

 PDF
PDF Citation
Citation Print
Print



I. Introduction
Heart failure (HF) is a common, chronic, and complex clinical syndrome that significantly diminishes quality of life [1]. The lifetime risk of HF through the ages of 45–95 years is 20% to 45% [2]. More than 37 million people around the world suffer from HF [3]; however, the prevalence of HF varies worldwide. The American Heart Association estimated that the HF prevalence is between 1.26% to 6.7% [4], with the expectation that it will increase by 32% from 2012 to 2030 [5]. In Iran, its prevalence has been reported to be high (8%) [6]. According to the World Health Organization, the annual incidence of HF is estimated to be 660,000 per year worldwide, and this figure is expected to double in the next 30 years [7]. According to previous studies, the HF incidence in Iran is higher than in other Asian countries [8].
Furthermore, HF is a common cause of hospitalization in the adult and elderly population [9]. The annual readmission rate due to HF is quite high, at 56.6% [10]. Approximately 30% of patients experience readmission 30 to 60 days after discharge [11]. Hospital readmission imposes high economic costs for both patients and the healthcare system, and this issue therefore needs more attention due to its negative impacts on healthcare systems’ costs [12].
In the past decade, several machine learning (ML) methods, such as the support vector machine (SVM), least-square SVM (LS-SVM), bagging, random forest (RF), AdaBoost, and naïve Bayes (NB) methods, have been widely applied for the management of cardiovascular diseases. SVM and LS-SVM are kernel-based learning methods that are widely employed for classification and regression problems. These methods have an outstanding capability to solve nonlinear and high-dimensional problems [13,14]. Bagging, RF, and AdaBoost are ensemble learning methods that achieve better learning performance by aggregating several weak learners [14,15]. These ML methods can improve predictions by utilizing higher-dimensional, complex, and nonlinear relationships between variables [16]. These methods also have been used to predict hospital readmission in various studies [5,16–18]. For instance, Lorenzoni et al. [18] compared the performance of eight ML methods to predict hospitalization in HF patients. Their results showed that the generalized linear model net had the best performance. Similarly, Landicho et al. [5] used four ML methods to predict readmission in HF patients. According to their results, SVM had the best performance.
One of the major problems in ML methods for classification is the class imbalance issue. This issue is common in medical data and leads to the poor classification of minority classes. Several methods have been developed to address class imbalance. Among them, the Synthetic Minority Over-Sampling Technique (SMOTE) is a widely used method that was proposed by Chawla et al. [19]. Another common issue in medical research is missing data. There are three types of missing data: missing completely at random (MCAR), missing at random, and missing not at random. If missingness is completely random (i.e., MCAR), it can be ignored [20]; otherwise, removing incomplete data may lead to bias and reduce the power of ML methods [20,21]. To overcome this problem, imputation methods such as median, mean, and multiple imputations can be used [5,18].
ML methods are nonparametric methods that require no distributional assumptions. These methods consider complex and nonlinear relationships among variables. Previous studies have shown positive performance of ML methods in prediction and classification problems [13–15]. However, the performance of these methods is data-dependent, and no single method is always is the best for classification problems [14]. Meanwhile, despite the considerable number of studies in the field of predicting hospital readmission in HF patients, only a few of them have been performed in Iran [8,22]. Hospital readmission not only reduces the quality of life, but also increases medical costs. Therefore, with the increasing prevalence of HF and related readmission worldwide, it is essential to identify HF patients at a higher risk of readmission in order to manage these patients better [12]. Furthermore, in developing countries such as Iran, hospital readmission problems are exacerbated by resource limitations [23]. Hence, this study’s main goal was to compare the performance of six ML methods for predicting hospital readmission in HF patients and to find the best method for our data.
II. Methods
1. Data Collection and Preparation
In this retrospective cohort study, information on 1,856 HF patients was analyzed. These patients were hospitalized in Farshchian Heart Center in Hamadan Province from October 2015 to July 2019. This center is the referral heart center in Hamadan Province in Western Iran. Data were extracted from hospital records using a checklist of items according to the context of the patients’ records and clinical examinations performed by cardiologists. The checklist included data on demographic variables, vital signs, past medical history, and laboratory tests. We extracted all available variables in patients’ records and considered them all. There was a total of 46 variables. The continuous variables were normalized. The outcome was hospital readmission during the follow-up period. The SMOTE method was used for handling the imbalanced dataset problem. This study was approved by the Institutional Review Board of Hamadan University of Medical Sciences (No. IR.UMSHA.REC.1398.276). All patients were informed of the purpose of the study and informed written consent was obtained from all of them.
2. Missing Data
The data used in this study suffered from data missingness, although it should be noted that data were only missing for continuous variables. Hence, two imputation methods were used to deal with missing data: (1) missing values were imputed with the median (median imputation method) and (2) multiple imputations were used (multiple imputation method). Little’s MCAR test was performed to evaluate MCAR.
