

 PDF
PDF Citation
Citation Print
Print



INTRODUCTION
Deep learning (DL) is a type of machine learning-based analysis that employs a layered algorithmic architecture. Recent advances in DL have yielded marked success across various domains including, but not limited to, speech recognition, natural language processing, computer vision, and recommendation systems. In the healthcare domain, DL techniques are increasingly applied to medical image processing and analysis, natural language processing of large-scale medical text data, precision medicine, clinical decision support, and predictive analytics.1 DL-based fast computation has dramatically reduced the time for genome analysis facilitating faster drug discovery and development.23 The utilization of machine learning tools to predict disease has been increasingly described.4
Autoencoder (AE) is one of the newer DL techniques that uses an artificial neural network to reconstruct its input data as an output while learning the latent encoding of unlabeled input data. AE’s capability in dimensionality reduction, feature extraction, and reconstruction of the data makes it a particularly effective DL technique to learn complex latent representation.5 Leveraging this strength, one application of AE is DL-based recommender systems (RS) where RS can utilize latent features of recommended items (or latent user-item pair representation) which are learned by an AE. RS has gained popularity in commercial domains such as personalized movie recommendations in streaming services.67
In healthcare, by analyzing patient-level data, RS can be applied to inferring diagnosis or recommending treatments.89 RS can be extended to predictive modeling on a fixed problem such as predicting the relationship between the users and the given item. When built from a large patient dataset, DL-based RS can potentially allow healthcare providers to predict how likely a disease or diagnosis of interest would coexist or occur in the future in a given patient. Such information may prompt healthcare providers and patients to be more vigilant to screen for a disease of interest or to take preventative measures.
However, a challenge might stem from the fact that patient-level data is not uniformly and readily available, as they are highly subject to patient’s utilization of healthcare. For example, if a person rarely utilizes healthcare service, thereby not providing sufficient data input, the use of DL or other machine learning techniques, even if well trained and validated, prediction of disease or condition of interest would not be suitable. Further, even if data is available, complex logistics of accessing and pre-processing of raw healthcare data often make the DL application impractical. Given these challenges, our intention was to experiment the feasibility of prediction of the outcome of interest (disease of interest) using data that are more readily available.
Specifically, we sought to demonstrate how the AE-based RS concept can be applied to predicting a disease of interest. In this study, we tested the hypothesis that gastric cancer (GC) can be predicted by AE-based RS solely based on other documented comorbid conditions available in the National Health Information Database (NHIS). The motivation for GC as a disease of interest was to investigate a disease that is common and relevant to the community from which data originates. GC is the second most prevalent cancer and is the third leading cause of cancer-related death in South Korea.10 South Korea has the highest age-standardized rate per 100,000 of GC in the world. Approximately 244,000 new cases of GC were reported in South Korea in 2018.11 We describe the construction and the performance of a novel AE-based DL model in the prediction of the GC diagnostic code using other diagnostic codes provided by the NHIS.
METHODS
Dataset
We used a medical diagnosis history dataset provided by the Korean NHIS, the government agency in Korea which provides universal healthcare to every South Korean citizen. All medical diagnosis, claims, and bills are submitted to the Korean NHIS, where the data is managed and governed.12 This open data spans over 18 years (from 2002 to 2019) with sample sets differing each year. More recently, the Korean NHIS has begun releasing the dataset to the public yearly.13 This is achieved by random sampling of one million patients and extracting medical diagnosis history data for each patient for a given year. For this study, the latest data from fiscal year 2019 was used. The medical diagnosis history dataset includes demographic profiles and diagnoses based on the International Statistical Classification of Diseases and Related Health Problems (ICD) codes. ICD includes codes for diseases, signs and symptoms, abnormal findings, complaints, social circumstances, and external causes of injury or diseases. ICD codes used in this study were from the Korean Standard Classification of Disease (KCD), the Korean translation of the ICD-10.14
Table 1 summarizes to what each column of the dataset pertains.
