

 PDF
PDF Citation
Citation Print
Print


서론
질병을 진단하고 환자의 병리상태를 파악하여 최적의 치료법을 제시하거나 치료가 잘되고 있는지 판단하기 위해, 다양한 조직 및 생체액(혈액, 요, 척수액, 복수 등)에 대한 멀티오믹스(유전체, 전사체, 후성유전체, 단백체, 수식화단백체, 대사체 등) 데이터가 생산되고 있다. 유전체, 전사체는 분석의 용이성으로 인해 가장 많이 생산되어 왔으나, 실제 생명현상에서 작용하는 단백체 및 수식화단백체(인산화단백체, 당쇄화단백체, 아세틸화단백체, 유비퀴틴화단백체 등)를 기반으로 유전체, 전사체, 대사체 등을 통합 분석하는 방향으로 전환이 일어나고 있다. 학계에서는 CPTAC (Clinical Pro-teomic Tumor Analysis Consortium) [1-3]와 ICPC (In-ternational Cancer Proteogenome Consortium) [4,5]가 단백유전체 연구들로 이런 트렌드를 이끌고 있고, 산업계에서는 많은 회사들이 단백체 기반 멀티오믹스 분석을 통한 질병 진단, 치료최적화, 치료모니터링 기술 개발에 박차를 가하고 있다. 이러한 연구들은 멀티오믹스 데이터를 통합 분석하여 멀티오믹스 분자 시그니처를 기반으로 환자 그룹을 정의하고, 각 그룹에 적합한 치료법을 제시하는 그룹레벨의 정밀의료 방법론을 제시하고 있다. 하지만 치료 전에 수집된 시료에 대해 생산된 멀티오믹스 데이터로부터 치료를 받으면서 이질적으로 변화하는 질환 상태에 기반한 전이, 재발, 약물 반응성 등에 대한 질환 표현형을 예측하는 것은 한계가 있다. 이를 해결하기 위해, 치료 중에도 수집된 시계열 임상정보를 딥러닝하여 개인별 질환 상태의 이질성을 고려한 치료제를 제시할 수 있는 개인별 맞춤형 정밀의료 방법론이 개발되고 있다. 본 논문에서는 임상정보 기반 정밀의료에 대해서는 2형당뇨병을 대상으로 한 딥러닝 모델 분석결과를, 멀티오믹스 기반 정밀의료에 대해서는 조기발병 위암에 대한 단백유전체 분석결과를 예시로 각 방법론을 소개하고자 한다.
본론
1. 임상정보 기반 정밀의료의 예
먼저 지난 20년간 서울대학교병원과 분당서울대학교병원 내분비내과를 내원한 18만 명의 당뇨병환자 코호트에 대해서 얻어진 기본 임상정보, 혈액 검사 데이터(CBC [complete blood count] 데이터 포함), 요분석 데이터, 투약 정보 등의 종속데이터를 수집하였다. 수집된 시계열 임상정보 데이터들을 연속변수(예: alanine aminotransferase [ALT], 콜레스테롤 수치; Fig. 1A, 녹색 박스), 이산변수(예: 투약된 약물, 나이, 성별 등; Fig. 1A, 파란색 박스)로 나누고, 각 변수 그룹에 대해서 순환 신경망(recurrent neural network, RNN)을 구축하고, 이들을 다층 퍼셉트론(multilayer perceptron, MLP)을 이용하여 통합하는 딥러닝 모델을 구축하였다. 이를 이용하여 당화혈색소(HbA1c)와 추정사구체여과율(estimated glomerular filtration rate, eGFR)을 매핑하였다. RNN 학습 결과 당화혈색소에 대해서는 R2 = 0.75, eGFR에 대해서는 R2 = 0.97이었다(Fig. 1B). 이때 MLP 첫 번째 레이어에 임베딩된 환자들의 유사성을 이용하여 7개의 환자 그룹(Cluster 0∼6)을 동정하였다(Fig. 1C). 이들 7개의 그룹 중에서 당화혈색소가 상승하는 Cluster 0, 1, 4, 6 (Fig. 1D)에 특이적으로 증가한 변수들을 동정하여, 간손상 수치인 ALT 레벨이 증가한 Cluster 1은 metabolism-mediated insulin resistance, C반응단백질(C-reactive protein)이 증가한 Cluster 4는 inflammation-mediated insulin resistance, 호르몬 수치(thyroid stimulating hormone)가 증가한 Cluster 6은 hormone-mediated insulin resistance 를 가지는 환자 그룹으로 파악되었다(Fig. 1E). 다만 Cluster 0에서 증가한 호염기구(basophil)와 인슐린저항성과의 관련성은 명확하지 않았다. 이들 환자 그룹별 인슐린저항성에 대한 이해를 기반으로 그룹별로 치료제를 제시할 수 있다. 예를 들어, 염증이 증가한 Cluster 4에 대해서는 염증 억제제와 당뇨병약을 같이 처방할 수 있다.
