

 PDF
PDF Citation
Citation Print
Print



INTRODUCTION
The coronavirus disease 19 (COVID-19) pandemic is bringing about socio-economic changes, inevitably affecting the overall healthcare system [1]. Effective strategies to curtail the spread of the virus and prevent virus-related increases in morbidity and mortality are urgently needed [2]. In an urgent scenario, drug and vaccine development processes are rapidly evolving and being updated [3], enabling the development of effective treatment methods that are urgently needed. Although developing powerful therapeutic agents for virus control is paramount, in reality, the extended time, high cost, and low success rates associated with new drug development represent major obstacles [4,5]. Recently, several studies have reported that specific drugs previously approved for other purposes might be repurposed to treat COVID-19 [6]. Therefore, the importance of developing a treatment for COVID-19 through drug repositioning (or repurposing) is emphasized, and interest in drug repositioning is increasing.
Drug repositioning is the process of identifying new therapeutic applications for existing drugs and novel treatment methods for untreatable diseases [7]. It is a new drug development method allowing the use of drugs that have already been marketed or proven safe in clinical trials but have not been approved for efficacy reasons [7]. For instance, although sildenafil has been developed to treat angina pectoris through its vasodilator effect, it gained popularity as an erectile dysfunction drug [8]. Finasteride, initially used to treat benign prostatic hyperplasia, is currently used as a hair loss remedy after a dose adjustment [9]. Furthermore, for diabetes mellitus (DM) patients, sodium glucose cotransporter-2 inhibitor (SGLT2i) has been shown to decrease serum triglyceride levels and increase high-density lipoprotein cholesterol levels [10]; however, it cannot be used in hypercholesterolemia patients as it is only prescribed for diabetic patients. Although SGLT2i lowers blood pressure and has a diuretic effect [11], it cannot be used as an antihypertensive medication nor a first-line treatment for heart failure (HF). Glucagonlike peptide-1 receptor agonists (GLP1-RA) have been approved for diabetic patients while also being used in obese patients [12]. In the case of liraglutide, marketed under the name Victoza, it is used and approved for diabetic patients, whereas Saxenda is used and approved for obese individuals (Novo Nordisk, Bagsvaerd, Denmark). Pregabalin, a treatment for diabetic neuropathy, was originally used to treat epilepsy [13]. Overall, drug repositioning can reduce the risk of failures inherent to the early stages of drug development as it relies on drugs that have already been tested.
Early drug repositioning revealed the possibility of redirecting drugs based on serendipity; however, it recently opened up the opportunity to rationally reuse existing drugs [14]. Considering the COVID-19 outbreak as an opportunity, it is necessary to understand drug repositioning and its potential to rapidly unravel new drug uses. However, studies providing detailed explanations of the concept, methodology, and application of drug repositioning are lacking. In this study, we attempted to analyze various drug repositioning methods by retrieving related research reports, discussing the developmental potential of these methods. We also analyzed recent drug repositioning cases that have been implemented, with a particular focus on DM.
