

 PDF
PDF Citation
Citation Print
Print



I. Introduction
II. Methods
1. Phase 1: Conversion of Source Data to OMOP-CDM
1) Source data
2) Conversion of source data to the OMOP-CDM
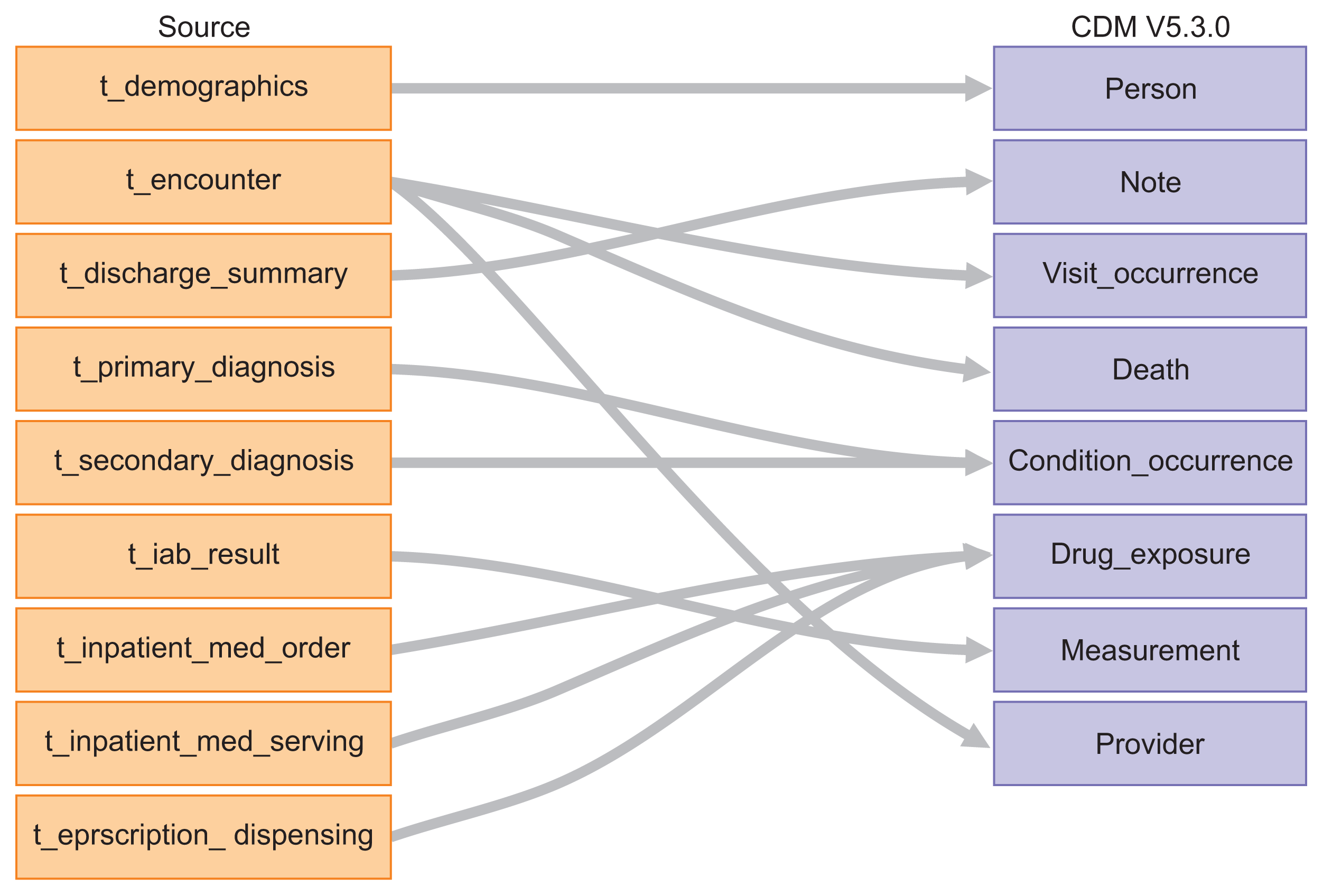
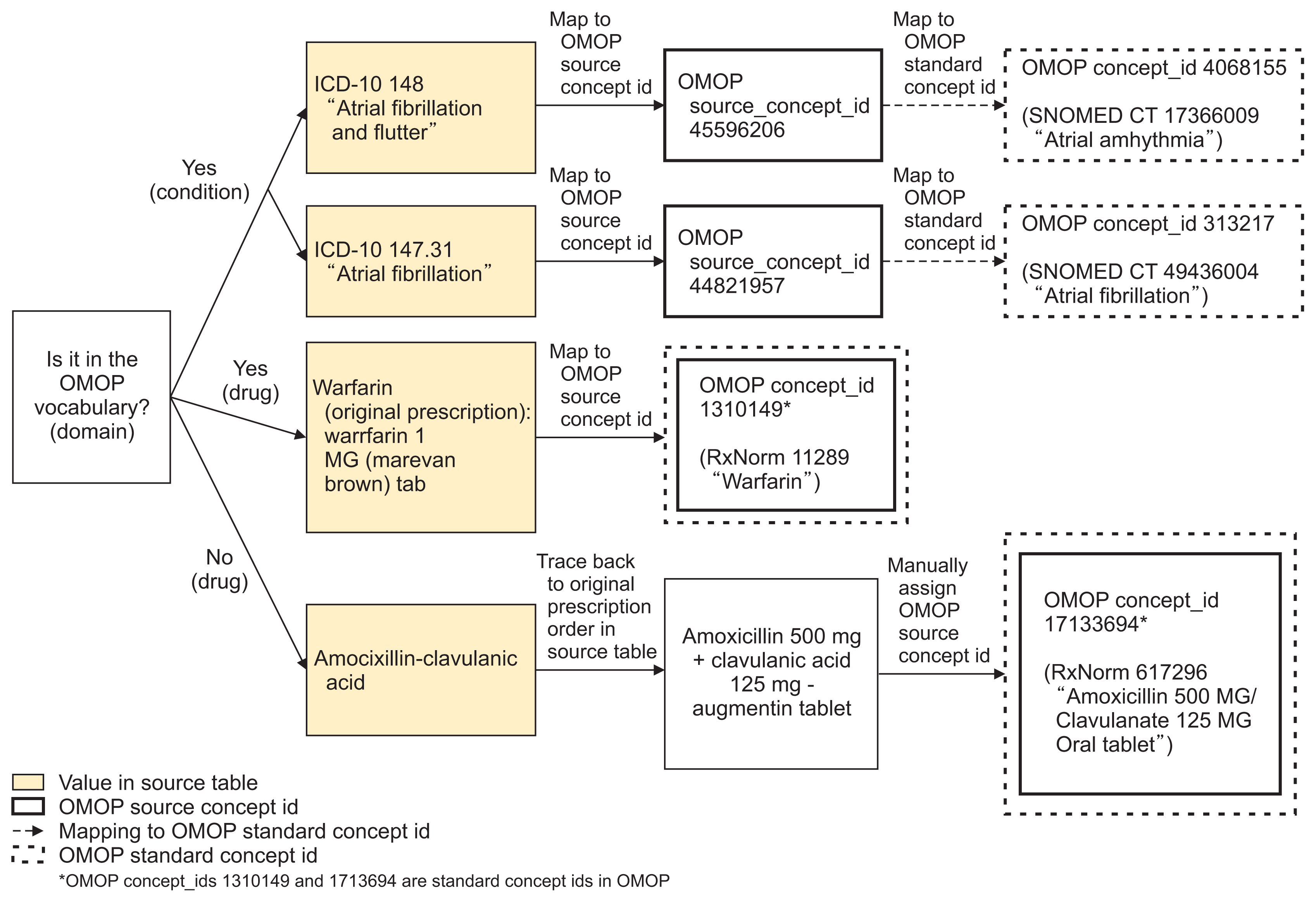
3) Mapping vocabularies from source to target

2. Phase 2: Illustrative Analysis following CDM Conversion
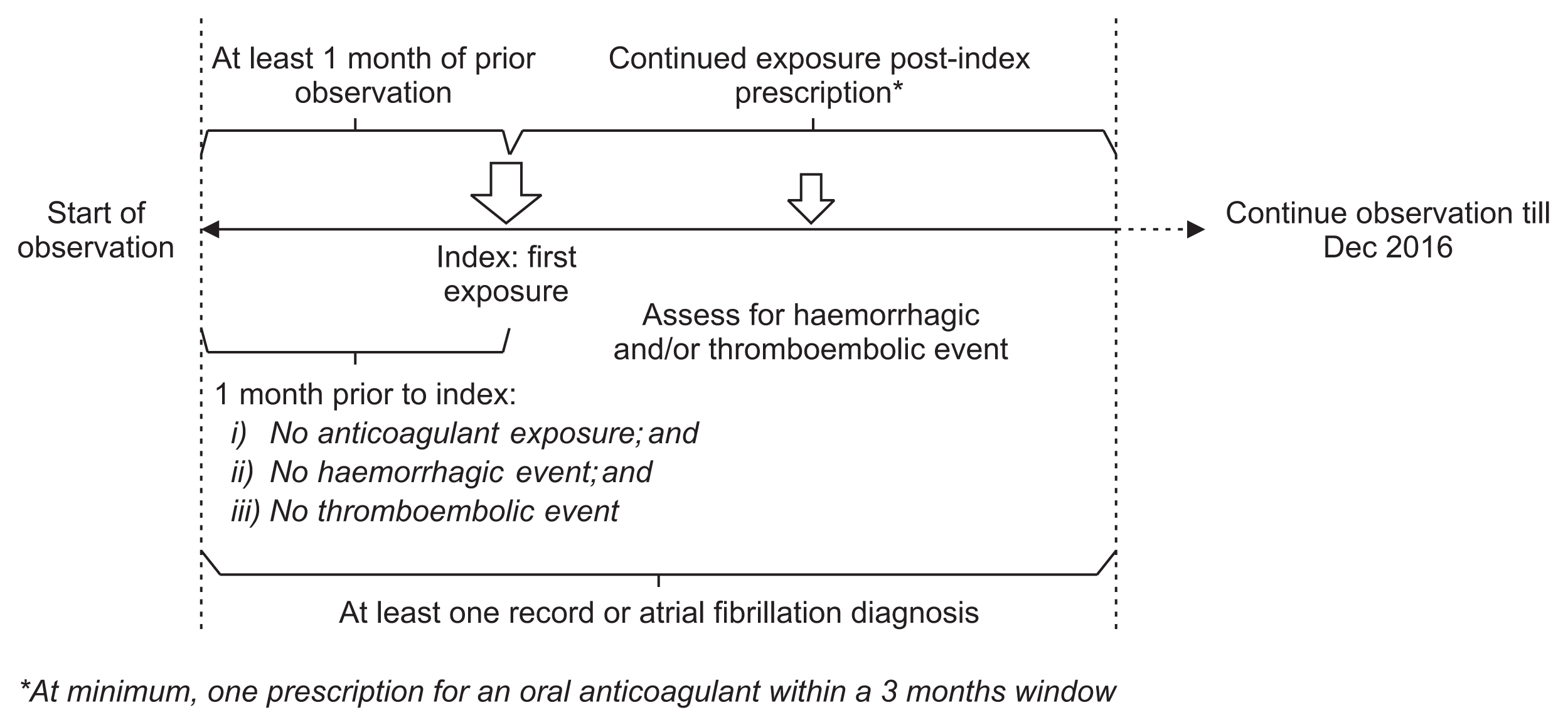
1) Sample cohort assembly and drug exposure
2) Visualizing comparative safety, effectiveness, and utilization for benefit-risk assessments
