

 PDF
PDF Citation
Citation Print
Print



Introduction
Breast cancer is the most common cancer among women. Digital pathology has contributed significantly to its primary and frozen section diagnosis, becoming a common procedure in multidisciplinary clinics [1]. While surgical removal of the primary tumor is necessary [2], it is also important to determine the metastatic status and surgical extent of regional lymph nodes. Sentinel lymph node (SLN) sampling or dissection is performed intraoperatively for this purpose [3–5]. When the tumor spreads beyond the primary location, it first drains into the sentinel nodes, making SLN biopsy a significant role in breast cancer cases [6]. Although evaluating frozen sections is more difficult than formalin-fixed paraffin-embedded (FFPE) sections because of inferior quality, the frozen section technique is recommended since it allows immediate consultation during surgery [7]. Recent advances in deep learning algorithms may not only aid in an accurate diagnosis but minimize anesthesia time for patients and labor for pathologists [8,9].
Some deep learning algorithms showing better diagnostic performance than pathologists have been introduced in the CAMELYON 16 and 17 (Cancer Metastases in Lymph Nodes Challenge) competitions [10,11], in which FFPE tissue sections are used. For the validation of frozen sections in metastases classifications, we held the HeLP Challenge 2018 (HEalthcare ai Learning Platform), in which automated deep learning algorithms for detecting metastases in hematoxylin and eosin–stained frozen SLN tissue sections of breast cancer patients were developed [12]. The goal of this challenge was to discriminate between metastatic and normal tissues on digital pathology slides provided by Asan Medical Center (AMC). Four teams submitted their results to the leaderboard in the final stage, and three of them showed considerable area under the curve (AUC) values. However, major limitations of this competition included that all datasets were acquired from a single institution (AMC) and the clinicopathologic characteristics of tumors were randomly distributed among the training, development, and validation sets. The use of datasets from only one institution usually restricts the generalization of the model for multisite deployment owing to a lack of external validation. Different ratios of tumor characteristics in each training, development, and validation set likely cause overfitting to a particular ratio, leading to biased model tuning. Moreover, it is known that breast cancer patients with micro-metastasis (≤ 2 mm) in SLN do not require axillary node dissection [13]. Thus, determining metastatic tumor size in SLN is clinically meaningful.
In the second competition, HeLP Challenge 2019, we expanded our task to determine the presence of metastasis and also measure the longest diameter of the metastatic tumor, if one existed. Additional data were collected from Seoul National University Bundang Hospital (SNUBH) to allow for external validation. In addition, clinicopathologic characteristics of the tumor slides were distributed in the training, development, and validation sets as evenly as possible to balance the ratios among them. As the p-values are calculated, the p-value for each clinicopathologic factors was less than 0.001 except for one, which indicated that the dataset distribution was statistically significant, compared to the previous challenge setting [12]. Through this modified challenge setting, we aimed to evaluate the performance of deep learning models for classifying metastases per slide, measuring the largest metastatic tumor size, and ensuring the adaptability of the external dataset in hematoxylin and eosin–stained frozen SLN tissue sections of breast cancer patients.
Materials and Methods
1. Data description
We acquired 524 digital slides of SLNs from the two different institutions for routine frozen section surgical procedures [14]. At SNUBH, each excised SLN was immediately submitted, cut into 2-mm slices, entirely embedded in optimum cutting temperature compound, and frozen at −25°C. Each 5-μm-thick frozen section was cut, mounted on glass slides, and stained with hematoxylin and eosin (H&E). A total of 227 slides were scanned using a digital microscopy scanner (Pannoramic 250 Flash II, 3DHISTECH Ltd., Budapest, Hungary) in the MIRAX format (.mrxs) with a resolution of 0.389 μm per pixel (MPP) from SNUBH. As already introduced in our previous study [12], the data acquisition protocol was the same for AMC with negligible differences. At AMC, lymph nodes were cut into 2–3-mm slices and frozen at −20°C to −30°C. A total of 297 slides were scanned using a digital microscopy scanner (Pannoramic 250 Flash II, 3DHISTECH Ltd.) in .mrxs format with a resolution of 0.221 MPP. The most important and notable difference between the two institutes was the resolution (MPP) [15].