LITERATURE SEARCH OF DRUG REPOSITIONING-RELATED REPORTS
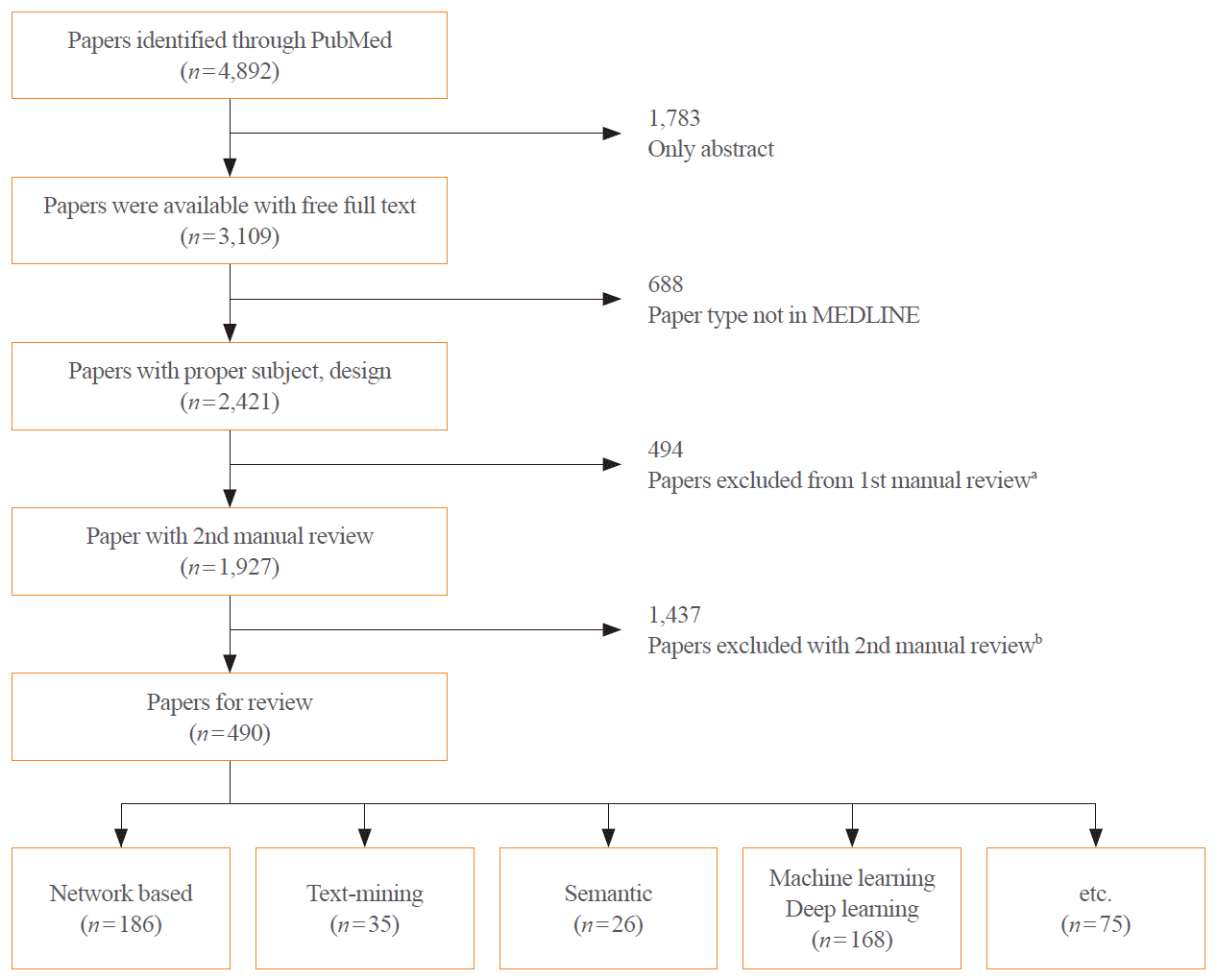
We retrieved articles on drug repositioning and analytical methodologies in the National Library of Medicine (NLM) PubMed database using the “Drug repositioning” [MeSH] OR “Drug Repurposing” [All Fields] OR “Drug Repurposing” [All Fields] keywords (Fig. 1). Studies published from January 1, 2011, to December 31, 2020, were extracted. Of the 4,892 studies, 3,109 were available for download, of which 2,421 were included in MEDLINE. Following review, 494 studies classified as review or systemic review papers were excluded, and the authors conducted a manual review of the remaining 1,927 studies. The exclusion of studies unrelated to the topic yielded a collection of 490 studies. In this process, papers including terms such as ‘machine-learning,’ ‘deep-learning,’ ‘network-based’ were included, encompassing a significant number of methodological papers based on computational approaches. The following papers were excluded: (1) papers containing inappropriate keywords such as “Chinese” and “Herbal” in the title and abstract; (2) reports implementing methodologies such as “active learning” or “case study,” of which a few appeared among computational approaches. Two researchers reviewed abstracts and relevant topics of each report to evaluate the appropriateness of the subject. Of 139 papers for which the two experts had diverging opinions, 91 papers were maintained after discussion, and the remaining 48 were deleted due to a lack of agreement.
After classifying the studies based on the analysis of the drug repositioning methodology, 186 papers were categorized as network-based approaches, 35 were based on text mining, 26 on semantics, and 168 on machine learning/deep learning. In addition to the network-based, machine learning, and deep learning-based approaches, a few studies combined text mining and semantic approaches. Furthermore, it was confirmed that high-throughput screening, virtual screening, and clinical trials are being used in drug repositioning research.
APPROACHES TO DRUG REPOSITIONING ANALYSIS
The main purpose of drug repositioning is to detect new relationships between drugs and diseases [15]. General studies screen for pharmacological actions against new targets and investigate the general properties of drug compounds, such as chemical structure and side effects. In addition, drug repositioning focuses on revealing the similarity between drug effects and modes of action by discovering the relationship between drugs and diseases [3,16,17]. Various approaches have been developed to analyze drug repositioning. Although text-mining and semantic-based approaches are both categorized as data-mining strategies [3], we divided these categories as both fields have recently gained independent importance. Besides, deep learning is a machine learning-based approach that recently grew along with the increased availability of datasets [15]. Therefore, in this study, we classified network-based, text-mining-based, semantic-based, and machine learning/deep learning-based approaches with reference to previous cases [3,15] and presented the corresponding methodologies (Table 1).
