

 PDF
PDF Citation
Citation Print
Print


서 론
대상 및 방법
대상자
Table 1.
![]()
녹음 및 분석 방법
Table 2.
F0: average fundamental frequency (Hz), mF0: mean fundamental frequency (Hz), T0: average pitch period (ms), Fhi: highest fundamental frequency (Hz), Flo: lowest fundamental frequency (Hz), SD: standard deviation of F0 (Hz), PFR: phonatory F0-range in semi-tones, Tsam: length of analyzed sample (s), SEG: number of segments computed, PER: total number detected pitch periods, Jita: absolute Jitter (μs), Jitt: jitter percent (%), RAP: relative average perturbation (%), PPQ: pitch perturbation quotient (%), sPPQ: smoothed pitch perturbation quotient (%), vF0: fundamental frequency variation (%), ShdB: shimmer in dB (dB), Shim: shimmer percent (%), APQ: amplitude perturbation quotient (%), sAPQ: smoothed Amplitude perturbation quotient (%), vAm: peakto-peak amplitude (%), NHR: noise to harmonic ratio, VTI: Voice Turbulence Index, SPI: Soft Phonation Index, F1: first formant (Hz), F2: second formant (Hz), F3: third formant (Hz), BW1: first bandwidth (Hz), BW2: second bandwidth (Hz), BW3: third bandwidth (Hz), MDVP: multi-dimensional voice program, ADSV: analysis of dysphonia in speech and voice, CPP: cepstral peak prominence, L/H: low/high, CSID: cepstral/spectral index of dysphonia
![]()
통계 적용
결 과
MDVP 분석결과
ADSV 분석결과
PRAAT 분석결과
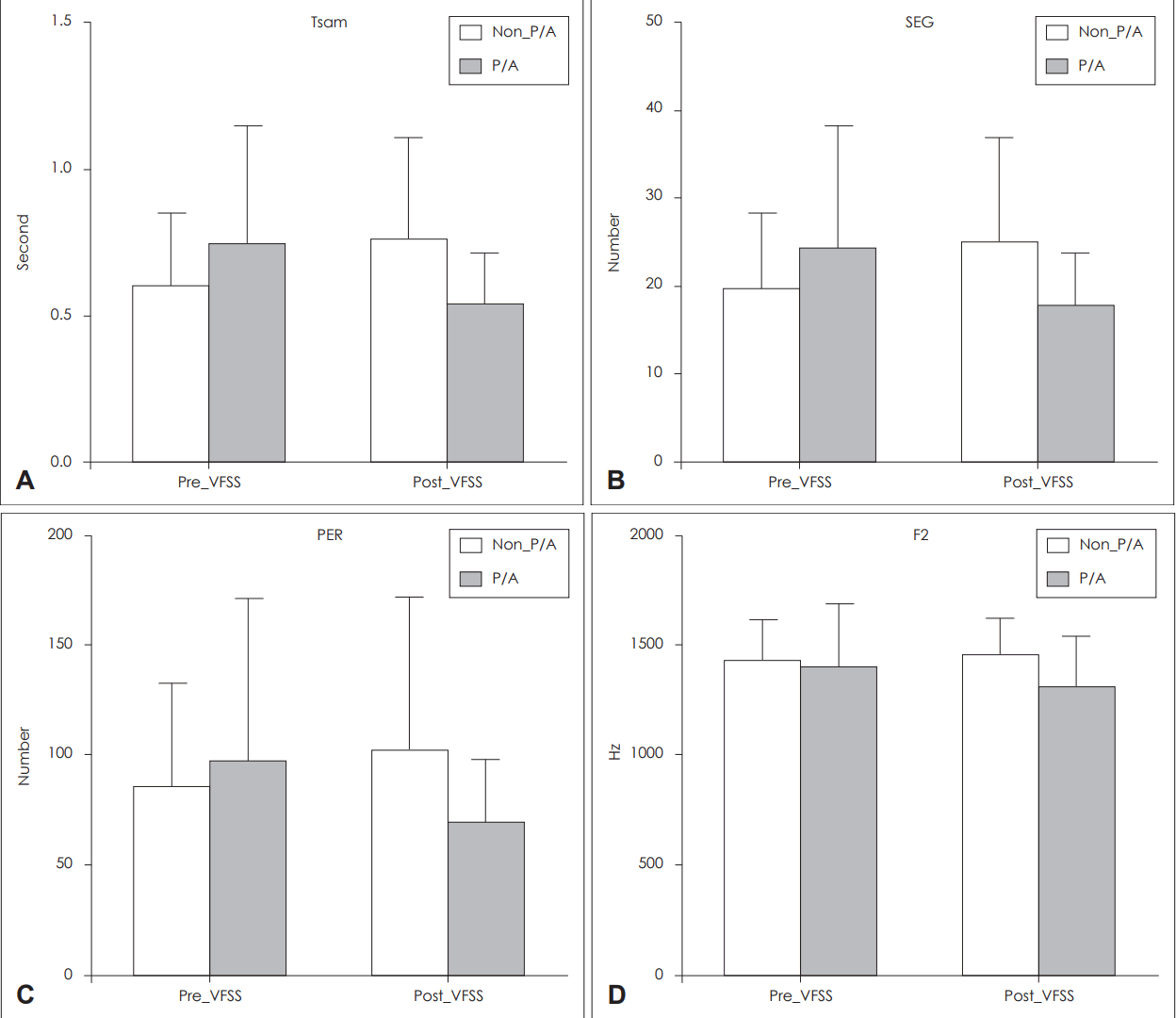 | Fig. 1.Mean & SD of 4 significant parameters pre-and post-VFSS (A Tsam, B SEG, C PER, D F2). A gray bar is for P/A group and a white bar is for Non-P/A group. Tsam: length of analyzed sample, SEG: number of segments computed, PER: total number detected pitch periods, F2: second formant (Hz), P/A: penetration / aspiration, VFSS: videofluoroscopic swallowing study.