The dataset comprised 236 slides from AMC as the training set, 107 slides (61 from AMC and 46 from SNUBH) as the development set, and 181 slides from SNUBH as the validation set. The validation set consisted of primarily external institution data, and the purpose was to validate the adaptability of the deep learning models to generalize in external dataset. Each set involved sufficient consideration of the distribution of histologic type. Of the total dataset, 163 slides were obtained from patients who had received neoadjuvant therapy, which would be more challenging to histologically examine [16], prior to submission of the SLN samples for frozen sectioning. Table 1 summarizes the participants’ demographic details.
Table 1
Clinicopathologic characteristics of the patients in the AMC and SNUBH datasets (resolution [width×height] of the digital slide: 93,615×232,948 pixels [AMC] and 56,462×132,956 pixels [SNUBH])
|
Training set AMC (n=236) |
Development set |
Validation set SNUBH (n=181) |
p-valuea) | ||
|---|---|---|---|---|---|
| AMC (n=61) | SNUBH (n=46) | ||||
| Age (yr) | 50 (30–72) | 49 (28–80) | 51 (38–73) | 52 (25–87) | |
| Female sex | 236 (100) | 61 (100) | 46 (100) | 181 (100) | > 0.99 |
| Metastatic carcinoma | |||||
| Size > 2 mm | 113 (47.9) | 30 (49.2) | 18 (39.1) | 65 (35.9) | 0.114 |
| Size ≤ 2 mm | 28 (11.9) | 6 (9.8) | 8 (17.4) | 36 (19.9) | |
| Absent | 95 (40.2) | 25 (41.0) | 20 (43.5) | 80 (44.2) | |
| Neo-adjuvant therapy | |||||
| Not received | 122 (51.7) | 30 (49.2) | 42 (91.3) | 167 (92.3) | < 0.001 |
| Received | 114 (48.3) | 31 (50.8) | 4 (8.7) | 14 (7.7) | |
| Histologic type | |||||
| IDC | 201 (85.2) | 50 (82.0) | 46 (100) | 177 (97.8) | < 0.001b) |
| ILC | 18 (7.6) | 4 (6.5) | 0 | 2 (1.1) | |
| Others | 17 (7.2) | 7 (11.5) | 0 | 2 (1.1) | |
| Histologic grade | |||||
| 1 or 2 | 188 (79.7) | 49 (80.3) | 28 (60.9) | 112 (61.9) | < 0.001 |
| 3 | 48 (20.3) | 12 (19.7) | 18 (39.1) | 69 (38.1) | |
![]()
2. Reference standard
For the AMC dataset, a single rater provided manual segmentation of all digital slides, and two clinically expert pathologists with 6 and 20 years of experience in breast pathology confirmed the annotations. A similar procedure was performed for the SNUBH dataset, where a single rater provided manual segmentation of the digital slides and an expert breast pathologist with 15 years of experience confirmed the annotations. Metastatic carcinomas with regions larger than 200 μm in the greatest digital slide dimension were annotated as the cancers.
3. Challenge competition environment
The platform for the contest was developed by Kakao Brain, and the competitors were allowed to access the data only through the given paths using Docker image files. More details of the challenge platform and environment are introduced in our review of the previous challenge [12]. The competitors were informed about the details of the challenge environment and the dataset two days prior to the start of the competition. They were also notified of the difference between the two datasets from the two institutions, such as MPP, magnification, and staining intensity. However, more details involving the organization of the slides in the dataset were kept undisclosed to ensure fairness of the contest. For the first five weeks of the challenge, 343 digital slides were provided as training and development sets. Annotated masked images were provided in addition to the 236 digital slides of the training set to train the model. For the next two weeks, an additional 181 digital slides consisting of only SNUBH data were opened for the competitors to use as the final validation of their best-tuned models. During this period, the digital slides from the development set were no longer available, as the competitors were not allowed to additionally tune the model based on the development set once the validation set is open. The model’s final performance was submitted to the leaderboard, and the scores and ranks were displayed in real time. Details of the algorithms for each team are presented in S1 Table.
4. Evaluation metric
The algorithms were evaluated for their ability to classify the digital frozen tissue section slides as “metastasis slides” or “normal slides” and measure the size of the longest diameter of the metastatic tumor. For the statistical analysis of the classification task, receiver operating characteristic (ROC) analysis at the slide level was performed, and the AUC was measured to compare the algorithms. As for the size measurement task, the assessment was made in terms of accuracy regarding the size of the largest metastasis. The error range for the size measurement evaluation was ±5%. Positive labels were given for predictions of size within the given error range, while negative labels were given for any other predictions outside this range. These binary labels, either positive or negative, were compared with the labels of metastasis in each digital slide and evaluated in terms of accuracy. This accuracy score was named “Scores of Major Axis” throughout the challenge.