Table 1
Medical diagnosis history column from the Korean National Health Information Database

We used randomly sampled one million patients from fiscal year 2019 dataset. The ICD codes collected in 2019 are based on the KCD7 (KCD 7th edition). KCD7 follows the latest ICD-10 from 2014 and has been used since 2016. KCD7 has 22 chapters, which are divided into 267 categories and 2,093 sub-categories. The KCD, analogous to ICD, includes primary diagnosis (“MAIN_SICK”) and secondary diagnosis (“SUB_SICK”). Both primary and secondary ICD codes were considered in the model. The rationale for using only ICD codes in our model was to test whether the model would be sufficiently robust to prediction using only readily available objective data that are uniformly documented and simple to use. Since the ICD code does not specify the timing of the ‘onset’ of the diagnosis, the proposed model does not consider the temporal sequence of the predictors (other diagnoses from year 2019 ICD codes) and outcome (GC diagnosis from year 2019 ICD code). Therefore, the “prediction” of the model described herein refers to the “identification” of the co-existing GC diagnosis using other ICD codes listed in the database (i.e., without considering temporal sequence of the predictors and the outcome).
DL model
AE
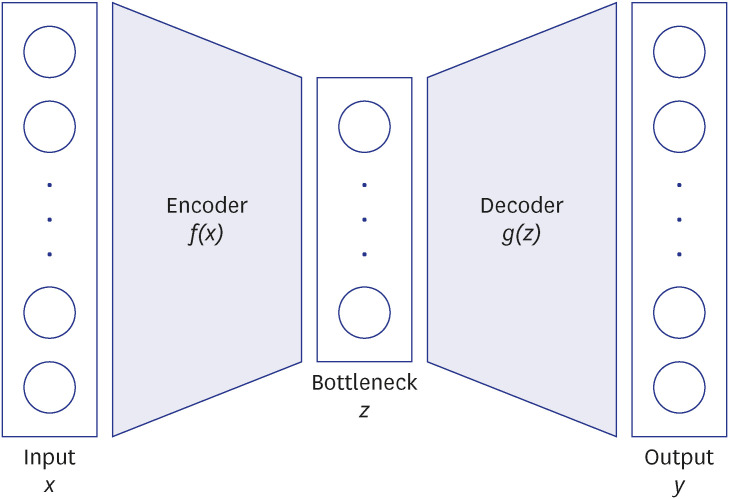
AE is one of the most widely used unsupervised deep neural network models that learns the compression of the input data. It consists of an encoder and a decoder as shown in Fig. 1. The encoder learns how to compress the input data into an encoded representation, while the decoder learns how to reconstruct the original data from the encoded representation. In the simplest form of AE with one hidden layer, the encoder maps the input x to the bottleneck z as shown below:
, where θ represents the parameters of the encoder.
Input x passes through the encoder, which is multiplied by the weight matrix W with the bias b, followed by the activation function sf(·). The output from the encoder, z, has lower dimensionality than the input, x, and in this sense, can be regarded as a compressed representation of x, or a bottleneck. As shown in Fig. 1, the encoder is paired with the decoder which tries to reconstruct the original input data from compressed data z. The function for the decoder is provided below:
, where Wd and bd represent the parameters of the decoder.
The decoder maps the latent representation (z) to y. An AE is optimized by minimizing the error between the input data x and the reconstructed data y. In the DL framework, this can be achieved using the backpropagation by minimizing the error or loss given below:
A single layer AE with a linear activation function is nearly equivalent to Principal Component Analysis (PCA), another popular dimensional reduction method. The non-linear activation function in AE permits flexibility allowing higher performance than PCA. Moreover, AE can be extended in several ways by adding more layers or jointly optimized with other objective functions.
Extension of AE
Deep AE
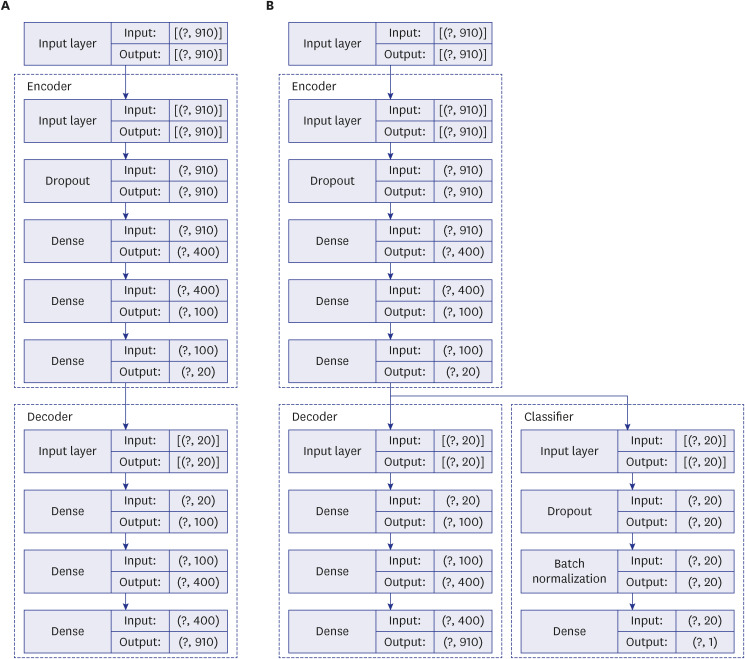
To achieve additional performance gain, we added more layers both to the encoder and decoder. More hidden layers generally yield better compression with smaller error than the vanilla AE. To avoid over-fitting caused by the deep dense layers, various techniques have been proposed including regularizations and drop-out layers. Fig. 2A shows the structure of the deep AE we used throughout our experiments. The output of the encoder (or the input of the decoder) with dimension 20 is the bottleneck layer in Fig. 1.