3. Machine Learning Methods
SVM was proposed by Vapnik [13]. This method tries to construct an optimal hyperplane that separates data points based on their classes. When observations are not linearly separable, SVM converts nonlinear input to a linear state in high-dimensional feature space using a kernel function. The radial basis kernel function was utilized in this study due to its excellent performance. LS-SVM was applied by Tapak et al. [14], such that LS-SVM uses a set of linear equations instead of a quadratic programming problem in the dual space. Further information about the SVM and LS-SVM methods can be found elsewhere in the literature [13,14].
Bagging, one of the earliest ensemble methods, was proposed by Leo Breiman [14]. This method utilizes bootstrap sampling, which involves forming training subsets by randomly resampling the training dataset. A separate classifier-based model is used to train each of the subsets. Then, all classifier-based models are aggregated into the final model [14]. RF is a modification to bagging developed by Leo Breiman and his colleagues [15]. This method fits the number of decision tree classifiers on subsamples of the dataset. The averaging method is then applied to control overfitting and increase accuracy [15]. AdaBoost is one of the first boosting algorithms that was proposed by Yoav Freund and Robert E. Schapire [15]. This method generates a subset of the training dataset and constructs an initial classifier-based model with equal weights assigned for instances. Then, in each boosting iteration, the training instances are reweighted so that the next learner concentrates on the instances that were misclassified previously. The final model is obtained based on a weighted sum of all the classifier-based models [15]. Further details about the bagging, RF, and AdaBoost methods can be found in the above-mentioned references [14,15].
NB is a probabilistic classifier based on Bayes’ theorem with strong independence assumptions between every pair of variables. This assumption is difficult to satisfy in the real world, so it is characterized as “naive.” However, NB performs well, even when the independence assumption is violated [24].
4. Performance Criteria
The discrimination ability of ML methods was assessed using several criteria, including sensitivity, specificity, positive predictive value (PPV), negative predictive value (NPV), and accuracy. The performance of each method was assessed using a cross-validation approach, in which the dataset was randomly divided into training (70%) and test (30%) sets. This procedure was repeated 100 times, and the average values for evaluation criteria were computed.
5. Software Packages
Statistical analysis was performed using R version 3.6.3, with the following packages: “e1071” for SVM; “kernlab” for LS-SVM; “adabag” for bagging, RF, and AdaBoost; “naivebayes” for NB; “randomForest” for variable importance (VIMP) in the RF; “naniar” for the Little MCAR test; and “DMwR” for balancing the dataset.
III. Results
Of the 1,856 HF patients, 542 (29.9%) had at least one hospital readmission. The mean age of these patients was 71.7 ± 13.4 years. The majority of them (64.4%) were men. More than half (57.0%) of the hospital-readmitted patients had a history of hypertension. The characteristics of the HF patients are given in Tables 1 and 2.
Overall, 937 (50.48%) patients had missing data for at least one variable. The most common variable with missing data was ejection fraction (25.59%), followed in descending order by body mass index (19.39%), and creatine kinase-MB (CK-MB) (10.82%). The percentages of missing laboratory test variables were roughly 0.1% to 8%. No other variables had missing data. The results of Little’s MCAR test showed a significance value of less than 0.05, meaning that the missing data were not MCAR.
Tables 3 and 4 show the discriminative ability of the six ML methods for predicting hospital readmission in HF patients with two imputation methods for missing data. The performance of the LS-SVM method, in terms of specificity, PPV, NPV, and accuracy, was higher with the multiple imputation method than with the median imputation method. With the median imputation method, the specificity of SVM was similar to that of RF (0.95). Bagging had the highest specificity among the ML methods (0.96). Bagging and LS-SVM had the lowest and highest sensitivity, respectively. The mean PPV of the ML methods ranged between 0.27 to 0.78 for the test sets, with the lowest and highest values belonging to LS-SVM and RF, respectively. Furthermore, the mean NPV of all ML methods was greater than 0.90. RF outperformed the other ML methods in terms of accuracy (Table 3). Moreover, with the multiple imputation method, SVM and RF had the highest accuracy (Table 4).