3) External validation of code on previously converted data and comparisons of the results of the illustrative analysis
III. Results
1. Phase 1: Conversion of Source Data to OMOP-CDM
Table 1
| OMOP-CDM table | Source table | |||
|---|---|---|---|---|
|
|
|
|||
| Table name | Number of rows of records | Table name | Number of rows of records | Proportion migrated (%) |
| person | 245,561 | t_demographics | 258,038 | 95.2 |
|
|
||||
| condition_occurrence | (primary) 210,830 | t_primary_diagnosis | 222,554 | 94.7 |
| (secondary) 799,169 | t_secondary_diagnosis | 839,265 | 95.2 | |
|
|
||||
| measurement | 14,116,544 | t_lab_result | 15,523,576 | 90.9 |
|
|
||||
| visit_occurrence | 1,041,587 | t_encounter | 1,057,263 | 98.5 |
|
|
||||
| drug_exposure | 4,378,657 | t_eprescription_dispensinga | 2,147,505 | 84.8 |
| t_inpatient_med_orderb | 3,015,159 | 84.8 | ||
![]()
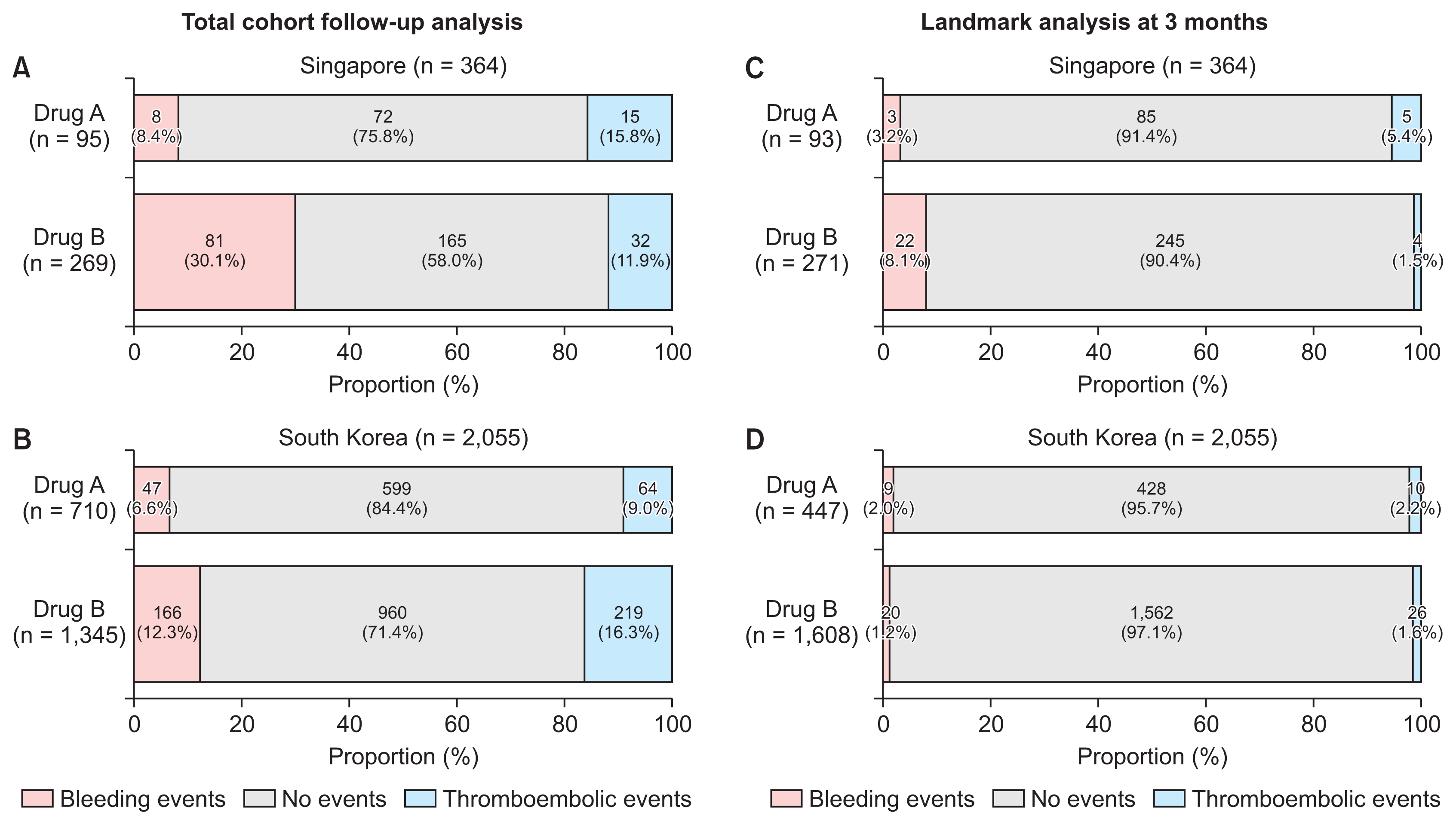
2. Phase 2: Illustrative Analysis
Figure 5
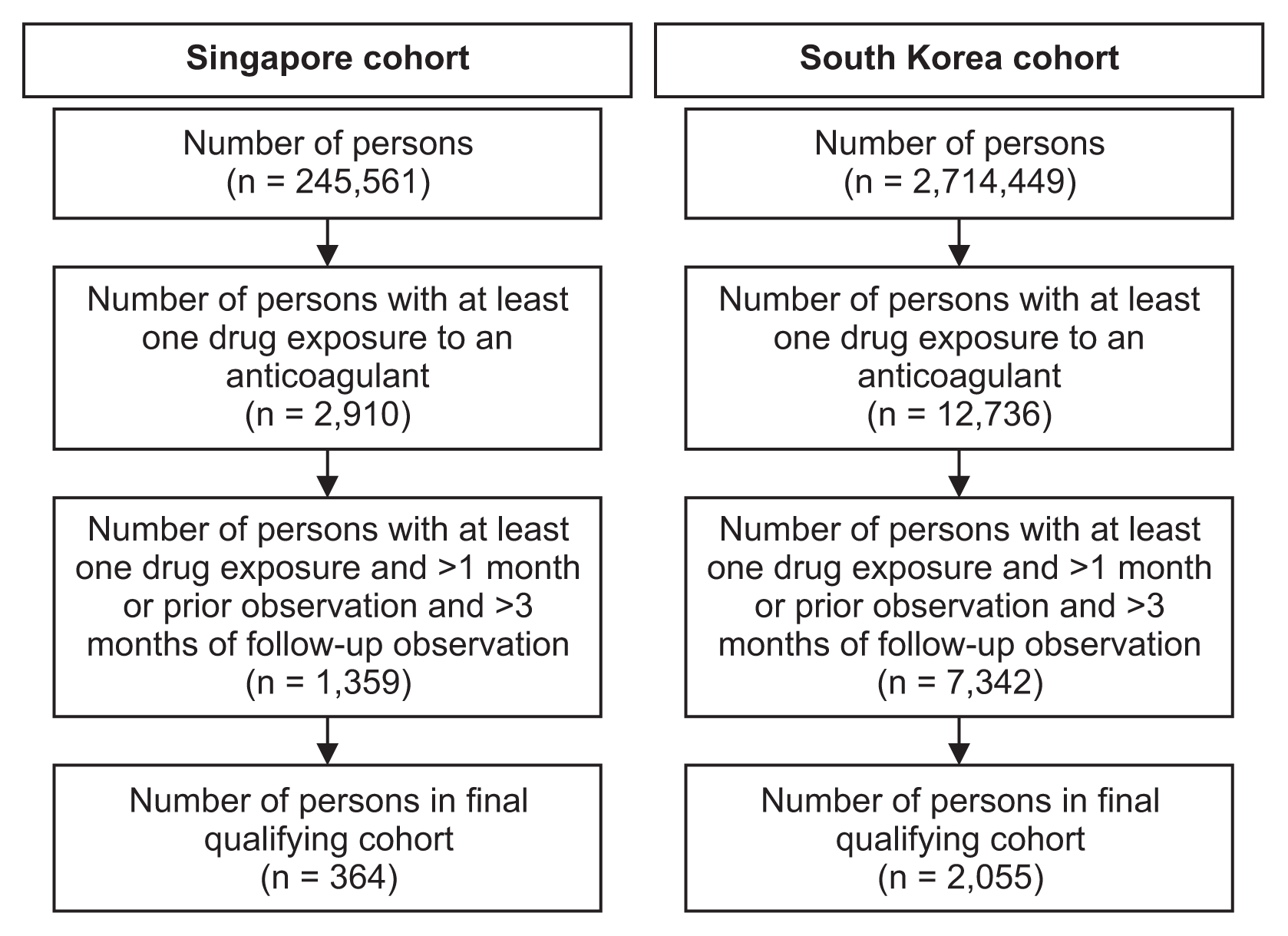
![]()
Table 2
| Warfarin | Rivaroxaban | Combined | p-valued | ||||
|---|---|---|---|---|---|---|---|
|
|
|
|
|||||
