

 PDF
PDF Citation
Citation Print
Print



서 론
여러 언론을 통해 보도된 일련의 조현병 환자에 의한 사건 사고 뉴스에 대해 일반 대중은 높은 관심을 신속하게 나타내었다. 대형 포털 사이트에서는 ‘조현병’에 대한 검색량이 크게 증가하였으며, 상당 시간 동안 검색어 순위에 오르내리기도 하였다. 또한, 해당 기사에 대한 일부 네티즌들의 익명 댓글들을 통해 조현병에 대한 부정적 인식을 거침없이 드러내는 모습이었다. 사건에 대한 대책으로 정부는 환자 동의 없이 추적 관리를 허용하는 등 중증정신질환자 지역사회 치료 지원 강화 방안을 내놓았고[1], 대한조현병학회는 조현병에 대한 사회적 낙인이 확산되는 것에 대한 우려를 성명서를 통해 발표하기도 하였다[2]. 그러나 이미 신문과 방송 등 기존 언론은 물론 소셜 미디어와 포털 사이트 등 인터넷 언론을 통해 빠르고 넓게 전파된 사건 사고 뉴스들은 조현병 환자에 의한 폭력 문제를 일반 대중에게 인지시키는 역할을 하였다.
정신질환에 대한 사회적 편견은 조현병 환자들의 재활과 사회 복귀를 제한하는 주요 요인이다[3,4]. 편견이란 부정적이거나 잘못된 정보에 의해 형성된 특정인에 대한 태도로, 과거에 편견은 주로 본인이 직접 경험하거나, 주변 사람들을 통해 학습되거나, 또는 사회집단에서 오래 동안 유지되어 온 것들로 부터 형성되었다[5,6]. 그러나 오늘날에는 매스 미디어에 의해 개인이 영위하는 집단과 경험의 범위가 빠르게 확대되고 있으며, 이를 통해 전달된 정보와 경험들은 편견을 형성하고 확산하는데 크게 기여할 수 있다[7]. 앞서 언급한 바와 같이, 조현병 환자에 의한 사건 사고 소식들도 다양한 미디어를 통해 빠른 속도로 전파되고 있으며, 일반인들은 사건에 대한 간접 경험을 통해 조현병 환자에 대한 부정적 인식과 편견을 형성하게 된다. 기술의 혁명적 발전과 그에 따른 사회적 변화 가운데 사회 구성원으로서의 조현병 환자들의 입지는 앞으로 더욱 줄어들지도 모르는 현실 속에서, 관리 밖의 조현병 환자에 의한 사건 사고들은 조현병에 대한 부정적 인식과 사회적 편견을 빠르게 확산시키고, 결국 성실히 치료 받고 재활 중인 환자들의 사회 복귀를 더욱 어렵게 만들 수 있다.
요약하면, 조현병 환자에 의한 사건 사고는 언론의 주목을 끌 수 있는 소재로, 미디어를 통해 매우 빠른 속도로 전파되고 있으며, 이에 따른 조현병에 대한 부정적 인식과 편견의 확산이 우려되는 상황이다. 이에 본 연구에서는 조현병과 관련하여 어떠한 내용들이 언론 매체를 통해 전달되고 있는지를 확인해 보고자 하였다. 기존의 내용 분석(content analysis)에 기반한 언론 연구들은 많은 시간과 비용이 요구되고, 연구자의 주관이 반영될 수밖에 없다는 한계가 있었다[8]. 대신, 본 연구에서는 텍스트 마이닝(text-mining)이라는 프로그래밍 기법을 활용하여, 보도 기사를 통해 수집된 비정형 텍스트 자료들로부터 특정 패턴과 의미 있는 정보를 추출하고자 하였다. 텍스트 마이닝은 인간의 언어로 이루어진 비정형 텍스트 데이터들을 자연어 처리(natural language processing) 방식을 이용하여 대규모 문서에서 정보를 추출하거나, 연계성을 파악하거나, 분류 혹은 군집화, 요약 등 데이터에 숨겨진 의미를 발견하는 기법을 말한다[9]. 본 연구에서는 10개 주요 일간지에서 ‘조현병’을 검색어로 검색된 지난 2년간의 지면 기사를 수집하여, 빈도 분석(frequency analysis)과 동시 출현 단어 분석(co-occurrence network analysis), 그리고 토픽 모형 분석(topic model analysis)을 통해 조현병 관련 기사에서 등장하는 주요 키워드와 토픽을 파악하였다.