|
Table 3.
| Parameters | Z | p |
Mean (±SD)‡ |
|
|---|---|---|---|---|
| Non-P/A | P/A | |||
| Tsam | -2.35 | 0.010† | 0.15 (±0.31) | -0.20 (±0.41) |
| SEG | -2.38 | 0.018* | 5.21 (±10.41) | -7.03 (±13.89) |
| PER | -2.16 | 0.017* | 16.96 (±44.01) | -31.31 (±70.64) |
| F2 | -2.56 | 0.031* | 25.59 (±188.25) | -92.40 (±227.91) |
![]()
삼킴장애 분류정확도
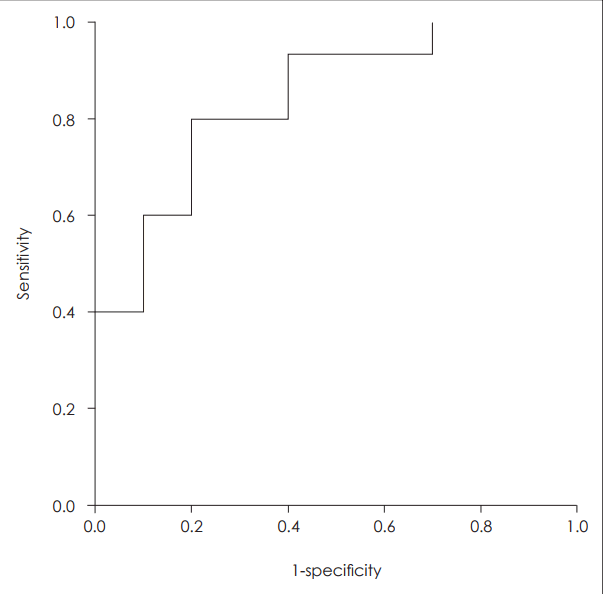 | Fig. 2.ROC curve of four acoustic parameters combination (Tsam+ SEG+PER+F2). X axis is 1-specificity and Y axis is sensitivity. ROC: receiver operating characteristics, Tsam: length of analyzed sample, SEG: number of segments computed, PER: total number detected pitch periods, F2: second formant (Hz).
|
Table 4.
| Parameters | p | Cut-off | Sensitivity | Specificity | AUC |
|---|---|---|---|---|---|
| Tsam | 0.018* | -0.80 | 0.53 | 0.70 | 0.21 |
| SEG | 0.017* | -2.50 | 0.53 | 0.30 | 0.21 |
| PER | 0.031* | 3.25 | 0.33 | 0.50 | 0.24 |
| F2 | 0.010† | -32.26 | 0.41 | 0.20 | 0.20 |
| Tsam+SEG | 0.003† | 0.54 | 0.80 | 0.60 | 0.85 |
| Tsam+PER | 0.020* | 0.51 | 0.80 | 0.60 | 0.78 |
| Tsam+F2 | 0.017* | 0.51 | 0.75 | 0.60 | 0.78 |
| SEG+F2 | 0.017* | 0.51 | 0.73 | 0.60 | 0.78 |
| PER+F2 | 0.040* | 0.53 | 0.73 | 0.60 | 0.74 |
| SEG+PER | 0.015* | 0.51 | 0.80 | 0.60 | 0.79 |
| Tsam+SEG+PER | 0.003† | 0.32 | 0.93 | 0.60 | 0.86 |
| SEG+PER+F2 | 0.013* | 0.47 | 0.86 | 0.60 | 0.80 |
| Tsam+PER+F2 | 0.013* | 0.47 | 0.86 | 0.60 | 0.80 |
| Tsam+SEG+PER+F2 | 0.005† | 0.60 | 0.80 | 0.80 | 0.84 |
![]()
 XML Download
XML Download