Fig. 1.
RNN (recurrent neural network)-based deep learning model using time-course clinical data. (A) Deep learning model architecture. X i,j indicates clinical data measured or drug types (i) used at time j. Forty clinical variables and 20 drug types were used. The other numbers indicate the node numbers in the corresponding neural networks. (B) Prediction accuracy of the deep learning model. (C) Patient clustering using the embedded states in the 1st multilayer perceptron (MLP) layer. (D) Distribution of temporal profiles of the measured (True) and predicted glycated hemoglobin HbA1c (Predicted) in patients included in each cluster. Principal component analysis (PCA) plot and distance represent how the embedded state in the 1st MLP layer vary over time. Blue to yellow colors in PCA plot represent early to late time points, respectively. (E) Contribution of each clinical variables and drug types to each cluster. T values indicate positive and negative contributions to defining each cluster. Clinical variables highly contributing to individual clusters are indicated in red. (F) Actual measured (blue) and model predicted (orange) glycated hemoglobin changes over years and actual prescribed (blue) and model determined (orange) treatment regimens.
eGFR, estimated glomerular filtration rate; LSTM, long short-term memory; UMAP, uniform manifold approximation and projection.
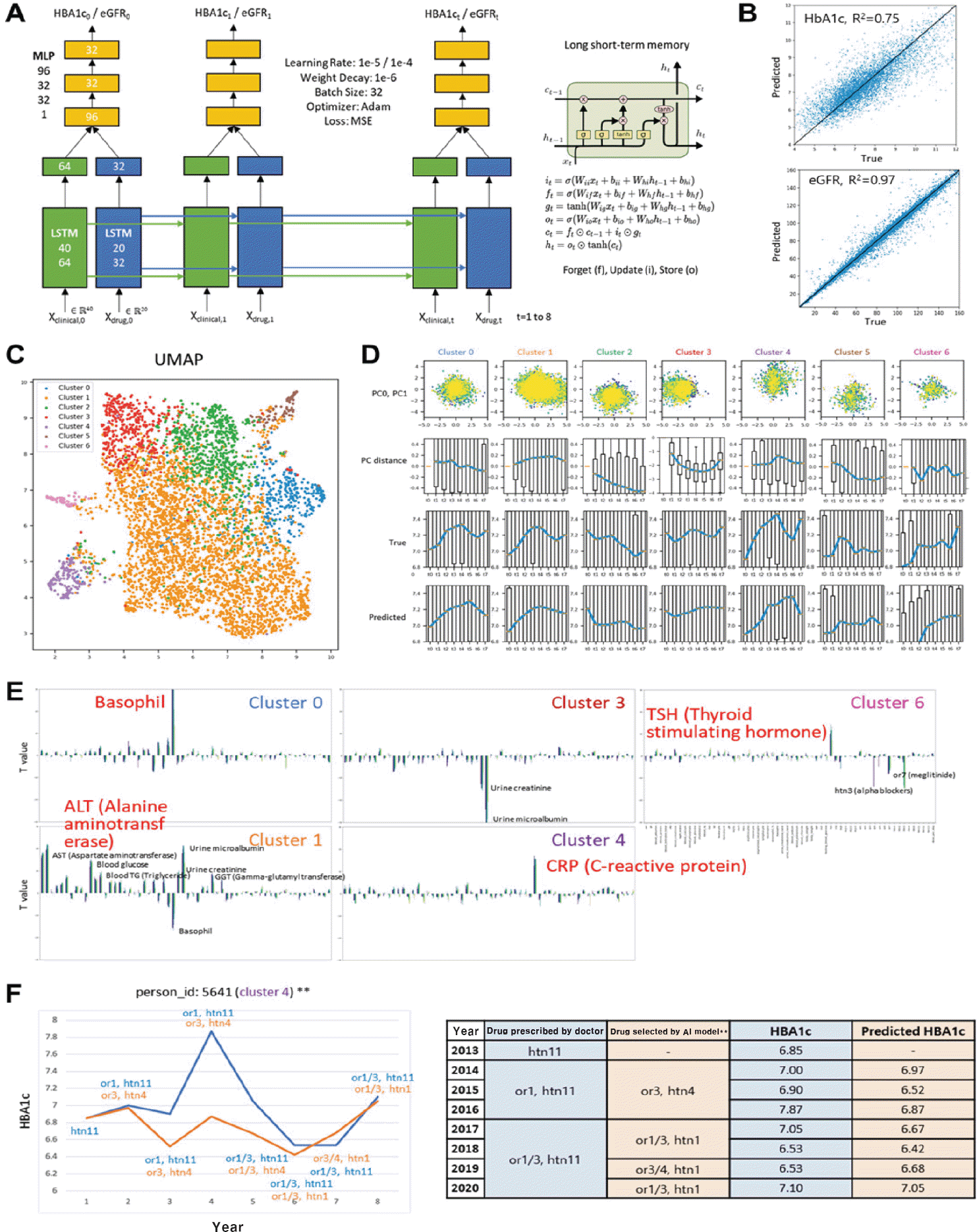
멀티오믹스와 달리 RNN 기반 딥러닝 모델은 개별 환자별로 치료제와 당화혈색소, eGFR을 매핑할 수 있으므로, 새로운 환자에 대해서도 해당 환자의 임상정보, 혈액ㆍ요 분석 데이터를 얻은 후 모든 가상의 투약 정보(지난 20년간 한 번이라도 처방된 투약법)를 딥러닝 모델에 넣고 당화혈색소를 예측한 뒤, 가장 당화혈색소 감소를 보이면서 eGFR 추정치는 안정된 구간에 속하는 투약법을 환자에게 투약해야 하는 최적의 치료제로 선정하였다(Fig. 1F, 오른쪽 표 – 파란색: 실제 투약된 약물, 오렌지색: 모델이 정한 약물; 왼쪽 프로파일 – 파란색: 실제 당화혈색소 변화, 오렌지색: 모델이 정한 약물이 처방되었을 때 모델이 예측한 당화혈색소 변화). 이러한 딥러닝 모델을 통한 최적의 치료제의 선정은 앞으로 당뇨병환자의 치료제 선택 시 기본적으로 고려했던 임상상황(동반질환, 저혈당 위험도, 부작용, 나이, 비용 등)에 더하여 하나의 근거로 사용될 수 있고 당뇨병 치료에서의 정밀의료에 좀 더 근접하는 발판이 될 수 있겠다.
2. 멀티오믹스 기반 정밀의료의 예
80명의 조기발병 위암환자로부터 위암 조직과 주위 정상 조직 시료에 대해 전사체, 글로벌단백체, 인산화단백체, 당쇄화단백체 분석을 통해 전령RNA (messenger RNA, mRNA) 발현량, 단백질 발현량, 인산화 정도, 당쇄화 정보 등의 데이터를 생산하였다. 각 오믹스 데이터에서 median absolute deviation 상위 10, 20, 30 백분위에 속하는 유전자, 단백질, 인산화, 당쇄화 단백질을 선정하고, 이들을 이용하여 non-negative matrix factorization 클러스터링을 수행하였다. 클러스터링 반복 수행에서의 재현성을 consensus value matrix로 표현하고, 이 matrix에 대한 클러스터링을 수행(Fig. 2A-D, 왼쪽 heat map)하여 cophenetic cor-relation을 계산하였다. Cophenetic correlation의 클러스터 개수에 따른 변화를 관찰하여 클러스터(아형, subtype)의 개수를 결정하고, 그 개수에 해당하는 환자별 아형을 예측하였다. 각 오믹스 데이터로부터 예측된 환자 아형에 속하는지 여부를 binary value matrix로 만든 후, 각 데이터로부터 예측된 아형이 서로 일치하는 정도를 고려하여 최종 환자 아형의 개수를 4개(Sub1∼4)로 결정하였다(Fig. 2E). 각 클러스터의 특성을 이해하기 위해 각 오믹스 데이터로부터 예측된 아형별 환자들 간의 발현량 비교분석을 수행함으로써 각 아형에서 나머지 아형들(예: Prot1 vs. Prot2∼4)에 비해 발현량이 유의하게 높은(P < 0.05) mRNA, 단백질, 인산화 시그니처들을 동정하였다.
Fig. 2.
