

 PDF
PDF Citation
Citation Print
Print



INTRODUCTION
Spatial hearing in the single-sided deafness (SSD) population exhibits wide variability, with some patients showing relatively good sound localization performance, while others cannot differentiate between sounds presented on the left or right [1]. The variable impact of hearing loss on sound localization in individuals with SSD suggests that adaptive processes in the higher-level auditory pathway might improve spatial hearing through auditory training. Evidence for the effectiveness of auditory localization training has been shown in hearing-impaired patients [2,3], subjects with normal hearing [4-6], and those with simulated asymmetric hearing [7-9]. Physical resources are a practical obstacle to applying this training in clinics, as the training requires a spacious sound-attenuated room with sophisticated instruments to control multiple calibrated speakers. The setup for multimodal protocols, such as coupling auditory tasks with visual feedback or motor responses (both of which significantly promoted the effect of training in previous studies), is even more complicated [9-11].
Virtual reality (VR) hardware, which has recently become available, allows multimodal integration with auditory tasks in an artificially constructed space. However, the virtual audio system based on generic head-related transfer functions (HRTFs) would not be optimal for use in patients with SSD [12,13]. To localize auditory sources, patients with SSD who are deprived of binaural difference cues largely depend on monaural spectral cues ignored by individuals with normal symmetric hearing [9,14,15]. Since factors including sizes and shapes of the torso, head, and pinna, which vary from person to person, contribute significantly to monaural HRTFs, individualized/custom HRTFs are needed for patients with SSD to perceive spatial location accurately. As previously shown in a simplified procedure with a set of binaural recordings of stimuli [16], the incorporation of binaurally recorded auditory stimuli into a VR-based training program could be applied to patients with spatial hearing deficits to receive sound localization training based on personally tailored stimuli. Training in a virtual environment requires only a consumer VR device rather than sophisticated instruments and equipped spaces.
In this study, we assessed the feasibility of using binaurally recorded spatial stimuli to train patients to carry out azimuthal sound localization in a virtual environment. For SSD patients, the binaurally recorded stimuli were matched to virtual speakers at the exact azimuthal location. Auditory spatial performance and subjective scores were evaluated before and after training to measure the effects of training, as well as 3 weeks after the end of training, to determine the persistence of the training effects. The acceptability of the training program was also tested in normal-hearing (NH) controls with non-individualized stimuli. Different training protocols were applied to the two groups (SSD and NH), as these groups use different auditory spatial cues and show different sound localization abilities at baseline.
MATERIALS AND METHODS
Participants
A total of 40 NH and 20 SSD participants were recruited in the VR training. Subsequently, 38 NH and 16 SSD subjects were included in the data analysis because of personal scheduling issues in 2 NH and 4 SSD subjects. The SSD group was based upon the international consensus on the audiological criteria of SSD, with the pure-tone average (PTA) in the better ear of 30 dB HL or better and that in the impaired ear of 70 dB HL or worse [17]. All subjects received monetary compensation based on the number of their visits.
The Institutional Review Board of University Hallym University Sacred Heart Hospital approved the study protocol (No. 2020-10-013) and written informed consent was obtained from each participant.