5. Competitors
Registration for this challenge began in mid-November 2019 and lasted for 3 weeks. Ten teams were selected for participation from among the total registered teams. Toward the end of the contest, nine teams submitted their results to the leaderboard for the development set; finally, only four teams submitted their results for the validation set. The top three teams were the GoldenPass, MediTrain, and DeepRunningMachine (DRM) teams, and their methodological descriptions are shown in S1 Table. The results of only these three teams, who demonstrated meaningful outputs, were used for the review and analysis of this challenge.
Results
The model performances were sorted in descending order for the development set and validation set as shown in Tables 2 and 3. Nine teams submitted their results to the leaderboard for the development set, while five teams submitted their results for the validation set. Among them, the results of only the top three teams were considered meaningful because the lower-ranked teams showed AUC values below 0.500, which is too low to be accountable. For the development set, the three teams showed AUC values of 0.901, 0.838, and 0.542 for the slides and 0.523, 0.411, and 0.402 for the major axis. For the validation set, which consisted of 181 digital slides from SNUBH, the GoldenPass team showed the highest AUC (0.891) for the validation set (vs. those of the MediTrain and DRM teams of 0.809 and 0.736, respectively). All teams showed a decrease in AUC when the slides from AMC were eliminated in the validation set except for the DRM team, which demonstrated a large increase in performance for the external dataset only. For the major axis measurement, all teams showed an increase, although small, while the DRM team had a decreased score. A comparison of ROC curves for calculating the AUC values for each team is illustrated in Fig. 1. The first-place team, GoldenPass, showed confidence scores of 0–1 for each inference of their results, whereas the other two teams showed only a binary form of the prediction results with a 0 or 1. This difference is shown in Fig. 1, where the ROC curve of the GoldenPass team shows the staircase phenomenon, while the curves of the MediTrain and DRM teams were drawn from only three points. From the ROC curves, the optimal cut-off threshold was determined by the Youden’s Index to evaluate each algorithm.