| Singapore | South Korea | Singapore | South Korea | Singapore | South Korea | ||
| Number of patients | 269 (73.9) | 1,345 (65.5) | 95 (26.1) | 710 (34.5) | 364 (100) | 2,055 (100) | |
|
|
|||||||
| Age (yr) | 70 (15) | 63 (17) | 71 (15) | 69 (14) | 72 (15) | 66 (17) | <0.001 |
|
|
|||||||
| Sex | <0.001 | ||||||
| Male | 142 (52.7) | 854 (63.5) | 44 (46.3) | 398 (56.1) | 186 (51.1) | 1,252 (60.9) | |
| Female | 127 (47.2) | 491 (36.5) | 51 (53.7) | 312 (43.9) | 178 (48.9) | 803 (39.1) | |
|
|
|||||||
| Race | <0.001 | ||||||
| Korean | NA | 1,345 (100) | NA | 710 (100) | NA | 2,055 (100) | |
| Chinese | 163 (60.6) | NA | 66 (69.5) | NA | 229 (62.9) | NA | |
| Malay | 66 (24.5) | NA | 20 (21.1) | NA | 86 (23.6) | NA | |
| Indian | 20 (7.4) | NA | 5 (5.3) | NA | 25 (6.9) | NA | |
| Others | 20 (7.4) | NA | 4 (4.2) | NA | 24 (6.6) | NA | |
|
|
|||||||
| Event outcomea | <0.001 | ||||||
| Bleeding | 81 (30.1) | 166 (12.3) | 8 (8.4) | 47 (6.6) | 89 (24.5) | 213 (10.4) | |
| Thromboembolic | 32 (11.9) | 219 (16.3) | 15 (15.8) | 64 (9.0) | 47 (12.9) | 283 (13.8) | |
| Neither | 156 (58.0) | 960 (71.4) | 72 (75.8) | 599 (84.4) | 228 (62.6) | 1,559 (75.9) | |
|
|
|||||||
| Concurrent medications (within 7 days before occurrence of bleeding) | NA | ||||||
| Aspirin | 7 (2.6) | 66 (4.9) | 1 (1.1) | 2 (0.3) | 8 (2.2) | 68 (3.3) | |
| Other NSAIDsb | 1 (0.4) | 7 (0.5) | 2 (2.1) | 1 (0.1) | 3 (0.8) | 8 (0.4) | |
| Clopidogrel | 1 (0.4) | 15 (1.1) | 1 (1.1) | 2 (0.3) | 2 (0.5) | 17 (0.8) | |
| Other antiplateletsc | 0 (0) | 1 (0.1) | 0 (0) | 0 (0) | 0 (0) | 1 (0) | |
Values are presented as number (%); for age, the median (interquartile range) are used to indicate the value.
