Adaptive randomization is a method of changing the allocation probability according to the progress and position of the study. It may be used to minimize the imbalance between treatment groups as well as to change the allocation probability based on the therapeutic effect. Covariate-adaptive randomization adjusts the allocation of each subject to reduce the imbalance, taking into account the imbalance of the prognostic factors. One example is the “minimization technique of randomization (minimization)” to develop indicators that collectively determine the distributional imbalance of various prognostic factors and allocates them to minimize the imbalance.
Minimization11)
Minimization was first introduced as a covariate adaptive method to balance the prognostic factors [
12,
13]. The first subject is allocated through simple randomization, and the subsequent ones are allocated to balance the prognostic factors. In other words, the information of the subjects who have already participated in the study is used to allocate the newly recruited subjects and minimize the imbalance of the prognostic factors [
14].
Several methods have emerged following Taves [
13]. Pocock and Simon define a more general method [
12].
12) First, the total number of imbalances is calculated after virtually allocating a newly recruited subject to all groups, respectively. Then, each group has its own the total number of imbalances. Here, this subject will be allocated to the group with lowest total number of imbalances.
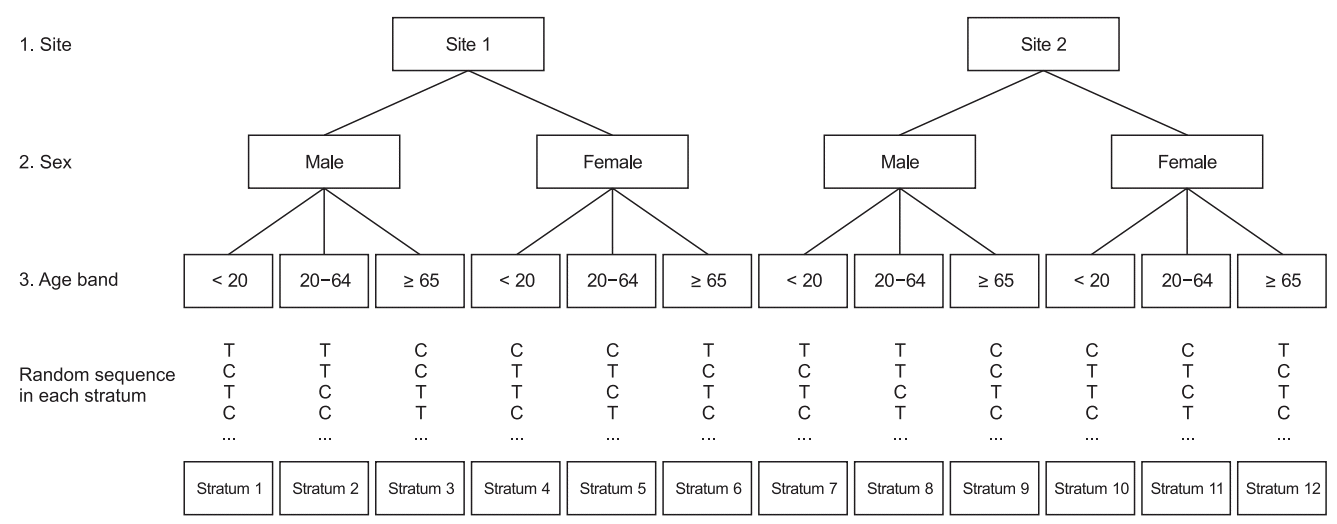
We next proceed with a virtual allocation to the recruitment hospitals (Sites 1 and 2), sex (male and female), and age band (under 20 years, 20–64 years, and 65 years or older) as prognostic factors. This study has two groups: a treatment group and a control group.
Assume that the first subject (male, 52-years-old) was recruited from Site 2. Because this subject is the first one, the allocation is determined by simple randomization.
Further, assume that the subject is allocated to a treatment group. In this group, scores are added to Site 2 of the recruiting hospital, sex Male, and the 20–64 age band (
Table 1). Next, assume that the second subject (female, 25-years-old) was recruited through Site 2. Calculate the total number of imbalances when this subject is allocated to the treatment group and to the control group. Add the appropriate scores to the area within each group, and sum the differences between the areas.
Table 1.
How Adaptive Randomization Using Minimization Works
|
Prognostic factor |
Control group |
Treatment group |
|
Site |
|
|
|
Site 1 |
0 |
0 |
|
Site 2 |
0 |
1 |
|
Sex |
|
|
|
Male |
0 |
1 |
|
Female |
0 |
0 |
|
Age band |
|
|
|
< 20 |
0 |
0 |
|
20–64 |
0 |
1 |
|
≥ 65 |
0 |
0 |