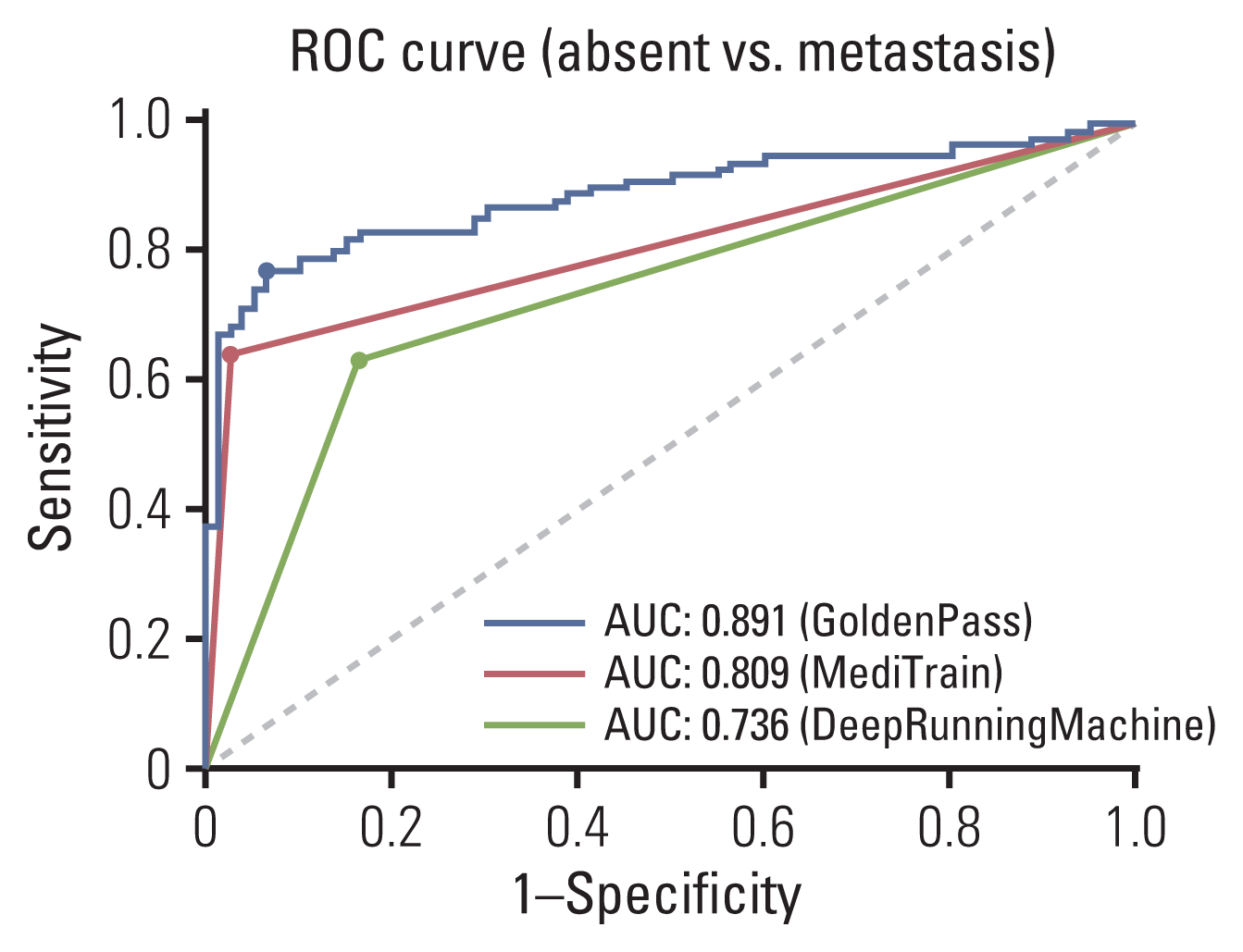
Fig. 1
Receiver operating characteristic (ROC) curve comparisons of models trained by the three algorithms for the validation set. AUC, area under the curve.
![]()
Table 2
Final scores of performances of classification of tumor slides and prediction of major axes
![]()
While the curves in Fig. 1 demonstrate the model performances of classifying normal and metastasis slides, the AUC values and ROC curves, as shown in Fig. 2, were additionally computed for performances of classifying micro-metastasis (≤ 2 mm) and macro-metastasis (> 2 mm). The slides with metastasis smaller than 2 mm were counted as the same label as normal slides in this case, and comparison of AUC values are shown in Table 4, along with the corresponding ROC curves in Fig. 2. When micro-metastases were considered as normal, the top two teams showed higher AUC values, and the values between the teams showed larger gaps. The performance comparison for both evaluations is visually summarized in confusion matrix representation in S2 Fig.
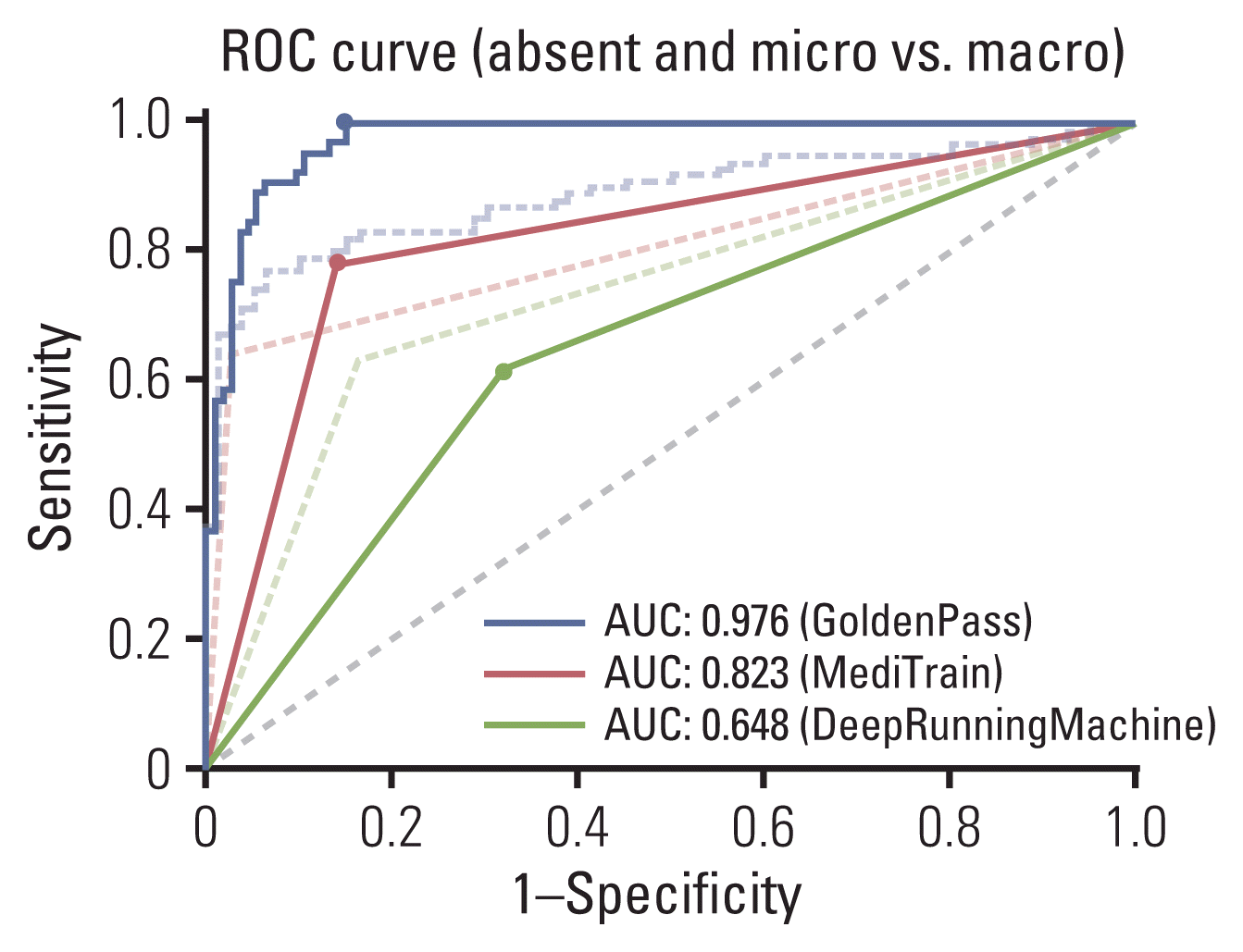
Fig. 2
Receiver operating characteristic (ROC) curve comparisons of models for classifying micro-metastasis as normal (The original ROC curves from Fig. 1 are shown with dotted lines.). AUC, area under the curve.
![]()
Model performance was additionally evaluated by comparing performance according to clinicopathologic characteristics. This clinical information (Table 5) includes the size of the metastatic tumor (whether its greatest dimension is smaller or larger than 2 mm), neoadjuvant therapy status, histologic type, and histologic grade. The top two teams showed a higher true-positive rate (TPR) and a lower false-negative rate (FNR) in slides with metastatic tumors larger than 2 mm, while the third-place team showed the opposite with a higher TPR and lower FNR for smaller metastatic tumor