Auditory stimuli
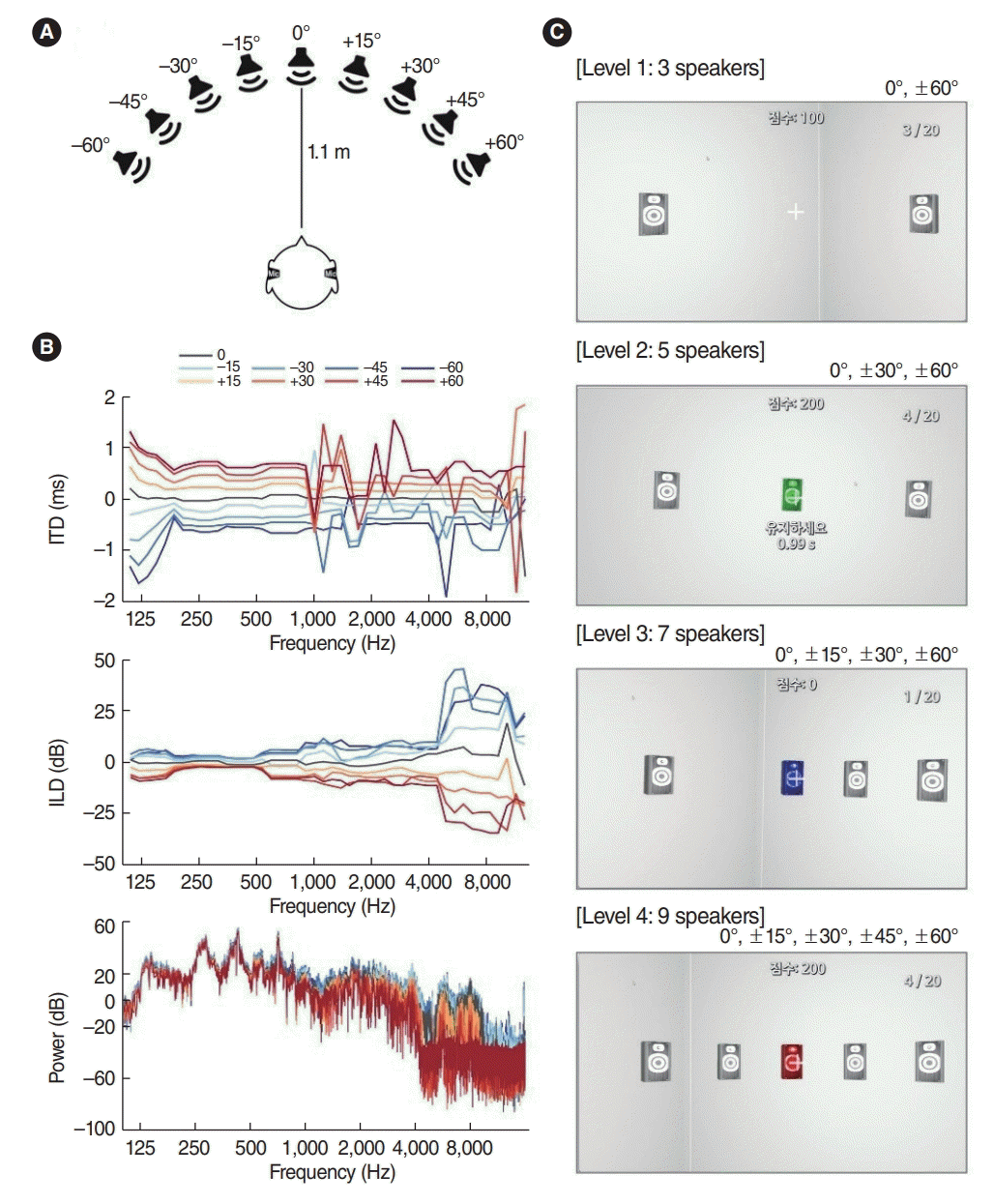
Subjects wore in-ear binaural microphones (SP-TFB-2, Sound Professionals Inc.) that were placed carefully at the entrance of the ear canal to minimize destruction of the pinna, and they were seated 1.1 m away from a speaker at zero elevation in a clinical audio booth (2.05×1.90×1.85 m). The subjects were instructed not to move their head and body after rotating participants by nine angles (0, ±15°, ±30°, ±45°, and ±60°) to acquire stereo stimuli reflecting each azimuthal source. A total of 81 stimuli per participant were yielded (9 Korean digits ×9 angles). For the NH group, stimuli were created by recording binaurally over a standard anthropometric model of the head and torso (KEMAR-45BA, GRAS Sound & Vibration) to capture binaural difference cues. The KEMAR manikin was placed on the rotating chair, and the same recording procedure was performed. The recorded stimuli yielded a clear spatial percept in the frontal azimuth based on the available interaural level difference (ILD), interaural time difference (ITD), and spectral cues (Fig. 1A and B). The recorded stimuli were created using the Adobe Audition program (Adobe) with sampling rates of 48,000 Hz.