Supervised AE
Another way of extending the AE is to use AE to learn feature representations, which can be used as an input for the supervised learning model (Fig. 2B).1516 Multi-Layer Perceptron (MLP) can be used for supervised learning using neural network and have shown promising results in many areas.17 The AE and the MLP are optimized to minimize losses in their own network respectively. The AE typically learns the latent representations without any knowledge of its associated labels in unsupervised learning. In our settings, MLP was used to train a classifier to predict a binary label with latent representations as input (AE + supervised MLP [sMLP]). Another novel way of extending AE in supervised learning is to associate the AE and the classifier and thereby minimizing the custom loss function. The custom loss function should include both the loss function from the classifier and the loss function from the AE. The classifier and AE are updated simultaneously in an end-to-end fashion (End-to-End Supervised AE [EEsAE]). Both supervised AE approaches were used and the results were compared.
Model architecture
Our proposed model is based on a supervised AE framework as shown in Fig. 3. Each patient’s ICD codes are fed into the input of the AE and compared to its output of the decoder. The occurrence of ICDs are represented as 0 or 1 so that each patient u ∈{1,...,U} has a binary vector (or multi-hot vector) of size V, where U and V are the total numbers of patients and ICD codes, respectively. As depicted in Fig. 3, the supervised AE consists of two major components: AE and the classifier connected to the bottleneck layer. AE learns the latent representation from the input data, where the latent space dimension is smaller than the input data dimension, V. Our main objective was to test the performance of the model in predicting GC (KCD C16 series). To perform (true vs. false) prediction on a given disease, we designed a classifier using an MLP with one output neuron for prediction. We designed our classifiers by extending the AE with MLP in two ways. In our first approach, we utilized the AE as a tool for constructing features for the MLP input. Instead of feeding the raw multi-hot vectors to the MLP, we performed dimensional reduction using AE as a feature engineering tool (AE + sMLP). Our second approach combined the AE and the MLP by updating the model simultaneously minimizing reconstruction error and prediction error from end-to-end (EEsAE). In this second approach, we updated our model by minimizing the custom loss function which is a linear sum of two loss functions from the AE and the MLP classifier. We also optimized the model with an extra parameter that controls the balance between the two losses, where the ratio between the AE and the classifier works the best when set to 0.8 and 0.2.

Ethics statement
The present study was Institutional Review Board exempt by fitting both of the exempt criteria of 45 CFR 46.101(b)(4). These exempt criteria are: 1) the research involves the collection or study of existing data, documents, records, pathological specimens or diagnostic specimens; and 2) the data sources are publicly available or the data is recorded by the investigator in an anonymous manner such that subjects cannot be identified directly or through identifiers linked to the subject.