slides. Two teams showed a lower TPR for slides obtained from patients who had not received neoadjuvant therapy, while the other team showed lower TPR for slides of samples from patients with a history of neoadjuvant therapy. Two teams showed a lower true-negative rate (TNR) for slides with a neoadjuvant therapy history, while the first-place team (GoldenPass) showed an especially significant drop in TNR. For cases in which the metastatic carcinoma was invasive lobular carcinoma (ILC), all of the top three teams showed higher TPR and TNR values in contrast to cases of invasive ductal carcinoma (IDC). In terms of comparing performance according to histologic grade, the GoldenPass team showed better performance, although there was a very small difference in the classification of SLN with a histologic grade of 1 or 2, while higher values in both TPR and TNR were obtained for histologic grade 3 for the other two teams with the exception of the MediTrain team, which showed a higher TNR for histologic grade 1 or 2 samples.
Table 5
Performance comparison of determining clinicopathologic characteristics of tumors
![]()
The top three teams correctly classified 100 slides, including 39 true-positive and 61 true-negative, and all three incorrectly classified nine slides as negative (false-negative) among the 181 slides in the validation set. The first-place team had five false-positive slides that the other two teams correctly classified. These wrongly categorized slides are represented in Fig. 3. The second- and third-place teams incorrectly classified one slide as positive (false-positive), while the DRM team incorrectly classified 12 slides as positive. One false-positive slide obtained by the two teams was IDC histologic grade 2 without a history of neoadjuvant therapy. All nine false-negative slides were obtained from patients with the IDC histologic type who did not receive neoadjuvant systemic therapy: six were from patients with histologic grade 1 or 2 cancer, while the other three were from patients with histologic grade 3 cancer. Among those false-negative slides, all nine had micro-metastases (size range, 0.15 to 1.91 mm).