Determination and characterization of subtypes of patients with early-onset gastric cancers through integrative clustering using mRNA and protein data (A-D). (A) mRNA, RNA1∼2. (B) Protein, Prot1∼4. (C) Phosphorylation, Phos1∼3. (D) N-glycosylation, Gly1∼3. For example, RNA1 was defined by upregulation of 919 genes (rna1). (E) Four subtypes (Sub1∼4) determined by integrated clustering of individual omics-based clusters. (F) Cellular pathways enriched by the mRNA (rna1∼2) or protein signatures (prot1∼4, phos1∼3, or gly1∼3) defining each subtype. Colors in the heat map indicate the enrichment significance, -log10(P value), and the pathways with P ≤ 0.05 were denoted in color (see the color bar).
Adapted from the article of Mun et al. (Cancer Cell 2019;35:111-24.e10) [4] with original copyright holder's permission.
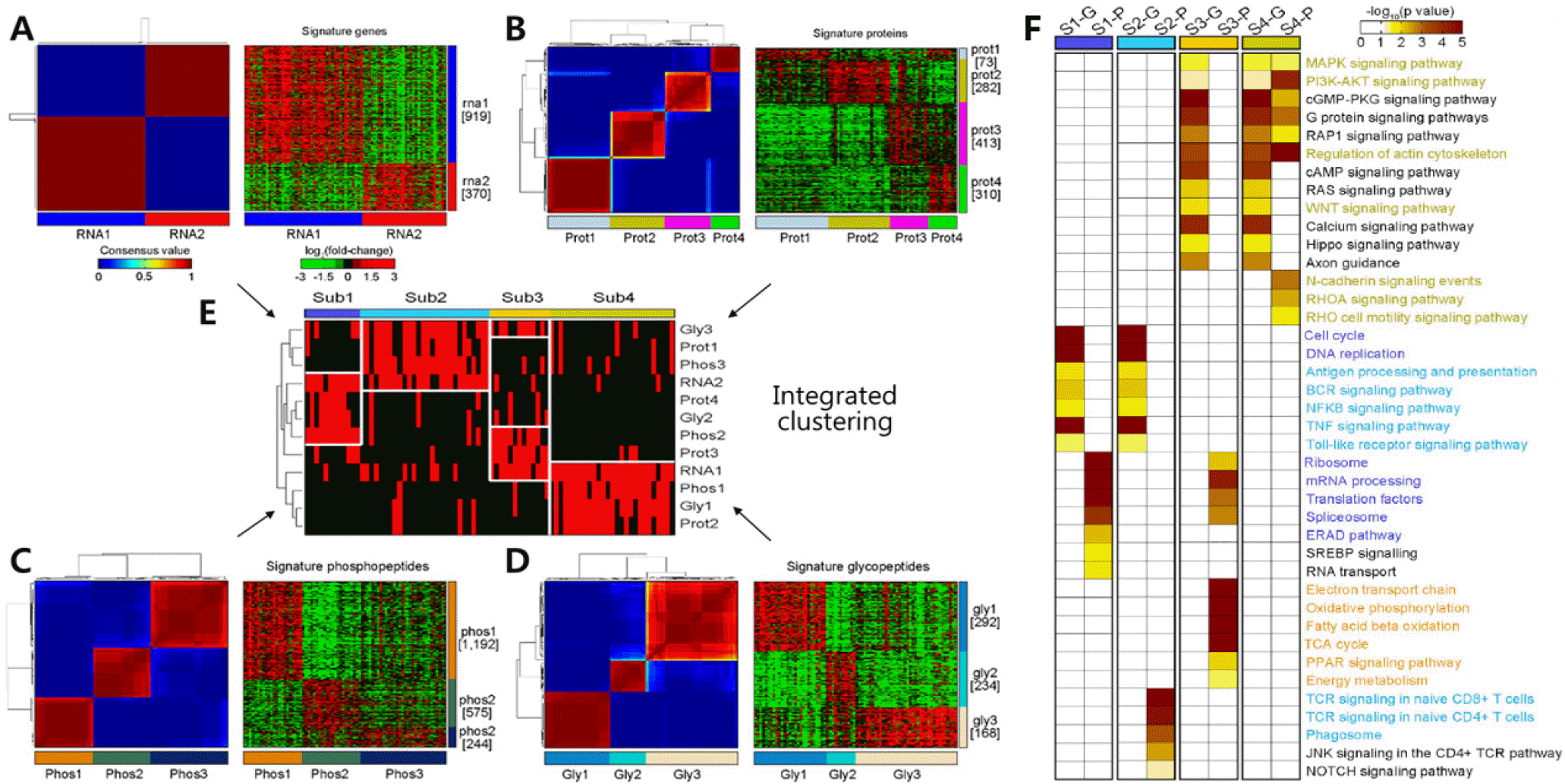
이들 시그니처들(Fig. 2A-D, 오른쪽 rna1∼2, prot1∼4, phos1∼3, gly1∼3)에 대한 ConsensusPathDB를 이용하여 gene set enrichment analysis (GSEA)를 수행함으로써, 각 아형과 통계적으로 유의하게 관련된 세포경로를 동정하였다(Fig. 2F). mRNA, 단백질 시그니처들이 세포분화(cell proliferation) 관련 세포경로를 대변하므로 Sub1을 prolif-erative tumor; mRNA, 단백질 시그니처들이 면역 관련 경로를 대변하므로 Sub2를 immunogenic tumor; 단백질 시그니처들이 대사관련 경로를 대변하므로 Sub3을 metabolic tumor; mRNA, 단백질 시그니처들이 invasion 및 epithe-lial-mesenchymal transition (EMT) 관련 경로를 대변하므로 Sub4를 invasive tumor로 정의하였다.