Go to : 
방 법
텍스트 데이터 사전 처리
일차적으로 연구자 2인의 검토를 통해 579건의 기사 중 인사, 부고, 운세 등 관련성이 낮은 기사 4건을 제외한 총 575건의 기사를 최종 선택하였다. 그리고 기사 본문 텍스트에서 신문사나 기자 이름 등 분석 시에 불필요한 단어는 텍스트 자료에서 삭제하였다. 텍스트 마이닝에 의한 텍스트 데이터 사전 처리 과정은 다음과 같다. 우선, R의 tm 라이브러리를 이용하여 기사 텍스트 자료에 대한 말뭉치(corpus)를 구성하였다[12]. 그리고 말뭉치 텍스트 데이터에서 숫자, 알파벳, 문장부호, 그리고 특수문자들을 삭제하였다. 이후, NIADic 한글형태소 사전을 기반한 KoNLP 라이브러리의 함수를 이용하여 말뭉치 텍스트 데이터에서 2~8음절의 명사만을 추출하였다[13]. 추출된 명사들의 빈도표를 확인하여 발현 빈도가 높은 단어 가운데, 분석에 불필요할 것으로 판단되는 단어는 추가로 삭제하였으며(예: ‘올해’, ‘지난해’, ‘과거’ 등), 중복된 의미를 갖는 단어들은 하나의 단어로 통일시켰다(예: 신경정신과, 정신과 → 정신건강의학과, 정신건강복지센터, 정신건강센터 → 정신건강증진센터).
상기의 사전 처리를 거친 말뭉치에 대하여 tm 라이브러리를 이용하여 문서×단어 행렬(document-term matrix, DTM)과 단어×문서 행렬(term-document matrix, TDM)을 구축하였다. DTM과 TDM 모두 특정 문서에 등장하는 특정 단어의 등장 빈도를 행렬로 나타내는 것으로, 본 연구에서는 행렬에 대한 가중치(weighting)로 단어 빈도(term frequency, TF), 바이너리(binary) 가중치, 그리고 단어 빈도-역문서 빈도(term frequency-inverse document frequency, TF-IDF)를 분석 방법에 따라 적용하였다. TF는 특정한 단어가 어떤 범위 내의 문서에서 얼마나 자주 등장하는 지를 나타내는 값으로, 특정 단어의 빈도수가 높으면 문서 내에서 해당 단어가 중요하다 생각될 수 있다. 바이너리 가중치는 해당 단어가 텍스트에 출현하면 1, 아니면 0을 반환하는 방법이다. 문서 빈도(document frequency, DF)는 특정 단어가 일정 문서들에서 얼마나 자주 사용되는지를 나타내는 값으로, 단어가 나타나는 문서의 수가 많을 수록, 그 단어는 보편적인 단어임을 의미한다. 역문서 빈도(inverse document frequency)는 DF의 역수이다. TF-IDF는 TF와 IDF의 곱으로, 여러 문서로 이루어진 문서군이 있을 때 어떤 단어가 특정 문서 내에서 얼마나 중요한 것인지를 나타내는 가중치 값이다[14].
빈도 분석
DTM을 이용하여 추출된 명사들의 TF-IDF에 대한 빈도표(frequency table)을 계산하였다. 그리고 가시성을 고려하여 TF-IDF 기준 상위 50개의 단어에 대해 말구름(word cloud)을 구성하였다. R의 wordcloud2 라이브러리를 이용하였으며, 말구름에서 단어의 글자 크기가 클수록 해당 단어의 TF-IDF 값이 높다는 것을 의미한다[15].
토픽 모형 분석
하나의 문서는 여러 개의 토픽을 지닐 수 있고, 하나의 토픽은 해당 토픽에서 이용되는 단어의 비율로 표현될 수 있다. 토픽 모형 분석은 문서와 단어로 구성된 행렬을 기반으로 문서에 잠재되어 있다고 가정된 토픽의 등장 확률을 추정하는 일련의 통계적 텍스트 처리 기법을 일컫는다[14]. 많이 사용되는 토픽 모형으로는 잠재적 디리클레 할당(latent Dirichlet allocation, LDA) 모형, 상관 토픽 모형(correlated topic model, CTM)과 구조적 토픽 모형(structural topic model, STM) 등이 있으며[18-20], 본 연구에서는 LDA 모형을 이용하였다. LDA 모형은 단어의 사전 분포와 텍스트의 사전 분포가 있음을 가정하는 베이지안(Bayesian) 기법을 통해 단어와 텍스트의 분포를 추정하여 해당 문서의 주요 단어와 분류를 추측하는 방법이다[19]. LDA 모형은 TF 가중치 DTM을 이용하여 구성되며, 본 연구에서는 R의 lda 라이브러리가 사용되었다[21]. 전체 기사의 10% 이상에서 공통적으로 사용되는 단어들로 구성된 TF 가중치 DTM을 사용하였으며(sparsity<90%), 잠재 토픽의 개수(k)는 10개로 가정하여 Griffiths와 Steyvers[22]의 제안에 따라 외부 모수 α값은 5 (50/k)로 정하였다. 그리고, 깁스 샘플링(Gibbs sampling) 방식으로 LDA 모형 구성을 10,000회 반복하였다.