VR programming
Audiovisual VR training was implemented using an HTC Vive system, comprising one head-mounted display (HMD; resolution, 1,080×1,200 pixels; field of view; 110°, refresh rate, 90 Hz), one controller, and two lighthouse base stations for outside-in head position tracking. All stimuli protocols and virtual speakers were developed with the Unity program (Unity Technologies).
The subjects sat on a chair facing a desk that held a monitor and two sensors, and wore the HMD in a quiet room (3×2.5 m). Auditory stimuli are provided through headphones, a part of the HMD. The virtual environment consisted of an empty square room indicated with horizontal/vertical lines, and the direction of the subject’s head was marked by a small white cross (Fig. 1C). Virtual speakers were positioned at ear level across 120° in the frontal azimuth, and the number of speakers varied from 3 to 9 to make level differences.
The created stimuli were matched to virtual speakers at identical azimuthal locations. To initiate a trial, the subject directed their head to the center speaker, which turned green (Fig. 1C). Subsequently, a stimulus was randomly presented from one of the virtual speakers. The subject was instructed to turn their head to point to the speaker perceived to emit the sound and to press the button on the handheld controller. Visual feedback was provided with the color of the virtual speaker changed according to response accuracy: correct, incorrect, and almost correct (i.e., selecting a speaker next to the correct one) were indicated with blue, red, and orange, respectively (Fig. 1C).
VR-based training protocol
The VR-based sound localization training consisted of 4 levels according to the numbers (3, 5, 7, and 9 speakers) of virtual speakers (Fig. 1C). Each level consisted of a training set of 10 trials per speaker and a test set of 20 trials. The level of difficulty was optimized based on the concurrent performance evaluation. The training began at level 1, which had three speakers. The training set was repeated until the rate of correct responses on the last 20 trials reached 70%; once subjects reached this criterion, the VR program automatically loaded the test set of the level containing 20 trials. If the correct responses on the test set were 70% or higher, subjects proceeded to the next training level; if not, training was repeated at the same level. If the subject had correct responses over 90% on the test set in three consecutive sessions, the subject was allowed to skip that level at the next visit. VR-based training consisted of three 40-minute training sessions per week over 3- and 6-consecutive week periods for participants in the NH and SSD groups, respectively.
Sound localization assessments in VR and the sound field
Sound localization and subjective spatial hearing were assessed before (Pre), after (Post) and 3 weeks after (Post-3w) the training. Sound localization in the VR environment was assessed three times in all but 1 SSD subject at Post and 5 NH subjects at Post-3w. The test sets of 20 trials for all four levels in the VR-based training were used for this evaluation. The Pre-test was conducted before the first training session followed by the post-test acquired a couple of days after the last training session.
Additionally, a sound localization test (1 session=50 trials: 5 speakers×10 repeats) in the sound field was conducted in a sound-attenuated booth with five speakers in varying azimuthal locations (0, ±30°, and ±60°), 1 m from the subject and at ear level. For each trial, one of the nine Korean digits used in the VR program was randomly presented at the most comfortable level for each subject; subjects were instructed to report the perceived source location among the five speakers using a Bluetooth keypad. Only nine subjects in the SSD group completed the sound field test on all three conditions (Pre, Post, and Post-3w) due to a technical issue. The test in the sound field was not repeated in the NH group, which showed ceiling performance at pre-test.
Subjective evaluation of spatial ability: K-SSQ and visual analog scale scores
To evaluate subjective improvement, the Korean version of the Speech, Spatial, and Qualities of Hearing Scale (K-SSQ) [18] was administered to all 54 subjects at three time conditions except for 6 NH subjects at Post-3w. In the SSD group, a visual analog scale (VAS) was adopted to measure the subjective perception of participant sound localization in daily life; the VAS was administered at Post and Post-3w to compare changes after training. The VAS score ranged from –10 to +10 (marked changes compared to Pre). Subjects were asked to complete 8 VASs for four types of sounds (nature sounds, human voices, environmental sounds, and machinery sounds) in two listening situations (indoors and outdoors). The reported eight scores were averaged per subject/session.