First, the total number of imbalances when the subject is allocated to the control group is
The total number of imbalances when the subject is allocated to the treatment group is
Since the total number of imbalances when the subject is allocated to the control group has 1 point (< 5), the second subject is allocated to the control group, and the score is added to Site 2 of the recruiting hospital, Sex female, and the 20–64 age band in the control group (
Table 2). Next, the third subject (Site 1, Sex male, 17-years-old) is recruited.
Table 2.
How Adaptive Randomization Using Minimization Works
|
Prognostic factor |
Control group |
Treatment group |
|
If allocated to control group |
Site |
|
|
|
Site 1 |
0 |
0 |
|
Site 2 |
1 |
1 |
|
Sex |
|
|
|
Male |
0 |
1 |
|
Female |
1 |
0 |
|
Age band |
|
|
|
< 20 |
0 |
0 |
|
20–64 |
1 |
1 |
|
≥ 65 |
0 |
0 |
|
Total number of imbalances |
[(1 − 1) + (1 − 0) + (1 − 1)] = 1 |
|
If allocated to treatment group |
Site |
|
|
|
Site 1 |
0 |
0 |
|
Site 2 |
0 |
2 |
|
Sex |
|
|
|
Male |
0 |
1 |
|
Female |
0 |
1 |
|
Age band |
|
|
|
< 20 |
0 |
0 |
|
20–64 |
0 |
2 |
|
≥ 65 |
0 |
0 |
|
Total number of imbalances |
[(2 − 0) + (1 − 0) + (2 − 0)] = 5 |
Now, the total number of imbalances when the subject is allocated to the control group is
The total number of imbalances when the subject is allocated to the treatment group is
The total number of imbalances when the subject is allocated to the control group is 2 point (< 4). Therefore, the third subject is allocated to the control group, and the score is added to Site 1 of the recruiting hospital, sex male, and the < 20 age band (
Table 3). The subjects are allocated and scores added in this manner. Now, assume that the study continues, and the 15th subject (female, 74-years-old) is recruited from Site 2.
Table 3.
How Adaptive Randomization Using Minimization Works
|
Prognostic factor |
Control group |
Treatment group |
|
If allocated to control group |
Site |
|
|
|
Site 1 |
1 |
0 |
|
Site 2 |
1 |
1 |
|
Sex |
|
|
|
Male |
1 |
1 |
|
Female |
1 |
0 |
|
Age band |
|
|
|
< 20 |
1 |
0 |
|
20–64 |
1 |
1 |
|
≥ 65 |
0 |
0 |
|
Total number of imbalances |
[(1 − 0) + (1 − 1) + (1 − 0)] = 2 |
|
If allocated to treatment group |
Site |
|
|
|
Site 1 |
0 |
1 |
|
Site 2 |
1 |
1 |
|
Sex |
|
|
|
Male |
0 |
2 |
|
Female |
1 |
0 |
|
Age band |
|
|
|
< 20 |
0 |
1 |
|
20–64 |
1 |
1 |
|
≥ 65 |
0 |
0 |
|
Total number of imbalances |
[(1 − 0) + (2 − 0) + (1 − 0)] = 4 |
Here, the total number of imbalances when the subject is allocated to the control group is
The total number of imbalances when the subject is allocated to the treatment group is
The total number of imbalances when the subject is allocated to the control group is lower than that when the allocation is to the treatment group (3 < 5). Therefore, the 15th subject is allocated to the control group, and the score is added to Site 2 of the recruiting hospital, female sex, and the ≥ 65 age band (
Table 4). If the total number of imbalances during the minimization technique is the same, the allocation is determined by simple randomization.
Table 4.
How Adaptive Randomization Using Minimization Works
|
Prognostic factor |
Control group |
Treatment group |
|
If allocated to control group |
Site |
|
|
|
Site 1 |
4 |
2 |
|
Site 2 |
4 |
5 |
|
Sex |
|
|
|
Male |
4 |
4 |
|
Female |
4 |
3 |
|
Age band |
|
|
|
< 20 |
2 |
2 |
|
20–64 |
2 |
2 |
|
≥ 65 |
4 |
3 |
|
Total number of imbalances |
[(5 − 4) + (4 − 3) + (4 − 3)] = 3 |
|
If allocated to treatment group |
Site |
|
|
|
Site 1 |
4 |
2 |
|
Site 2 |
3 |
6 |
|
Sex |
|
|
|
Male |
4 |
4 |
|
Female |
3 |
4 |
|
Age band |
|
|
|
< 20 |
2 |
2 |
|
20–64 |
2 |
2 |
|
≥ 65 |
3 |
4 |
|
Total number of imbalances |
[(6 − 3) + (4 − 3) + (4 − 3)] = 5 |
Although minimization is designed to overcome the disadvantages of stratified randomization, this method also has drawbacks. A concern from a statistical point of view is that it does not satisfy randomness, which is the basic assumption of statistical inference [
15,
16]. For this reason, the analysis of covariance or permutation test are proposed [
13]. Furthermore, exposure of the subjects’ information can lead to a certain degree of allocation prediction for the next subjects. The calculation process is complicated, but can be carried out through various programs.
Response-adaptive randomization
So far, the randomization methods is assumed that the variances of treatment effects are equal in each group. Thus, the number of subjects in both groups is determined under this assumption. However, when analyzing the data accruing as the study progresses, what happens if the variance in treatment effects is not the same? In this case, would it not reduce the number of subjects initially determined rather than the statistical power? In other words, should the allocation probabilities determined prior to the study remain constant throughout the study? Alternatively, is it possible to change the allocation probability during the study by using the data accruing as the study progresses? If the treatment effects turn out to be inferior during the study, would it be advisable to reduce the number of subjects allocated to this group [
17,
18]?
An example of response-adaptive randomization is the randomized play-the-winner rule. Here, the first subject is allocated by predefined randomization, and if this patient’s response is “success,” the next patient will be allocated to the same treatment group; otherwise, the patient will be allocated to another treatment. That is, this method is based on statistical reasoning that is not possible under a fixed allocation probability and on the ethics of allowing more patients to be allocated to treatments that benefit the patients. However, the method can lead to imbalances between the treatment groups. In addition, if clinical studies take a very long time to obtain the results of patient responses, this method cannot be recommended.


 PDF
PDF Citation
Citation Print
Print



 XML Download
XML Download