Assignment of patients to drug groupings is based on the latest drug taken by the patient, except in one patient who was on warfarin but who took apixaban for 2 days, and another who was on warfarin but took rivaroxaban for 1 day.
b Other non-steroidal anti-inflammatory drugs (NSAIDs) included for analysis were celecoxib, diclofenac, etoricoxib, ibuprofen, indomethacin, ketoprofen, mefenamic acid, meloxicam, naproxen, and piroxicam.
![]()
Table 3
| Concept ID | Warfarin | Rivaroxaban | |||
|---|---|---|---|---|---|
|
|
|
||||
| Singapore | South Korea | Singapore | South Korea | ||
| Number of patients | 269 (76.5) | 1,345 (65.5) | 95 (19.7) | 710 (34.5) | |
|
|
|||||
| Number of diagnoses | 310a | 1,827 | 105b | 961 | |
|
|
|||||
| Diagnosis (%) | |||||
| Atrial flutter | 314665 | 1 (0.4) | 0 (0) | 0 (0) | 0 (0) |
| Atrial fibrillation | 313217 | 33 (12.3) | 0 (0) | 4 (4.2) | 0 (0) |
| Atrial arrhythmiab | 4068155 | 251 (93.3) | 881 (65.5) | 92 (96.8) | 336 (47.3) |
| Atrial fibrillation and flutter | 4108832 | 13 (4.8) | 0 (0) | 2 (2.1) | 0 (0) |
| Atypical atrial flutter | 36712986 | 0 (0) | 3 (0.2) | 0 (0) | 0 (0) |
| Chronic atrial fibrillation | 4141360 | 0 (0) | 71 (5.3) | 0 (0) | 111 (15.6) |
| Paroxysmal atrial fibrillation | 4154290 | 0 (0) | 772 (57.4) | 0 (0) | 438 (61.7) |
| Persistent atrial fibrillation | 4232697 | 0 (0) | 68 (5.1) | 0 (0) | 60 (8.5) |
| Sick sinus syndrome | 4261842 | 12 (4.5) | 30 (2.2) | 6 (6.3) | 15 (2.1) |
| Sinus node dysfunction | 317302 | 0 (0) | 0 (0) | 1 (1.1) | 0 (0) |
| Typical atrial flutter | 36714994 | 0 (0) | 2 (0.1) | 0 (0) | 1 (0.1) |
|
|
|||||
| Duration (day) | |||||
| Anticoagulant used before occurrence of bleed | 336 ± 296 | 1,501 ± 1,700 | 295 ± 305 | 492 ± 534 | |
| Anticoagulant used before occurrence of thromboembolic event | 369 ± 270 | 1,654 ± 1,527 | 243 ± 238 | 470 ± 436 | |
a 28 of the 269 patients were co-diagnosed with “atrial arrhythmia” (Concept ID: 4068155) in combination with “atrial fibrillation” (313217) and/or “atrial fibrillation and flutter” (4108832), while nine were co-diagnosed with “atrial arrhythmia” (4068155) and “sick sinus syndrome” (4261842) based on EMR, which is a descendant Concept ID based on OMOP. One patient was diagnosed with “atrial fibrillation” (313217) and “atrial fibrillation and flutter” (4108832) while one patient was diagnosed with “atrial arrhythmia” (4068155), “atrial fibrillation and flutter” (4108832), and “sick sinus syndrome” (4261842).
b Six of the 95 patients tagged with “atrial arrhythmia” (4068155) were diagnosed with “sick sinus syndrome” (4261842) based on EMR, which is a descendant Concept ID based on OMOP. Three patients were co-diagnosed with “atrial arrhythmia” (4068155) in combination with “atrial fibrillation” (313217) and/or “atrial fibrillation and flutter” (4108832). One patient was diagnosed with “atrial fibrillation” (313217) and “sinus node dysfunction” (317302).
![]()
Figure 6
![]()
 XML Download
XML Download