Statistics
Statistical tests were conducted using R [19] with the rstatix package [20]. Normality was assessed using the Shapiro-Wilk test. To examine the group differences in age, PTA, and sex, t-tests and Fisher’s exact tests were conducted. The lme4 package was used to perform a linear mixed-effects analysis to determine if the changes in sound localization performance in VR over time (fixed effect) were significant, with subject ID included as a random effect [21]. The post-hoc test was performed using the emmeans package with Tukey’s honestly significant difference (HSD) method [22]. The correct responses of sound localization in the sound field were assessed using nonparametric repeated-measures analysis of variance (ANOVA) in jmv [23]. The correct response rate on the two sound localization tests (VR and the sound field) was compared to the chance level with a one-tailed t-test. Changes in K-SSQ scores over time were analyzed using a linear mixed-effects model in the NH group and a nonparametric repeated-measures ANOVA in the SSD group. In the SSD group, VAS scores at Post were compared to those at Post-3w using a paired t-test. All data are expressed as the mean±standard deviation unless otherwise stated.
RESULTS
Demographic characteristics
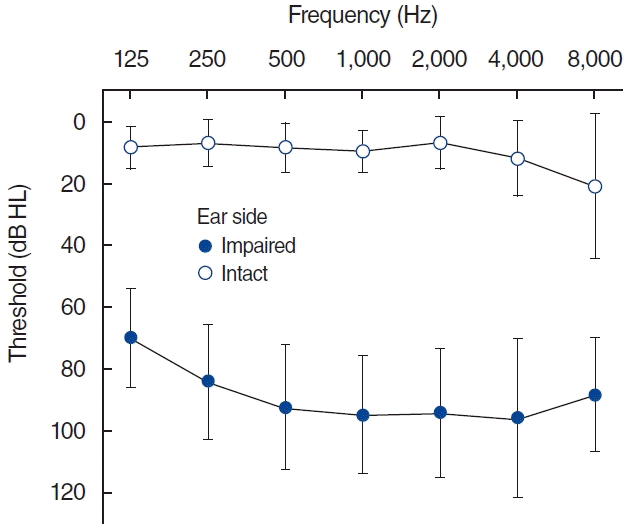
The SSD group was significantly older than the NH group (t(22,2)=–2.19, P=0.040) (Table 1). The hearing threshold of the intact ear in the SSD group was within the range of normal hearing (range, –2 to 20 dB HL) (Fig. 2). However, as expected with the significant age difference, the hearing threshold in the intact ear of the SSD group was significantly worse than that of the NH group in the right (t(23,8)=–6.9, P<0.001) and left (t(28,9)=–6.3, P<0.001) ears. The sex distribution was not significantly different between the two groups (P=0.384).
Sound localization improved in the SSD group but with slower progress than in the NH group
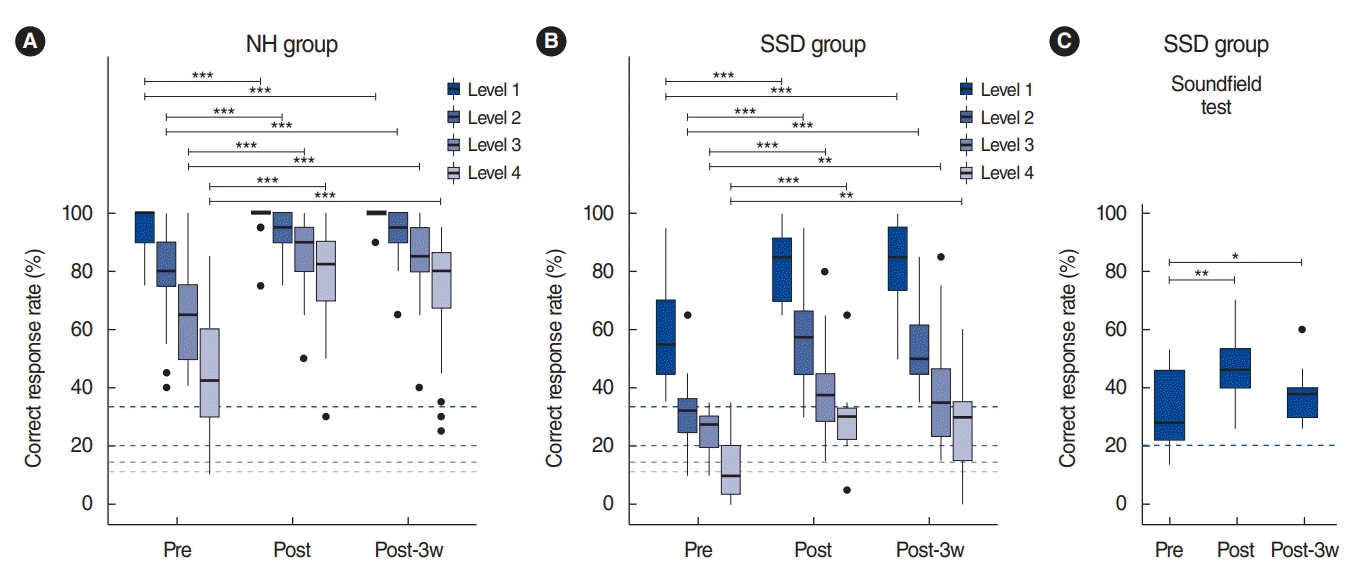