Go to :
결 과
분석에 사용된 전체 575건의 조현병 관련 기사 중 2018년과 2019년 기사는 각각 148과 427건이었다. 한국일보가 총 101건으로 가장 많은 기사를 실었으며, 경향신문, 동아일보, 서울신문, 조선일보, 국민일보, 문화일보가 각각 50건 이상의 기사를 보도하였다(표 1). 기사들의 사전 처리를 통해 총 23,631개의 단어가 추출되어 분석에 사용되었다.
빈도 분석을 통해 TF-IDF 기준 상위 50개 단어를 확인하였으며, 이를 시각화한 말구름은 그림 1과 같다. 이들 단어 중에서, ‘경찰(8.38),’ ‘정신질환(5.78),’ ‘입원(4.79),’ ‘환자(4.78),’ ‘범행(4.51),’ ‘아파트(4.45),’ ‘흉기(4.30),’ ‘치료(4.27),’ ‘진주(3.86),’ ‘주민(3.86)’ 등의 단어들이 상대적으로 높은 표준화된 TF-IDF 값을 나타냈다(표 2).

Table 2.
Top 20 frequently occurring words based on term frequency-inverse document frequency (TF-IDF)
![]()
그림 2는 빈도 분석 상위 20개 단어에 대한 동시 출현 네트워크를 나타낸다. 개괄적으로 살펴보았을 때, 조현병과 동시에 출현하는 단어들 중 ‘정신,’ ‘정신질환,’ ‘병원,’ ‘환자,’ ‘치료,’ ‘관리’ 등의 단어들이 상호 간 밀접한 관계를 나타냈으며, ‘경찰,’ ‘사건,’ ‘범죄,’ ‘흉기’ 등의 단어들은 ‘진주’, ‘아파트,’ ‘주민,’ ‘범행,’ ‘혐의,’ ‘살해’ 등의 단어 등과 가까운 관계를 갖고 있었다.
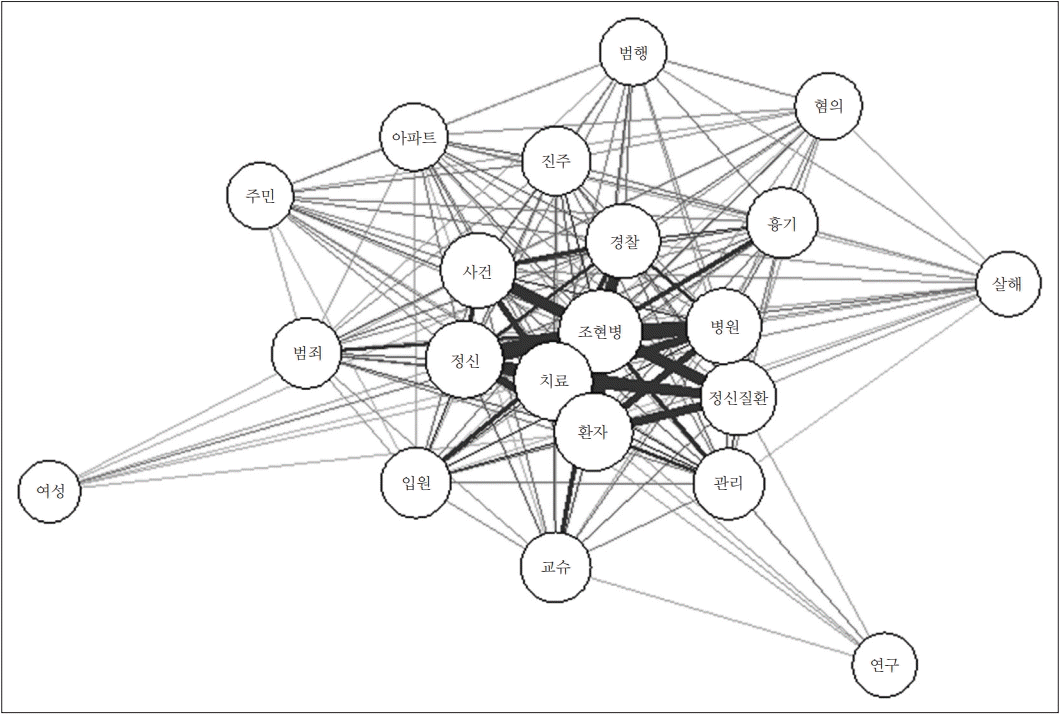
표 3은 10개의 잠재 토픽으로 분류된 상위 20개의 단어들과 기사 전체에서의 토픽 등장 확률의 총합을 나타낸다. 토픽의 이름은 각각의 토픽으로 분류된 단어들을 바탕으로 잠재 토픽의 의미를 살릴 수 있도록 정해졌다. 기사에서 가장 자주 등장했던 토픽은 ‘경찰-진주’이었으며, 이외에 ‘병원-입원,’ ‘연구-결과,’ ‘센터-관리,’ ‘범죄-법원,’ ‘조현병-증상,’ ‘사회-문제,’ ‘가족-심리,’ ‘여성-학교,’ ‘장애인-시설’의 토픽이 비슷한 수준의 등장 확률로 분류되었다.
