC involves training a classification model and allowing the machine learning algorithm to determine the underlying time structure and factors that affect the test results. This strategy does not require the model developer to have domain knowledge or familiarity with the dataset. Zhou, et al. [12] employed this strategy to develop machine learning PBRTQC models and experimented with several algorithms to improve the model.
Despite its simplicity, this strategy has several disadvantages. The most crucial problem is that machine learning models trained with simulated data may underperform in practice. In most laboratories, the training dataset exhibits significant imbalance. Artificial errors are typically introduced to simulate out-of-control data points and create a balanced dataset. In SPC-based PBRTQC model establishment, artificial errors were typically introduced using a simplified abrupt model, where the error amount was immediately applied at the starting point of the simulated out-of-control event. However, in practice, the transition from an in-control to an out-of-control event may not be abrupt but incremental and is unique to each out-of-control event. Extrapolating PBRTQC models based on SPC methods to incremental transitions is valid because the moving statistics eventually reach the control limits [18]. However, training machine learning-based PBRTQC models with simulated data featuring an abrupt transition from an in-control to an out-of-control scenario may result in the model not effectively recognizing incremental transitions in real-world scenarios. Therefore, caution must be exercised when extrapolating such a machine learning-based PBRTQC model.
Another significant drawback of this strategy is the high computational cost of building and operating the model in real-time. Complex machine learning models require expensive computational hardware, which may nullify the cost savings from implementing PBRTQC models [16]. Finally, establishing a machine learning model involves processes and evaluation metrics that are different from those of SPC-based models. This makes it difficult to compare the performance of SPC-based models with that of machine learning-based models, and the results from machine learning-based models may be substantially more challenging to interpret.
RARTQC/MACHINE LEARNING HYBRID METHOD
An alternative strategy to applying a machine learning algorithm is to use a hybrid strategy that combines the benefits of traditional SPC-based model assumptions with the simplicity of machine learning algorithms to build high-performance models. The RARTQC framework is key to this concept. As mentioned above, one advantage of this framework is its ability to enhance performance by focusing on improving the regression model fit. Machine learning regression algorithms can learn the complex time structure of the PBRTQC dataset and handle high-dimensional data with multiple influencing factors. Because the performance evaluation of the RARTQC framework is the same as that of traditional PBRTQC, these hybrid models can be easily compared with traditional methods, and the results can be interpreted based on a Shewhart chart.
Notable hybrid models recently developed by various researchers include Neural Network PBRTQC (NN-PBRTQC) by Mindray, machine learning nonlinear regression-adjusted PBRTQC (mNL-PBRTQC) by Zhou, et al. [15], and patient-based pre-classified real-time QC (PCRTQC) by Man, et al. [14].
Mindray’s NN-PBRTQC adopts an ANN mapping model that integrates patient-specific parameters, including sex, age, clinical department, and disease diagnosis, to predict test values. An ANN algorithm learns the high-dimensional hidden relationships between the influencing factors and the time series structure, potentially revealing linear or nonlinear relationships. These structures can be learned automatically and do not require developers with high data expertise. The model also includes an alarm filter that reduces the false alarm rate without sacrificing the ANped. mNL-PBRTQC uses a nonlinear classification and regression tree regression model that incorporates the test date, test time, instrument brand, and hospital level in addition to the four original factors of Duan’s regression model. Incorporating more variables and introducing a nonlinear regression algorithm improves model performance. PCRTQC adopts a slightly different approach using a support vector machine (SVM) instead of a regression model to classify patient information and results into pre-defined scores. The scores are then used as inputs for traditional moving statistics. Although this method uses an SVM classifier instead of a regressor, the results of assigning a score to each patient are essentially the same as those of a machine learning regression model. With a more sophisticated SVM classifier design, PCRTQC showed improvement over previous methods.
Although the hybrid strategy solves certain issues of directly applying a machine learning classifier to PBRTQC, disadvantages such as the high computational cost and the difficulty in extrapolating the model persist. The increase in the algorithm complexity necessitates a careful examination of the logic behind the increased complexity. For example, a highlight of PCRTQC is that the model incorporates other test results of the same person to provide a prediction. The incorporation of correlated test results can be highly effective in improving model performance. However, the models are trained with simulated data, considering only the value change of one test and neglecting interactions among correlated tests. Therefore, in practice, in cases where the alteration in correlated analytes during an out-of-control event differ from that in the simulation, the model might fail to detect the out-of-control event.
ANOMALY DETECTION APPROACH OF PBRTQC MODELS
Despite extensive research in the pathology field, there are several challenges in establishing a well-performing PBRTQC model. In addition to solving PBRTQC as a traditional SPC or time series classification problem, we can view it as an anomaly detection (AD) problem [31]. AD is designed to identify items and behaviors that do not conform to normal expectations and are often referred to as outliers, novelties, noise, or deviations. In PBRTQC, the results of an analyte following an abnormal occurrence can be considered abnormal data that do not comply with the expected pattern. Therefore, knowledge of AD in data science may provide new insights into PBRTQC.
The AD methodology focuses on solving an imbalanced dataset, which was not adequately addressed in previous PBRTQC research. Recently, deep learning-based AD has led to innovative solutions [32]. Researchers have designed and trained GANomaly (GAN, generative adversarial network) to produce high-quality reconstructions of negative samples and apply them to QC [33]. Kim and Ha [34] reported the core concept of AD based on deep learning, i.e., when positive samples cannot be obtained. However, negative samples are sufficient and comprehensive; a pre-designed and well-trained AI model can master the core characteristics of negative samples, and samples that deviate from the characteristics of negative samples can be judged as positive by the AI model. Traditional PBRTQC techniques such as MA, MovSD, and EWMA can be regarded as AD based on statistics. Similar to that of GANomaly, their core concept is to master the statistical characteristics of negative samples, such as the mean and variance. The statistical models can then be applied to QC without the need forpositive samples. From the perspective of data science, dealing with an unbalanced dataset is a necessary condition for PBRTQC. Directly applying powerful machine learning or deep learning classification models without solving this problem is impractical.
DATA CHALLENGES WITH PBRTQC
A significant problem in the development of these novel PBRTQC tools is the lack of a well-established “ground truth” for in-control and out-of-control data. First, true analytical errors may evade detection by modern instruments and routine internal QC practices [35]. Second, these errors may be dismissed and not acted upon by laboratory staff and thus be included in the supposedly “error-free” dataset [36]. Conversely, true errors (such as that for magnitude, duration, and type, including bias and/or imprecision) detected by routine laboratories may not be fully characterized. The lack of accurately labeled data impedes the training of the models, which may lead to biased or misleading performance when applied in routine settings.
CONCLUSION
PBRTQC continues to evolve, using statistical or AI tools to reliably separate the underlying population “noise” (including pre-analytical variation) from the analytical signals. Recent machine learning-based tools have advantages as well as disadvantages that must be understood before adoption. With AI tools becoming more user-friendly and computationally efficient, major disadvantages such as complexity and the need for high computing resources are reduced. We will start to see the practical implementation of these more advanced algorithms in the near future.
 XML Download
XML Download