In the first training session, 25% of the SSD group proceeded to level 2 by scoring over 70% on level 1. However, no SSD subjects were able to skip level 1 until the seventh session. In the last session, two SSD subjects skipped level 1, and three SSD subjects proceeded to level 3 by scoring over 70% on level 2. No SSD subjects proceeded to level 4. In the NH group, 26 out of 38 subjects proceeded to level 4 in the first session, and 35 subjects skipped level 1 in the fourth session. In the third session, all NH subjects proceeded to level 4 by scoring over 70% in level 3. In the last session, only one subject started with level 1, and 16 proceeded directly to level 4 for the entire session.
The correct response rates on the sound localization test in the VR environment were compared across three-time conditions (Pre, Post, and Post-3w) and four levels in each group (Fig. 3). The mixed-effect model revealed that the correct response rate in the VR environment varied significantly across time in all four levels, both in the SSD group (level 1: χ2(2)=30.6, P<0.001; level 2: χ2(2)=35.6, P<0.001; level 3: χ2(2)=16.3, P<0.001; and level 4: χ2(2)=17.6, P<0.001) and in the NH group (level 1: χ2(2)=21.1, P<0.001; level 2: χ2(2)=46.7, P<0.001; level 3: χ2(2)=46.9, P<0.001; and level 4: χ2(2)=66.0, P<0.001). Simultaneous pairwise comparisons using Tukey’s HSD test indicated that the correct response rates increased significantly after training (both Post and Post-3w) compared to the scores before training (Pre) on all four difficulty levels in both groups (P<0.01 in the SSD group and P<0.001 in the NH group); in contrast, the performance at the Post time point was not significantly different from that at the Post-3w time point (P>0.05 on all levels in both groups). The correct response rates at Pre in the NH group were significantly higher than chance (Fig. 3A, dashed lines) at all four levels. In the SSD group, the correct response rates at Pre were significantly better than chance in levels 1–3 but not in level 4 (t(15)=0.41, P=0.344) (Fig. 3B); the performance improved to be significantly better than chance at Post (t(15)=4.79, P<0.001) and Post-3w (t(15)=4.05, P<0.001).
In the nine SSD subjects who completed the sound field test in all three conditions, nonparametric repeated-measures ANOVA revealed a significant difference in the correct response rates over time (χ2(2)=8.40, P=0.015) (Fig. 3C). Post-hoc testing indicated that training significantly improved performance (Pre vs. Post: P=0.002; Pre vs. Post-3w: P=0.034). The performance at Post (45.6±13.7) was better than that at Post-3w (37.6±10.9), but the change was not significant (P=0.184).