Table 3.
Ten topics from latent Dirichlet allocation model within news articles on schizophrenia
![]()
Go to :
고 찰
본 연구에서 분석된 총 575건의 조현병 관련 기사 중 2019년에 보도된 기사 수는 427건으로 2018년 기사 수 148건 대비 약 3배에 달했다. 이는 2019년 한 해 동안 언론의 주목을 끈 조현병 관련 이슈들이 있었음을 시사한다. 주지하다시피 2019년 4월 경남 진주의 한 아파트에서 발생한 조현병 환자에 의한 방화 및 살인 사건은 큰 사회적 파장을 불러일으킨 바 있다. 본 연구의 빈도 분석에서 ‘경찰,’ ‘아파트,’ 그리고 ‘진주’ 등의 단어가 높은 등장 빈도를 나타내고 있었으며, 동시 출현 네트워크 분석에서도 이들 단어가 ‘사건,’ ‘범죄,’ 그리고 ‘흉기’ 등의 단어와 동반되고 있었다. 또한, 토픽 모형 분석도 ‘경찰-진주’가 기사 텍스트 중에서 가장 자주 등장한 토픽임을 확인하였다. 즉, 2019년 진주 사건이 최근 2년간 조현병 관련 언론 기사들 가운데 매우 큰 비중을 차지하는 이슈였음을 본 연구 결과는 보여주고 있다. 한편, 진주 사건 이외에도 최근 2년 동안 2018년 4월 방배 초등학교 인질 사건, 2018년 7월 경북 영천 경찰관 살인 사건, 그리고 2019년 6월 고속도로 역주행 사건 등 조현병 환자에 의한 몇몇의 폭력 사건이 언론을 통해 크게 다루어진 바 있다. 진주 사건과 함께 이같은 사건 사고와 이에 대한 사법 판결에 관한 기사들이 본 연구에서 조현병 관련 주요 단어 및 토픽으로 반영되고 있었다. 그리고 본 연구 결과는 사건 사고에 대한 단어나 토픽들과 연관되어 강제 입원이나 정신건강복지센터 관리에 대한 내용들이 기사에서 다루어지고 있음을 보여준다. 즉, 언론은 조현병 환자에 의한 사건 사고에 대한 논의 과정에서 환자들의 입원 치료와 지역사회 관리 이슈들을 사회 문제로서 거론하고 있었다. 이외에도 분석된 기사들 가운데에는 조현병 질환이나 연구에 대한 중립적인 내용도 포함되어 있었으며, 젠더나 장애인 문제가 조현병과 함께 다루어지기도 하였다.