Network-based approaches
In the past, the focus has been on exploring the shared properties of drug compounds, such as their chemical structures and side effects. However, recently, to explore the relationship between drugs and diseases, pharmacological, genetic, and clinical data are first considered to explore the relationship between drug compounds [18]. This is based on the hypothesis that similar drugs are usually associated with similar diseases and vice versa. Algorithms are typically implemented to detect structural or network similarities between distinct networks, such as drugs, diseases, proteins, and genes (Supplemental Fig. S1A) [19]. Wu et al. [20] constructed a heterogeneous network of disease-gene and drug-target relationships and weighted diseases and drugs using the Kyoto Encyclopedia of Genes and Genomes (KEGG) database [21,22]. Furthermore, all possible drug-disease pairs (drug re-creation candidates) were assembled to validate predictions. For instance, hydroxychloroquine has been proposed to exert potentially beneficial effects in coronary artery disease due to evidence from a protein-protein interaction network and large-scale patient data [23].
Looking at the research on DM using these network-based approaches, cyclooxygenase-2 (COX2) represents a potential repositioning candidate for type 1 DM treatment [24]. In studies based on electronic medical records (EMR), calcium channel blockers were safely prescribed during pregnancy to effectively treat and prevent gestational DM [25]. Lastly, metformin has shown promise as a therapeutic agent for neurodegenerative diseases [26].
Text mining-based approaches
Text mining is the process of acquiring meaningful knowledge from unstructured documents. Keywords for a specific drug and its targets, pathways, associated disease, and function are used. Based on such keywords, it is possible to reveal the overall research direction regarding the target keywords and obtain new knowledge regarding other keywords associated with the target keyword. The text-mining-based approach extracts and preprocesses text data of interest from literature by recognizing entity terms. A knowledge graph was constructed by identifying the relationships between recognized entity terms [27]. In drug repositioning, the text mining approach recognizes the information and properties of the linguistic context of each biological concept to predict associations and detect new indications (Supplemental Fig. S1B) [27]. Such an approach is effective in predicting the association between drugs and diseases as well as enabling the detection of new indications and side effects of existing drugs [18]. With the development of natural language processing technology, an increasing number of text mining tools are being developed and used to aid drug development [28]. Kostoff et al. [29] derived potential treatments by prioritizing them according to the prevalence and clinical relevance of inflammatory bowel disease in the literature using a text mining approach.
Diflunisal, nabumetone, niflumic acid, and valdecoxib targeting COX2 have been repositioned as therapeutic agents for type 1 DM. In addition, phenoxybenzamine and idazoxan, targeting alpha 2A adrenergic receptor (ADRA2A), have been reported to exhibit therapeutic effects in type 2 DM [30].
Semantics-based approaches
The semantic-based approach is widely used in information and image retrieval due to its effectiveness in predicting drug-disease associations when combined with text mining approaches [18]. A semantic network is built by adding prior information based on the existing ontology network to the information extracted from a large-scale medical database. In this network, mining algorithms are designed to predict new relationships. Although the semantic-based approach has improved the accuracy of predicting biological entity relationships by maximizing the semantic information contained in the vast literature, it is still difficult to integrate and construct various data sources [15]. Zhang et al. [31] discovered potential drugs for Parkinson’s disease by mining the semantic relationships between genes and molecular sequences, chemicals, and drugs. This method can improve the detection of potential relationships between drugs and disorders such as Alzheimer’s disease and cancer. For instance, bromocriptine, with neurotransmitter action, is known to improve blood sugar control [32].
Machine learning/deep learning-based approaches
The literature search revealed that a drug repositioning study based on machine learning was grafted in various fields. A drug is expressed as a vector derived from characteristics such as drug fingerprints, chemical structures, and side effects. Diseases are trained according to various characteristics of drugs and disorders using a machine learning model, and the relationship between them can be predicted using the trained model [18]. In particular, Napolitano et al. [33] suggested three approaches to predict drug repositioning based on machine learning algorithms and showed an accuracy of 78%. Distance of drugs according to the degree of chemical structural similarity, integration of multiple layers of information regarding the proximity of a target within the protein-protein interaction network, and the correlation of gene expression patterns following treatment are some of the characteristics used by the algorithms. Menden et al. [34] developed a machine learning model to predict the response of cancer cells to drug treatment using a combination of cell line genomics and drug chemical structure. This could be useful for personalized medicine by correlating cell line genomics with drug hypersensitivity.