Fig. 3
Representative examples of false-negative and false-positive cases in hematoxylin and eosin stains. (A) A case with micro-metastasis (741 μm in diameter), which was predicted as negative by the three teams (visual field: 9.6×). (B) A case with sinus histiocytosis (shown with arrows) mimicking metastasis, which was predicted as positive by GoldenPass team (visual field: 8.9×).
![]()
Among the 65 lymph nodes with a metastasis greater than 2 mm, the GoldenPass team predicted 44 of them as being larger than 2 mm; of them, 15 were within the allowed error range. The MediTrain and DRM teams predicted 37 and 40 cases, respectively, as being larger than 2 mm, and four and three of them, respectively, were within the allowed error range. For the 36 SLN samples with micro-metastasis, whose size was less than or equal to 2 mm, the GoldenPass and DRM teams did not have predictions smaller than 2 mm, while the MediTrain team predicted 10 of them as smaller than 2 mm, with one being within the given error range.
Discussion
Recent advances in technology and equipment have led to the expansion of digital pathology in many countries. Digital pathology includes primary diagnosis based on whole slide imaging, telepathology, and computer-aided diagnosis using image analysis software [17]. A computer-aided diagnosis is defined as the interpretation of digitized histological images using a computational diagnostic system [18]. Currently, deep learning is generally considered the most promising computer-aided diagnosis method. Computer-aided diagnosis using deep learning methods showed good performance for classification, prognostication, and prediction of breast cancer, prostate cancer, gastrointestinal cancer, skin cancer, etc. [19–24].
Digital pathology has also been implemented and validated for intraoperative frozen section diagnosis [25–27]. For primary diagnosis, most frozen section slides were successfully scanned, and findings of glass and digitalized slides showed excellent agreement. In addition, digital pathology has apparent advantages for consultation since pathologists can save a considerable amount of time and effort if they simply use telepathology instead of actually moving to see glass slides or show them to other pathologists. However, the application of computer-aided diagnosis in frozen section pathology is still in its infancy. There have been several studies on the quantification of steatosis using deep learning for frozen liver biopsy sections [28,29] but few studies on computer-aided diagnosis in frozen section pathology of cancer surgery. Our group previously held HeLP Challenge 2018 to develop a deep learning algorithm for the diagnosis of SLN sections in breast cancer surgery as summarized in the introduction section. We then held HeLP Challenge 2019, which aimed to expand the dataset, measure the metastatic tumor sizes, and improve the overall algorithm performance.
In this study, all of the participants of the top three teams included convolutional neural network–based deep learning methods for classification or segmentation networks, which resulted in adequately high performance with AUC values of 0.891, 0.809, and 0.736. Notably, the performances of the top three teams were better than those of HeLP Challenge 2018, which were AUC values of 0.805, 0.776, and 0.760. We believe that this enhancement could be due to dataset expansion and algorithm improvement. Further data collection and training might enable the implementation of computer-aided diagnosis in frozen section pathology.
The model performances were compared and evaluated according to the clinicopathologic characteristics of the patients. Although the top two teams showed a lower TPR in micro-metastasis than in the macro-metastasis, the third-place team showed a paradoxical result with a higher TPR in micro-metastasis. The models of the top two teams were generally trained well to distinguish metastatic tumor slides, and they showed similar aspects that smaller the tumor sizes, the more difficult it was to classify. On the other hand, while the model of DRM team was not trained generally enough to classify metastatic tumors, the result was in consistence with the previous study that revealed Inception-v1, also known as GoogLeNet, as the best performing network in micro-metastasis [10]. Although it is a previous version of Inception-v4 employed by DRM team, they both share the same inception modules, which may have contributed in robustness in micro-metastasis. Such aspect may have seen amplified since the number of slides for the micro-metastasis was the smallest of the three categories in metastatic tumor size.