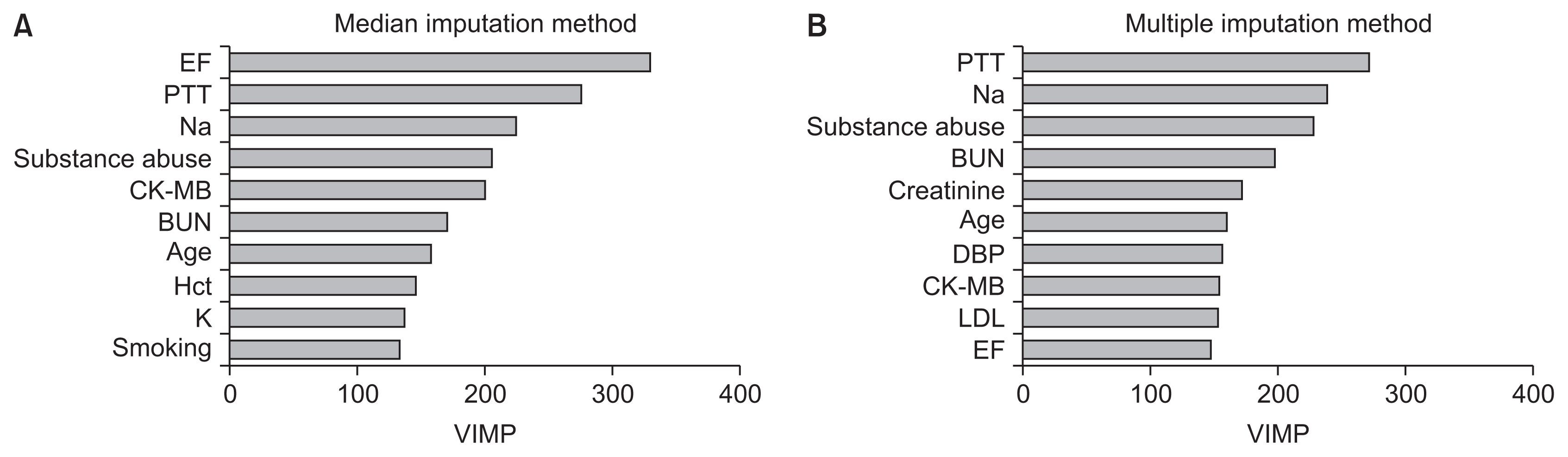
Figure 1 displays the top 10 VIMPs obtained from RF using both imputation methods for missing data. Ejection fraction, prothrombin time (PTT), and sodium were found to be the three most important variables for predicting hospital readmission in HF patients with the median imputation method (Figure 1A). Using the multiple imputation approach, the highest VIMP for RF was PTT (Figure 1B). Ejection fraction, PTT, sodium, substance abuse, CK-MB, blood urea nitrogen (BUN), and age were similarly important variables using both imputation methods.
IV. Discussion
The results of this study show that, in terms of accuracy, RF performed better than other ML methods for predicting hospital readmission in HF patients. Other ML methods, except LS-SVM, had highly similar performance and showed good discrimination, with accuracy in the range of 0.84–0.90.
Various studies have investigated readmission among HF patients using different ML methods. However, it is difficult to compare the results of these studies, because each study considered different characteristics of HF patients. For instance, Landicho et al. [5] compared the performance of logistic regression, SVM, RF, and neural network SVMs to predict hospital readmission in HF patients with a cost-sensitive approach. They found that SVM had better performance than other methods. Similar results were also reported in a study conducted by Artetxe et al. [25]. In another study, Awan et al. [17] used different ML methods to predict 30-day readmission or death with an imbalanced dataset. They showed that the multi-layer perceptron approach had the highest performance compared to other methods. Angraal et al. [26] also found the performance of RF was better than other ML methods. This finding is consistent with our results.
In the current study, we also identified the importance of variables by RF. The results of this method showed that ejection fraction, PTT, sodium, substance abuse, BUN, and CK-MB were important variables for hospital readmission in HF patients. These results are in agreement with previous studies [26–28]. Frizzell et al. [27] compared traditional and ML methods for predicting readmission in HF patients. The results of the logistic regression model indicated that HF readmission was associated with some variables such as BUN, ejection fraction, age, and sodium. These variables were identified as important variables based on RF in our study.
A systematic review by Ouwerkerk et al. [28] also reported that BUN, sodium, and race were the top three most important variables for HF hospitalization. In another study, Angraal et al. [26] showed that BUN was the second most important variable for HF hospitalization. These findings are also consistent with our results, according to which BUN was the fourth most important variable.
Based on our findings, age and creatinine were important variables for HF readmission. Previous studies have confirmed this result [17,18,29]. In a study conducted by Landicho et al. [5], 12 variables were significantly associated with hospital readmission in HF patients. However, none of them were identified as important variables in our study. This may be due to differences in the methods of considering variables between both studies. They used the filter and wrapper feature selection methods, and the initial variables were also different from those used in the present study.
Missingness of data could affect the performance of ML methods. Using imputation methods to deal with missing data may improve the discrimination ability of ML methods. In this study, the performance of the ML methods was highly similar using both imputation methods and showed good discrimination. Lorenzoni et al. [18] showed that the performance of ML methods was better when they excluded missing data. This may have been due to the low percentage of missing data in their study; furthermore, they did not assess whether the missingness was random.
The primary limitation of this study is that the data did not include patients’ medication and psychosocial information, which may have improved the performance of the ML methods. Despite this limitation, our study showed that ML methods had good performance in predicting hospital readmission in HF patients. These results can improve cardiologists’ ability to identify HF patients at high risk for hospital readmission. Identifying high-risk patients provides a valuable opportunity to perform early clinical interventions, which may reduce patients’ risk of readmission. In fact, preventing hospital readmission can improve patients’ quality of life and reduce medical costs.
In conclusion, this study showed that the performance of RF provided better results, in terms of accuracy, than other ML methods for predicting hospital readmission in HF patients.
 XML Download
XML Download