CONSIDERATIONS FOR THE INTRODUCTION OF DRUG REPOSITIONING
This study examined the concept and clinical application of efficient drug repositioning. However, various challenges need to be overcome before achieving clinical use. Aspects to be considered when introducing drug repositioning using these methodologies and data are as follows.
Excluding optimism about clinical applicability
Various studies have reported the effects of drug repositioning; however, it remains difficult to be optimistic about the effect of this method in clinical settings. In one meta-analysis, chloroquine, usually used for systemic lupus erythematosus and rheumatoid arthritis, suppressed the maximum effective virus concentration in a laboratory study; however, high-quality evidence was not confirmed in patients infected with the severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2) [37]. Despite particular cases that benefited from the use of chloroquine, it is difficult to be confident regarding the efficacy of a drug before similar effects are observed in large-scale studies [38,39]. Taking DM as an example, it appears that various antihyperglycemic therapies have other than hypoglycemic effects (Table 2) [10-12,26,36,40-51]. In addition, other types of drugs are likely to help lower blood sugar levels in diabetic patients (Table 3) [13,24,25,30,32,35,52]. In one study, caution was required, as there is no guarantee that the preclinical findings on the neuroprotective effects of DPP4i in acute stroke are identical in clinical practice [53].
Approach utilization based on diverse data sources
In recent years, an increasing number of researchers have attempted to combine computational and experimental approaches to identify new drug uses. By combining various approaches, new indications for drugs have been explored, and the results have been verified through biological experiments and clinical trials. This is supported by the vast amount of data generated by advances in genomics and proteomics. In drug repositioning, it is difficult to evaluate the performance of this method using a one-dimensional approach due to low reliability. Therefore, it is necessary to increase the reliability of the repurposed drugs by approaching and verifying them from multiple perspectives. Furthermore, it is important to efficiently interpret and use large datasets [54]. By combining different types of data sources to discover the potential value of drugs, the discovery time can be shortened, and the efficiency, as well as reliability, can be improved. In particular, large-scale clinical data stored in EMRs and personal health records represent a promising and inexhaustible data source for discovering new drug indications [55].
Intellectual property issues
Intellectual property (IP) is an important problem associated with introducing repositioned drugs. Since IP protection is limited for non-patented drugs, the economic advantages associated with drug repositioning are counteracted by developing new indications for unprotected drugs. Regardless of the brand of the drug, if prescribed in clinical practice, the patient use can be expanded, and tangible benefits can be obtained. However, without a patent, drugs that prove novel indications are often protected by regulatory agencies, so their use might be limited. Furthermore, the researcher or research institution does not hold the license for that specific drug repositioning. For example, new associations between drug and disease targets discovered by researchers have been identified in publications or online databases; however, these are not protected by IP rights. In addition, some drug repositioning projects may be forcibly stopped; thus, wasting time and resources [56]. Because the existing drug commercial model is not discontinued and investment problems can overlap, the development of a new commercial model is sometimes necessary [57]. In such situations, academia, corporations, and regulatory agencies must cooperate to potentially benefit patients.
DATASET FOR DRUG REPOSITIONING
The amount of publicly available biomedical, pharmaceutical, and genomic data is increasing exponentially (Table 4) [21,22,57-80]. Using data from various sources from specific fields (genes, compounds, proteins, drugs, diseases, etc.) reveals associations between field-specific entities. Several computational drug repositioning approaches have been developed as multiple data sources are integrated and used to repurpose existing drugs. To implement each approach effectively, a reliable dataset must first be built [18]. For effective drug repositioning, a database must exist to connect information such as the interaction, similarity, and relevance of various elements. Extensive research efforts on building such databases for drug repositioning are currently in progress. Recently, data-based drug repositioning research has been performed, and electronic health records (EHR), EMR, insurance claim data, genomic data, and drug databases represent good data source examples [81].
Electronic medical records/electronic health records, insurance claim data
EMR data contains disease- and phenotype-related information that can be used as raw data for drug discovery [25,81]. The ability to conduct large-scale follow-up studies related to patient outcomes collected from EMR is an important advantage [82-84]. Medical databases such as EMR and claim data provide health records of millions of individuals, rendering them suitable for discovering new indications for available drugs [85].