A main modification in this second competition was the addition of the dataset from SNUBH to enable the evaluation of deep learning models for adaptability in an external dataset. Interestingly, two of the teams showed higher total scores for the validation set than for the development set. The first-place team, GoldenPass, had a decreased total score in the validation set, but the absolute value of the difference was the smallest among the three teams. In other words, this can be interpreted as the GoldenPass team showing the most similar performance in the development and validation sets. Since the purpose of external validation is to assess the model’s adaptability in a dataset from another domain, such results may be an indication of deep learning model robustness. This might be due to the difference in pre-processing methods, particularly with regard to the handling of input data acquired from two different institutes. As already mentioned in the previous section, the primary difference between the AMC and SNUBH datasets is related to the definite size of each pixel, referred to as MPP, which is determined at the point of slide scanning. If input patches are extracted from the same slide layer level, the patch resolution in the AMC data would be approximately 1.7 times that of the SNUBH data patch. To minimize the influence of this domain gap, the GoldenPass team extracted patches from level 4 for the AMC slides and level 3 for the SNUBH slides and rescaled them. They also applied stain normalization, which can reduce the variations in color and intensity in H&E-stained images obtained at different time points and in different laboratories (S1 Table). This suggests that consideration of the domain gap during the training led to the maintenance of a small change in performance between the development and validation sets.
The model architecture employed by the top two teams involved a feature pyramid network (FPN), known as a multi-scale feature extractor, while the third-place team employed Inception-v4 and support vector machine (SVM). Based on the model architectures, the use of FPN may expect to minimize the influence of MPP difference between the datasets, since the network makes use of feature maps extracted from various scales. This may have contributed in increasing the performance of major axis measurement task. On the other hand, implementation of Inception-v4 and SVM to train the geometric features extracted by the model may have optimized the output for the classification task only. Although the top two teams both equally employed FPN architectures, consideration of MPP in the patch extraction stage by the first-place team may have further contributed to the enhancement in the final performance.
Model performance in the classification task was notably low in slides with micro-metastatic tumors and high in slides with ILC. Pathologists’ manual examination of intraoperative SLN biopsy is generally difficult in cases of micro-metastases and lobular histology [30]; hence, poor performance for discriminating micro-metastatic tumor slides is probable. However, the peculiarly high TNR in slides with ILC may be due to the amount of data in the validation set, which included an extremely low proportion (1.1%) of cases of lobular histology. In addition, the model performance in the major axis measurement task was generally low for all teams. This might be the reason for the strict error range allowed in the contest. An error range ±5% was used to compute the participants’ scores and ranks, but in fact, error ranges of approximately ±15%–20% are acceptable for deter-mining the sizes of metastases in actual clinical examinations. Relatively low major axis prediction scores could be complemented by increasing the allowed error range (Table 6).
For additional analysis, the slides with no metastatic tumor or micro-metastatic tumors only (≤ 2 mm) were considered as negative, and the slides with macro-metastasis (> 2 mm) were considered as positive. There are two reasons for this. Firstly, if frozen biopsy reveals micro-metastases only, then axillary lymph node dissection is not required. Therefore, clinical significance of micro-metastasis is much less than macro-metastasis. Secondly, when annotating tumor areas for this challenge, the pathologist did not annotate metastatic tumor clusters smaller than 2 mm because that was too labor-intensive. This classification could possibly affect the learning ability of tumor detecting algorithms. In such setting, the top two teams showed larger AUC values and the GoldenPass team showed especially large increase, which can be interpreted as that their model was better fit for discriminating the macro-metastasis.
Although the current breast cancer treatment guidelines do not recommend axillary lymph node dissection in the micro-metastasis, some surgeons still prefer to do additional lymph node sampling in the setting of micro-metastasis, or just. Therefore, it might be helpful for pathologists if deep learning algorithms can sensitively detect very small foci of metastatic tumor cells, including micro-metastasis or even isolated tumor cells. We suggest that further studies including more delicate annotation and intense learning process can improve tumor detecting ability of the algorithms.
We held a 7-week-long challenge competition to develop deep learning algorithms for the analysis of digital pathology slides with H&E-stained frozen tissue sections of SLN samples from breast cancer patients. In contrast to the previous challenge we held, here we tried to develop more helpful and practical models for the diagnosis of frozen intraoperative SLN biopsy samples by adding the major axis measurement task and external dataset. The measurement task was to help determine whether the size of a metastasis requires its resection, and an external dataset was used to evaluate the models’ robustness and adaptability to data from another institution. The top three ranked teams achieved high AUC values and acceptably high scores for major axis prediction despite a strictly limited error range in the evaluation. The deep learning models proposed in this challenge may be used for clinical trials in the future to compare the performances between the computer-aided diagnosis versus the pathologist’s examination. Moreover, follow-up studies could be conducted with the expansion cohort to adjust the proposed algorithms into routine clinical practice, which our future works will focus on. Yet, further studies are required to increase the micro-metastases detection accuracy and implement concise and time-saving models for application in routine clinical settings.
 XML Download
XML Download