각 아형별 암의 기능적 특성을 대변하는 세포경로에 속하는 mRNA, 단백질, 인산화 시그니처를 선별하고, 공용 데이터베이스상의 단백질-단백질 상호작용 정보, 패스웨이 DB 및 기존 문헌상의 조절관계 정보를 바탕으로 선별된 아형별 시그니처 및 그들과 상호작용하는 분자들로 구성된 아형별 네트워크 모델을 구축하였다(Fig. 3). Sub2 immunogenic tumor를 대변하는 네트워크 모델은 암이 분비하는 암항원을 antigen presenting (AP) cell이 식균 작용(phagocyto-sis)을 하고, 이를 항원처리(processing)하여 암항원을 항원제시(presentation)하면, cytotoxic T cell이 이를 인지하여 암세포를 죽이는 항암면역(anti-tumor immunity)을 보여주고 있다(Fig. 3A). Sub4 invasive tumor를 대변하는 네트워크 모델은 위암에서 invasion과 EMT에 중요하다고 알려진 RhoA 신호경로의 upstream, downstream 경로를 보여주고 있다(Fig. 3B). Sub2, 4 네트워크 모델에서 단백질 시그니처(노드 보더, P, G로 표시된 노드들)를 제거하면 항암면역과 RhoA 경로를 제대로 파악할 수 없다는 것을 알 수 있다.
Fig. 3.
Network models showing pathways defined by the interactions among the genes (rna2 for Sub2 and rna1 for Sub4) and proteins (prot1, phos3, and gly3 for Sub2 and prot2, phos1, and gly1 for Sub4; see Fig. 2E) predominantly upregulated in Sub2 (A) and Sub4 (B). Node colors and circled labels, respectively, represent upregulation of mRNA (node center), protein (node boundary), phosphorylation (circled P), and glycosylation (circled G) levels in each network. Adapted from the article of Mun et al. (Cancer Cell 2019;35:111-24.e10) [4] with original copyright holder's permission.