Recently, an algorithm was developed to identify drug candidates effective for DM and dyslipidemia by analyzing large amounts of EMR data and clinical trial results [86]. This algorithm can be used to monitor the post-marketing safety of drugs and re-evaluate their effectiveness in clinical trials to ultimately discover new indications [86]. Metformin has been suggested as a repositioning candidate for cancer treatment because it reduces cancer incidence and mortality [41]. GLP1-RA has shown neuroprotective effects, rendering it a candidate therapeutic substance against neurodegeneration [48]. Thus, drug repositioning based on EMR data is most suitable due to the advantage of obtaining large-scale, sophisticated, and structured medical data in a short time [87]. However, sample size reduction problems due to missing data or exclusion of data from multiple patients might still represent a problem for this approach [88]. Furthermore, data quality is often unreliable, and in most cases, preprocessing is required [87,88], ultimately implying a critical privacy issue. To compensate for this, all information that can identify individuals should be removed from the accumulated data, and the extracted information should be stored in an encrypted file and made accessible only to designated persons [83,89].
Genomic data
If the expression of a certain gene changes from baseline in association with a specific disease, a drug that can alleviate this change in gene expression may have a therapeutic effect. Network biology using genomic data is an efficient and high-potential next-generation approach for drug repositioning or drug-todrug combination of existing drugs. From this pharmacological perspective, drug repositioning for genetically rare diseases can be promoted by combining human genetics or genome-wide studies with network biology. In addition, such an approach has been proposed to solve the challenges of personalized medicine along with machine learning approaches [90]. Denny et al. [91] confirmed the association between single nucleotide polymorphism (SNP) and diseases using the diagnostic code of the EMR dataset. A method of confirming the association between a target SNP and disease is called a phenome-wide association study (PheWAS). The PheWAS framework enable taking advantage of the genetic diversity between populations, ultimately making it possible to understand the functional role of specific genes. Therefore, PheWASs might be useful for prioritizing candidate drug targets [90].
For instance, PheWAS provided genetic evidence that GLP1-RA can prevent HF [49]. Furthermore, DPP4i, such as gemigliptin, linagliptin, and evogliptin, reportedly exert antiviral properties, suggesting their potential as broad-spectrum antiviral agents [45]. Another study indicated that SGLT2i play a protective role in the occurrence of AF [46]. Thus, by analyzing the change in gene expression according to the drug, a new point of action or indication of the drug can be identified. Such gene expression information can be obtained for almost any compound or disease regardless of whether the drug is approved or not. Additionally, it is a popular method because even small changes in each drug and disease can be obtained in an objective and detailed manner.
Drug database
Adverse drug reaction (ADR) information can be utilized in a network-based approach using pharmaceutical databases such as the Pharmacogenomics Knowledge Base (PharmGKB) [92], Side Effect Resource (SIDER) [79], and MedHelp [66]. It is possible to research health-related networks, including drugs and diseases, or use drug and disease names as well as ADRs as keywords to reach the relevant social network service. Numerous studies on drug repositioning, including studies investigating biological relationships, have been published. It is sometimes presented as a supporting basis in the method of acquiring new knowledge, such as a text-mining approach and/or semantic approach, ultimately exploring and predicting the relationship between biological concepts or entities. Researchers built a disease-adverse event relationship database using drug-adverse event data extracted from SIDER and drug-disease relationship data extracted from PharmGKB, and identified drug repositioning candidates by measuring the strength of the disease-adverse event relationship [93].
CONCLUSIONS
Drug repositioning is a method of identifying new drug indications by detecting new relationships between diseases and clinically proven drugs in an economical and efficient manner. In addition, repositioned drugs can be released to the market relatively quickly by applying an appropriate approach and analyzing a large amount of diverse data. With respect to drug safety and pharmacokinetics, it has a higher success rate than the traditional drug development method [94], and the resulting indications can be used to treat infectious diseases or cancers. Chen et al. [95]. demonstrated the effectiveness of pyrvinium in liver cancer patients by modeling the inverse correlation coefficient in gene expression and response in cancer patients. According to Paik et al. [96], clinical signatures extracted from EHR show that terbutaline sulfate, a known bronchodilator, can be repurposed to treat amyotrophic lateral sclerosis. Furthermore, an active movement encourages the development of therapeutic drugs for leukemia, Alzheimer’s disease, Parkinson’s disease, and diabetes via drug repositioning. As such, the potential demand and necessity for drug repositioning are expected to increase, and new indications for drugs in various fields, including intractable diseases, are expected to be identified.
Despite various limitations, drug repositioning is a field that will inevitably receive a spotlight in the drug development arena. The process of identifying new therapeutic drugs and treatments for untreated diseases will continue to accelerate. Learning the concept, pros, and cons of various methods used in drug repositioning will pose the basis for implementing new innovative technologies based on scientific evidence, taking into consideration patient safety.
 XML Download
XML Download