Subjective improvement in spatial hearing in the SSD group
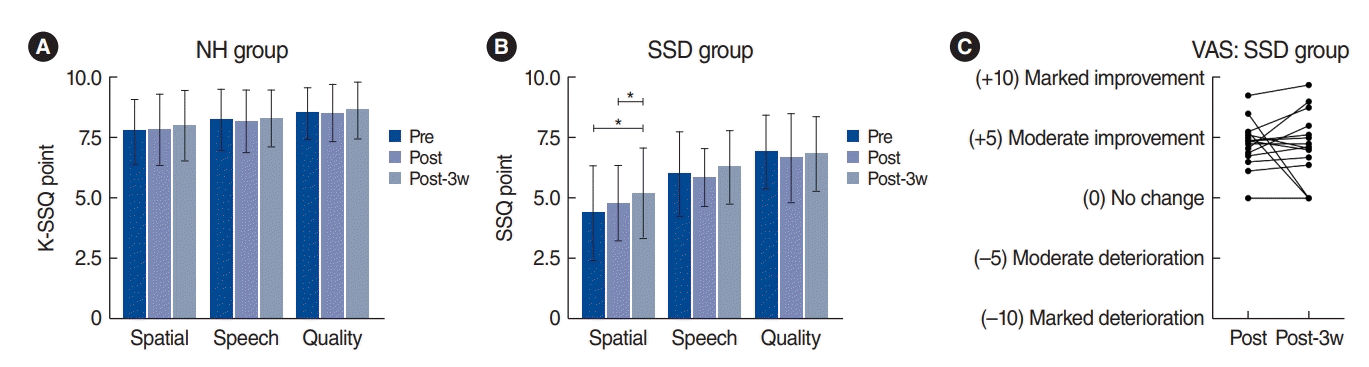
Subjective improvement in spatial hearing was assessed with K-SSQ and VAS scores. Regarding K-SSQ scores, the NH group showed no difference across time in all three items (P>0.05), but the SSD group showed a significant change across time in the spatial item (χ2(2)=6.13, P=0.047) (Fig. 4); specifically, the scores of the SSD group at Post-3w were higher than those at Pre (P=0.019) and Post (P=0.045). In the VAS scores compared to Pre, all subjects but one reported some improvement at Post (4.51±1.91) (Fig. 4C) and no change at Post-3w (4.28±2.84, t(14)=0.28, P=0.783).
DISCUSSION
This study aimed to test the feasibility of VR training for SSD patients with auditory stimuli created by binaural recordings. Subject-specific stimuli were used for sound localization training in the SSD group to provide all possible spatial cues, as this group is vulnerable to potential distortion of spatial information when using audio programs with standard HRTFs. The results of this study demonstrated that subject-specific stimuli could be applied in VR-based localization training and suggested that this training may be an effective treatment option for improving spatial hearing in patients with SSD. After training with individualized stimuli, the SSD group exhibited a significant increase in sound localization performance as measured both in the VR environment and in the sound field (Fig. 3); these subjects also reported subjective improvement (Fig. 4). The training-induced improvements were retained after 3 weeks (Fig. 3), consistent with previous studies showing that training exerted sustained effects for up to one month afterward in individuals with hearing impairment [3].
The effective auditory localization training in SSD patients with individualized spatial stimuli
In previous studies, a longer duration [24] and earlier exposure [1] to single-sided hearing were associated with better sound localization in this population, suggesting that an adaptive process in the higher-level auditory pathway is facilitated by experience with single-sided hearing. When binaural hearing is artificially perturbed, cue weighting across auditory spatial cues changes to increase dependency on more reliable cues [25]. Dynamic changes in spatial hearing occur in response to acute monaural plugging and are modified by training, allocating perceptual weight preferentially to the head shadow effect and monaural spectral cues from the intact ear [7,9]. In patients with asymmetric hearing loss, the redistribution of cue weighting varies depending on the reliability of the remaining cues. For example, residual hearing at low frequencies strengthens ITD cues, and residual hearing at high frequencies strengthens spectral cues [14,25]. Considering the effects of experiences and the diverse audiological profiles of the clinical population with asymmetric hearing loss, a training program encompassing all possible spatial cues would enable trainees to develop the most efficient combination of spatial hearing strategies [11].