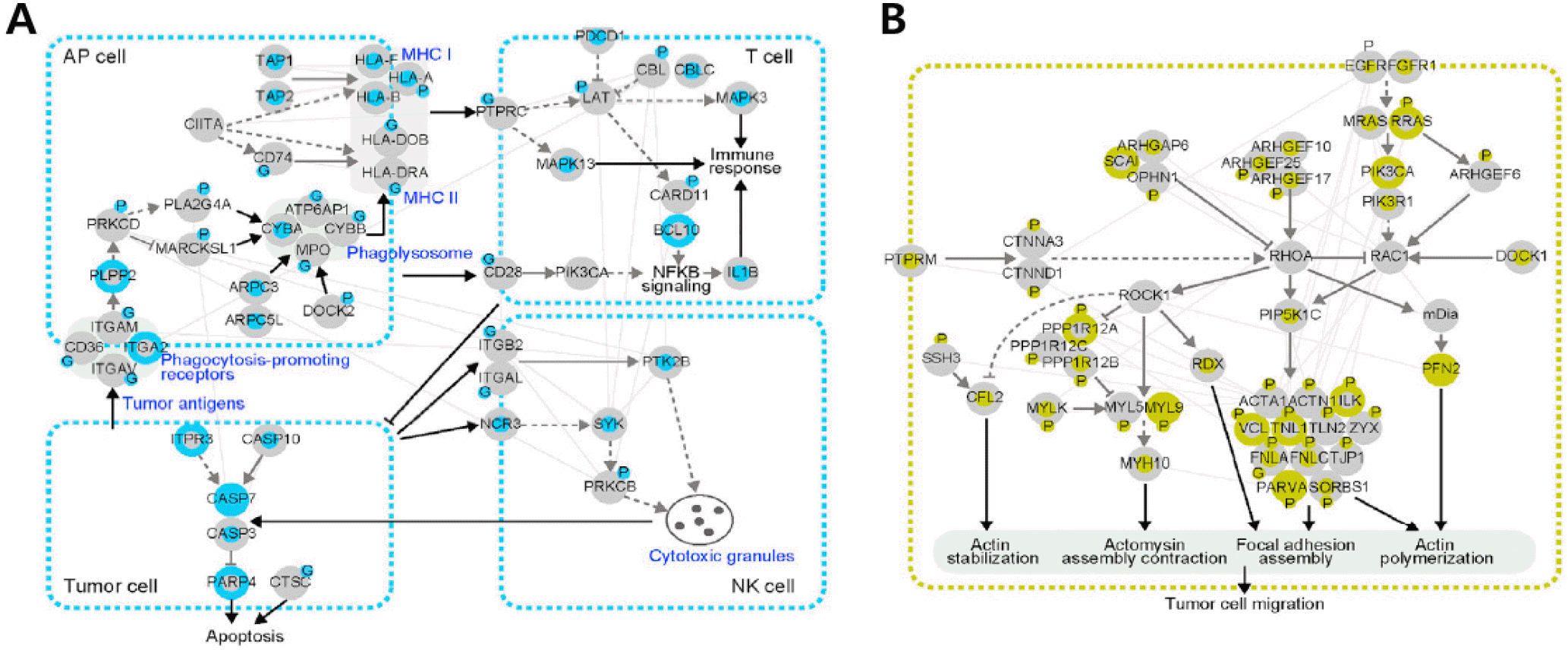
마지막으로 GSEA 결과(Fig. 2F)와 네트워크 모델을 통합하면, 각 아형에 속하는 환자들에 대한 치료방법을 제시할 수 있다. 예를 들어, 가장 예후가 안 좋은 Sub4 invasive tumor 에 대해서는 RhoA 신호경로를 억제해야 하고, GSEA 결과를 보면 항암면역(anti-tumor immunity)이 저하된 것을 알 수 있다. 이와 관련된 Sub4의 mRNA, 단백질 시그니처를 분석해보면 myeloid-derived suppressive cell (MDSC)이 증가되어 있고 PVR (PVR cell adhesion molecule)과 같은 면역관문(immune checkpoint)들이 증가되어 있다는 것을 알 수 있다. 따라서, Sub4 암의 치료제로 RhoA 억제제(예: ROCK inhibitors), MDSC 억제제(예: IL-10), 면역관문억제제(예: PVR을 억제하는 TIGIT)들에 기반한 병용치료를 최적 치료제로 제시할 수 있다.
결론
멀티오믹스 기반 정밀의료 기술 개발이 환자의 진단과 치료에서 패러다임 전환(paradigm shift)을 가져다 줄 것은 사실이나, 오믹스 분석은 기본적으로 많은 데이터 생산 비용이 들어 모든 환자들에 대해 멀티오믹스 데이터를 생산하는 것은 어렵다. CPTAC, ICPC의 경우에도 200명 이하의 환자에서 멀티오믹스 분석이 수행되었다. 오믹스 데이터와는 달리, 현재 임상에서 환자의 상태 파악을 위해 측정하는 기본 정보(키, 몸무게, 혈압, 체질량지수 등), 혈액ㆍ요 검사를 통한 질환별 정보(당뇨병의 경우 당화혈색소, 혈당, 크레아티닌, 콜레스테롤 수치 등), 영상(컴퓨터단층촬영, 자기공명영상, 양전자단층촬영 등)을 포함하는 임상정보는 모든 환자에 대해 존재한다. 따라서 이들 임상정보 빅데이터와 멀티오믹스 데이터를 통합하여 개선된 정밀의료 기술을 개발하는 노력들이 활발하게 진행되고 있다.
 XML Download
XML Download