RESULTS
Model application to dataset
For each patient, all diagnoses from MAIN_SICK and SUB _SICK were aggregated into a list for building binary patient-diagnosis matrix similar to the context of user-item matrix in RS. We deleted duplicated disease codes for each patient to make a binary value. For example, if a patient had a GC (C16) ICD code in more than one encounter during the year 2019, the model counted it as a GC (yes). For data pre-processing, we included patients with at least 6 different ICD codes with each code found in at least 50 different patients. After this procedure, the total number of patients became 712,050 with 910 distinct ICD codes. We then constructed a binary user-item (or a patient-code in our setting) matrix, where each row and column represent patient and disease code respectively. The matrix M (i; j) (0,1) encodes the individual diagnosis record (true or false) of patient i for disease code j. In machine learning and artificial intelligence literature, the lower dimensional representation of user-item matrix has been extensively studied for RS, which aims to better predict the unobserved user-item interactions. We extended this framework to predict patient’s unobserved ICD codes in a manner that is similar to RS. We built an ICD code-based predictive model using the AE which is analogous to item-based RS, where we implemented using the open-source Tensorflow2. The dataset used for our experiments were randomly split into training, validation, and test sets with the ratio of (0:8; 0:1; 0:1). In other words, 80% of the patients were used to learn the latent representation of patients and ICD codes. We evaluated two model variants. The first model (AE + sMLP) is a supervised learning model with the input learned from the unsupervised learning model. This model used AE as feature engineering tool for an input of a classifier. The classifier predicts whether or not the patient would be diagnosed with C16. After data selection, C16 ICD codes were found in 0.44% of patients. Given the excessive data imbalance between those with and without C16 (i.e., 0.44% vs. 99.56%), we optimized our MLP-classifier using binary cross entropy with weights. The second model, on the other hand, simultaneously updated the parameters in the AE and the connected MLP classifier during the learning process (EEsAE). This model was tested under the setting similar to the first model to compare the predictive performance. With the 10% validation data, we used various dimensions of hidden layers, where each layer is densely connected. Scaled Exponential Linear Units, an activation function that induces self-normalizing properties, was found to be most effective. The output layer consists of a single neuron which is activated by a sigmoid function. The output value from this neuron can be interpreted as the probability of the occurrence of GC: C16. To avoid over-fitting, we added a dropout layer with 0.5 dropout rate and L1 regularization. In the other 10% test data, we hid the information of C16 during testing and compared our prediction with the ground-truth.
We additionally included two other baseline models the eXtreme Gradient Boosting (XGB) and naïve Bayes to be compared with our proposed model. XGB is a scalable tree boosting algorithm which has been favorably used by many winning teams of machine learning competitions. The naïve Bayes algorithm is one of the traditional machine learning algorithms which is interpretable. In naïve Bayes, one can compute the probability of occurrence of a disease of interest given other diagnosis codes through independence assumption. Table 2 summarizes the 4 included models. We evaluated the performance of the four models using various metrics. When testing, we sub-sampled the patients without C16 in a way the number of positive and negative samples are the same. With the sampled test data, we computed precision (positive predictive value), recall (sensitivity), and F1-score by comparing our prediction to the ground-truth. The F1-score is the harmonic mean of precision and recall and is a measure of a model's accuracy on a dataset. We also computed the receiver operating characteristic (ROC) curve area. The area under the curve (AUC) was generated by various thresholds for a classifier and the true-positive rate and false-positive rate. Finally, to better understand the effect of each disease code in the model, an ablation study was performed. Each disease code was removed one at a time from the input neuron of the AE. Based on the degree of impact on the performance measure, we derived the 6 top most influential ICD codes.

Model performance
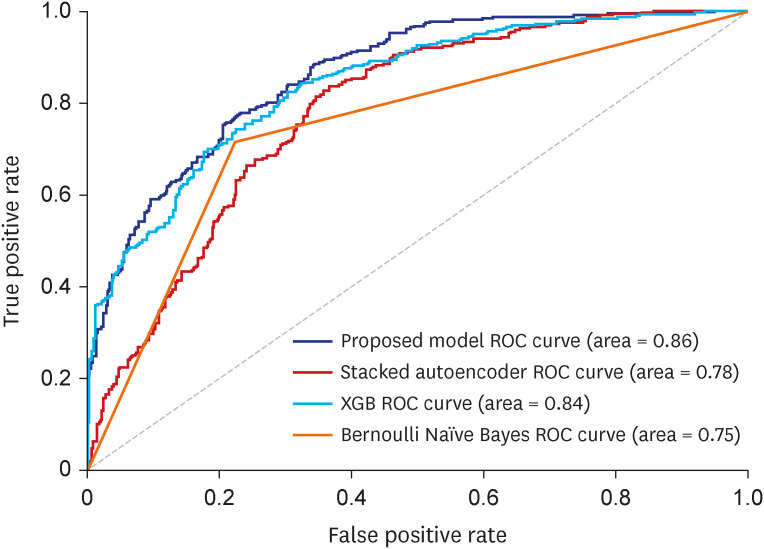
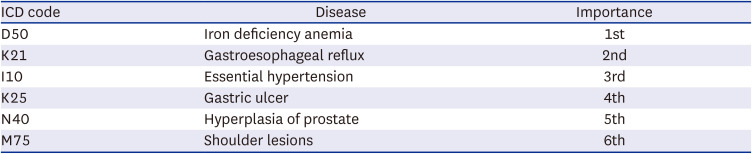
The performance of each model in the testing dataset (N = 1,000,000) is shown in Table 3. The proposed EEsAE model yielded the highest F1-score. AE + sMLP and EEsAE were the best two models with the highest recalls. XGB yielded the highest precision. The AUC of the AE + sMLP concurrent model was 0.862, closely followed by XGB. Fig. 4 shows ROC and AUC, respectively. This demonstrates how our proposed EEsAE outperforms other baseline models in every region. Ablation study results showed the top 6 codes affecting the performance the most (Table 4) including iron deficiency anemia (IDA), gastroesophageal reflux disease (GERD), essential hypertension, gastric ulcers, benign prostate hyperplasia, and shoulder lesion by order of impact on the model performance.