This study applied individualized binaural recordings to produce personalized spatial auditory stimuli for VR-based training in the SSD group. Individualized binaural recordings have been used to investigate the neurophysiological response underlying auditory spatial processing in experimental paradigms where the difficulty is locating spatially separated speakers. The prerecorded stereo stimuli presented via earphones produced distinct auditory cortical responses, contributing to the spatial perception that decodes the azimuthal location of the source [26].
To create an immersive VR environment, software development tools provide solutions for simulating 3D audio [27] based on a standard HRTF database created using anthropometric averages. As described in the Introduction, since the standard HRTF database does not incorporate individual variation in spectral cues, the benefits of individualized HRTF demonstrated in normal hearing subjects [12,13] are expected to be greater in patients with SSD. However, the generation of personal HRTFs based on individual measurement is highly time-consuming, technically difficult, and expensive [28]. Our method of binaural recording could easily capture individualized spatial information in the head-centered position. Therefore, our method could be helpful to compensate for the disadvantages of auditory training in the sound field and avoid the disadvantage of using a standardized HRTF database in VR-based training.
Benefits of VR-based training for individuals with hearing impairments
On-site auditory localization training requires a wide sound-attenuated booth with multiple calibrated speakers and a control system, and an even more sophisticated instrument is needed to produce multimodal interactions, such as visual feedback or motor responses, which have been reported to promote the training effect [9,29]. As VR-related technology advances, custom VR hardware enables multimodal feedback, including auditory stimuli, visual feedback, and motor responses in auditory training programs without needing additional instruments.
The present study provided different training protocols in two groups. The NH group received fewer training sessions with limited auditory spatial cues but showed faster progress to a higher level of difficulty than the SSD group. Although the purpose of this study was not to optimize training protocols, we observed that the SSD group needed more sessions to show effective results. In some patients, the improvement observed immediately after training was not retained after 3 weeks (Fig. 3C and 4C), indicating that more sustained training is required to maintain the benefits of training. In this regard, VR-based training that enables home training can be beneficial for minimizing the number of clinical visits required and reducing travel time and cost burdens.
Limitations of the study and future works
This study did not test whether training with stimuli based on the standard HRTF would also benefit the SSD group, although this finding was expected to a limited degree. The results of the NH group align with previous evidence showing that subjects with normal symmetrical hearing benefit from VR-based sound localization training with non-individualized stimuli [13,30]. In patients with SSD, training with standardized stimuli might facilitate the learning of spatial hearing strategies that rely on monaural level cues. Nevertheless, the contribution of other spatial cues, such as interaural differences and monaural spectral cues, would be largely limited.
In this study, head movement was not allowed during the presentation of training stimuli. Subjects needed to fix their head at the center of the virtual environment to correctly receive the spatial information contained in the prerecorded stimuli. This method can be used to localize moving auditory objects if stimuli are recorded with moving sources, with head movement still restricted during stimuli presentation. Individual filtering in real time based on individualized HRTF measurements would be necessary to allow head movement in VR.
The results of this study show that VR-based training for sound localization was effective in patients with SSD when performed using binaurally recorded stimuli. The SSD group exhibited significant improvements in terms of sound localization and subjective satisfaction; these improvements persisted for 3 weeks after training. Further research is required to fine-tune training protocols and to determine the long-term effects.
HIGHLIGHTS
▪ Sound localization training using virtual reality (VR) technology is helpful for patients with single-sided deafness (SSD) and does not require complicated instruments or setups.
▪ The generic head-related transfer function in VR, however, does not reflect individual variation in monaural spatial cues, which is critical for auditory spatial perception in patients with SSD.
▪ The feasibility of using binaurally recorded spatial stimuli was assessed for azimuthal sound localization training in a virtual environment.
▪ Sound localization performance improved after VR-based training in individuals with SSD and normal hearing.
▪ VR-based training represents a new therapeutic treatment option for impaired sound localization.
 XML Download
XML Download