Table 3
Performance of tested models

| Models | ROC-AUC | Recall | Precision | F1-score |
|---|---|---|---|---|
| [EEsAE] | 0.862 | 0.817 | 0.739 | 0.776 |
| AE + sMLP | 0.787 | 0.790 | 0.705 | 0.775 |
| XGB | 0.840 | 0.602 | 0.812 | 0.692 |
| Naïve Bayes | 0.734 | 0.714 | 0.744 | 0.729 |
Fig. 4
ROC-AUC comparison.
ROC = receiver operating characteristic, AUC = area under the curve, XGB = eXtreme Gradient Boosting.
DISCUSSION
We demonstrated the construction and the performance of a novel supervised AE model in combination with MLP classifier in the prediction of disease of interest. The proposed model resulted in superior performances for the prediction of GC compared to other baseline models. Using documented ICD codes as the only input, the model yielded a recall of up to 0.82 in its identification of GC diagnosis. To the best of our knowledge, this is the first application of AE in the prediction of medical diagnosis based on diagnosis code inputs only.
Diagnostic codes are widely used in healthcare systems for the purpose of reimbursement, quality evaluation, public health reporting, and outcome research. Thus, a set of ICD codes typically represents a clinician’s culminating impression that results from various combinations of patient interviews, examination, and objective tests, such as laboratory or radiological studies. Despite the rich information that each ICD code may contain, the complex construct of how each ICD code is linked to other ICD codes requires DL process.
We posited that our proposed model would learn the complex construct and extract salient information sufficiently robust to predict the disease of interest. In doing so, we apply a RS concept of predicting relations of items and users to the problem of predicting the occurrence of disease (item) among patients (users). Herein, the medical history (neighboring ICD codes) represents the input for the RS and the disease of interest represents the fixed problem. The two AE models demonstrated herein are in line with a classic DL technique in which a model is fed with raw data and develops its own representations consisting of multiple layers of representations. Traditionally AE takes the form of unsupervised deep neural network model that learns the compression of the input data. We modified this by extending the AE in a supervised learning environment and combining with sMLP feature. Herein, the model takes advantage of each feature that learns to optimize the network. This enables better capturing of the complex latent representation of the raw data by lower-dimensional representations. We further refined the model by updating the classified and the AE simultaneously in an end-to-end fashion aiming to minimize custom loss function from both the AE and MLP.
The superior performance of our proposed model in recall over baseline models points to the effectiveness of lower-dimensional representations. The AE mapped similar ICD codes into the low dimensional latent space where they are close to each other, and let the classifier discover patterns for predicting the target disease of interest, GC in this study. We also found when the AE and MLP are updated simultaneously as in our proposed EEsAE, the latent representation was even better learned and led to superior performances. The demonstration of F1 score of 0.78, recall of 0.82, and AUC of 0.86 epitomizes the potential of its application in similar predictions. Recall function (sensitivity) is a more relevant metric in prediction of a disease of interest, particularly where screening is important. This implies that about 4 out of 5 people with GC would be detected by the model using coexisting ICD codes alone. One can speculate that such a predictive model can help clinicians raise a high index of suspicion for a certain disease of interest, which is in this case, GC. For example, the model can prompt a clinician to perform more proactive screening of GC. Alternatively, the model may lead to more proactive prevention efforts.
Currently, screening for GC is controversial, and recommendations for screening is dependent on the incidence of GC. In a country where the incidence of GC is excessively high, such as Korea, universal population-based screening is being implemented (e.g., upper endoscopy every 2 years) for individuals aged 40 to 75 years. However, in many other countries where the incidence of GC is low, selective screening of high risk subgroups is advocated. Such high risk groups include those with gastric adenomas, pernicious anemia or familiar adenomatous polyposis, some of which require endoscopy. In that sense, the findings of our study provide a glimpse into how DL, specifically an AE model, might help identify potentially high risk group of patients of GC, who may benefit from more proactive screening with endoscopy especially where the incidence of GC is low.
Prior works have indeed used AE for medical diagnosis.1819 However, the majority of these prior studies utilize AE analysis of medical imaging rather than ICD code. Our model, particularly the use of the EEsAE model, and its application to diagnosis just using ICD code is a first to our knowledge. In the testing phase in the evaluation of our model, all the occurrences and non-occurrences of GC code have been hidden. The disease codes have been aggregated by each patient ID without the information of temporal sequence in occurrences. Therefore, such an inference is still considered prediction. The prediction model is still meaningful in two ways. First, our goal was to better understand the similarity across different diagnostic codes, not the causal relationship in reference to the GC diagnostic code. Given the major clinical implication of the diagnosis like GC, and the challenge in early diagnosis, an AE model that “recommends” GC in this setting can be valuable for clinicians. Second, despite not being able to consider the temporal sequence due to the nature of the data, it actually reflects real world clinical practice where diagnosis is often delayed or even missed. Indeed, the timing of the diagnosis (i.e., first appearance of diagnostic codes) does not equate to the timing of the true onset of the condition.
Despite the potential implication, the findings of the study should be interpreted in the context of how the data was pre-processed. Since a model construction involved only people with at least 6 ICD codes with each code found in at least more than 50 people in the dataset were included, model performance is expected to be poor in people with the scarce number of ICD codes or with relatively rare ICD codes. Moreover, we validated our data in the subcohort from the same year, but have not tested the performance in data from a different year due to the limited availability of the data. Future studies should examine whether a similar level of prediction can be achieved when the model is applied to dataset from another year and for another disease of interest from the data of the same year, as well as different years.
Another limitation of the dataset used in this study is inherent to the limitation of the administrative data. The validity of ICD code varies across different conditions and healthcare systems and depends on how data is collected.20 ICD based diagnosis information is not comprehensive. Moreover, an ICD code does not necessarily reveal the onset of the condition. Code assignment is a demanding process with many potential sources of errors.21 Moreover, ICD code assignment practice is variable among clinicians.
It is equally important to understand the inherent challenge in the interpretation of the results beyond the prediction. While some of the top influencing ICD codes identified in the ablation study appear to have associations with GC, the exact relationship is difficult to interpret. For example, the ablation study revealed IDA as the top influencer in the model meaning that the largest performance reduction was noted when this particular ICD code was excluded. While it seems plausible that there might be a link between the IDA and GC possibly via loss of blood in gastrointestinal track in the setting of gastric pathology, such a link has rarely been documented. One recent study revealed the high prevalence of IDA up to 40% at the time of GC diagnosis.22 Among those who received chemotherapy for GC about 20% developed IDA along their treatment course.23 Prior studies in Korea have simply reported the prevalence of IDA in patients with GC before and after gastrectomy.24 Despite the potential link, specifically how this particular ICD code stood out as the top influencing variable outperforming other variables is unclear. GERD is most closely related to esophageal adenocarcinoma and to a lesser extent to GC arising from the cardia of the stomach.25 Since only the main category of GC, C16, was used without consideration of subcategory information, such as area of the cancer, it is impossible to further speculate how GERD is linked to GC. Unlike other predictors, an association between gastric ulcer and GC can be more readily inferred through common risk factors (i.e., mainly Helicobacter pylori infection).26 Essential hypertension, benign prostate hyperplasia, and shoulder lesions are rather unanticipated diagnoses with little known association with GC. It is very possible that these entities are somehow linked through their associations with common risk factors, confounders, or the consequences of GC treatment. It is important to note that these factors would be more pertinent to the population where the model was trained. Nonetheless, elucidation of influencing factors can potentially enable researchers to explore associations of unanticipated factors with the disease of interest.
This study represents a benchmarking framework for future studies in which additional patient-level characteristics can be added to further enhance the model performance. For example, while this study only included ICD codes in the model, various data including demographics, medical history beyond the diagnosis, and test results can be included to construct even higher performing models.
In conclusion, we describe a novel supervised AE in its application for the prediction of disease of interest. We showed that neighboring ICD code information alone predicted the co-existence of GC with high accuracy. Specifically, the proposed EEsAE model and AE-sMLP outperformed XGB and Naïve Bayes models. While the utility of the AE methods in the prediction of disease of interest (vs. identification of coexisting disease of interest) needs to be evaluated in a prospective study design, this high performance of the proposed model encourages us to further explore its utility and performance in other healthcare domains including future disease prediction.
 XML Download
XML Download