본 연구에서는 감정 분석(sentiment analysis)을 수행하지 않아 주요 등장 단어나 토픽에 대한 주관적 가치 판단에 대한 내용은 확인할 수 없었다. 감정 분석은 텍스트에서 특정한 감정이 나타나는지 혹은 얼마나 나타나는지를 분석하는 것을 말한다[14]. 그러나 본 연구 결과에서 조현병 환자에 의한 폭력 사건과 연관되는 단어나 토픽들이 많은 수 등장했다는 점은 최근 2년간 조현병 관련 언론 기사들이 대체로 부정적인 논조로 조현병에 대한 낙인 요인을 나타내었을 것으로 예상해 볼 수 있다. 실제로 기존 연구들을 통해 정신건강이나 정신질환 관련 국내 언론 보도 중에는 사건 사고 기사의 비중이 높으며, 기사 논조 또한 대체로 부정적인 경우가 많다는 사실이 확인된 바 있다. 1998년부터 2000년까지 2년간 ‘정신병’ 관련 신문 기사를 326건을 분석한 Kim 등[23]의 연구에 따르면 부정적 기사의 비율이 69.9%로 높았으며, 부정적 기사 중 ‘정신병 환자는 위험하거나 난폭하며 범죄를 잘 저지른다.’는 내용을 포함한 기사가 거의 절반을 차지하고 있었다. 정신건강, 정신질환, 그리고 자살에 대한 2009년 인터넷 기사 1,495건을 분석한 Lee 등[24]의 연구에서는 부정적 관점으로 분류된 기사가 전체 기사 중 23.9%를 차지했으며, 부정적 관점의 기사 중 93%는 사건 사고와 관련된 기사로 나타났다. 2006년부터 2016년까지 10년간 5대 주요 일간지의 1,028개 정신질환 관련 기사를 분석한 Paek 등[25]의 연구에 따르면 전체 기사 중 41.1%가 정신질환 관련 낙인 요인을 보도하고 있었다. 2016년 1월부터 2017년 9월까지 13개 일간지에 보도된 정신건강 관련 기사 1,011건을 분석한 Hwang과 Na [26]의 연구에 따르면, 중립적 논조를 제외하고 봤을 때 부정적 논조의 기사 수가 긍정적 논조의 기사에 비해 약 2배 많았다(14.6% vs. 7.5%). 그리고 해당 연구에서 ‘조현병’으로 검색된 82건의 기사만을 놓고 보았을 때에는, 부정적 논조의 기사 수는 25건(30.5%)로 긍정적 기사 5건(6.1%)의 5배에 해당하였으며, 약 절반의(42건) 조현병 관련 기사들에서 정신건강 관련 사건, 사고 혹은 관련 법적 도덕적 분쟁을 보도하는 갈등 프레임을 다루고 있었다[26].
앞서 언급한 언론 분석 연구들은 주로 코드북(codebook)과 코더(coder)를 이용한 내용 분석을 통해 수행되었다. 그러나 오늘날 대규모 데이터를 분석하는데 있어서 이와 같은 전통적 분석 방법은 코드북의 타당성과 코더의 신뢰도 확보 문제, 그리고 방대한 텍스트를 분석하는데 필요한 시간과 비용 등 한계를 갖는다[8]. 반면, 텍스트 마이닝 기법은 대규모 텍스트 데이터에서 의미를 구성하는 최소 단위의 텍스트 구성 요소를 파악하고, 이 요소들에 수학적 알고리즘을 적용하여 어떤 텍스트 구성 요소가 텍스트를 주도적으로 설명하는지 또는 텍스트의 의미를 예측하는데 효과를 나타내는지를 쉽게 정량화 해낼 수 있다[14]. 이에 최근에는 인문, 사회 및 경제학 분야에서 텍스트 마이닝을 이용한 많은 연구들이 수행되고 있다[27,28]. 그러나 정신건강 또는 정신질환에 대한 언론 보도 형태를 텍스트 마이닝 기법으로 분석한 시도는 국제적으로도 그 수가 많지 않으며, 본 연구는 국내 기사에 대한 최초의 텍스트 마이닝 연구에 해당한다. Koike 등[29]은 1985년부터 2013년까지 일본 4개 신문사와 1개 TV 뉴스에서 보도된 조현병 관련 기사 총 6,361건을 분석하여 2002년 일본에서 시행된 ‘통합실조증(統合失調症)’으로의 병명 개정이 언론 보도에 미친 영향을 텍스트 마이닝 기법을 이용하여 분석한 바 있다. 상기 연구의 빈도 분석에서 등장 빈도 상위 20개의 단어 중에는 ‘지방법원,’ ‘판결,’ ‘피고,’ ‘죽임(killing),’ ‘투옥,’ ‘타살,’ 그리고 ‘자상(stabbing)’ 등 폭력 사건 사고와 관련된 단어들이 다수 포함되어 있었으며[29], 이는 본 연구에서 확인된 국내 조현병 관련 기사의 다빈도 등장 단어들과도 같은 맥락에 있다고 볼 수 있다.
본 연구는 다음과 같은 제한점을 갖는다. 첫째, 본 연구는 2018년부터 2019년까지 비교적 짧은 기간 동안 보도된 조현병 기사를 분석 대상으로 하였으므로, 연구 결과는 해당 기간 동안 주목을 끌었던 몇몇 조현병 관련 이슈들을 반영하고 있다. 이에 본 연구 결과가 조현병에 대한 국내 언론의 전반적인 보도 양상을 설명한다고는 볼 수 없다. 둘째, 본 연구에서는 형태소로서 명사만 분석되었으며, 동사나 형용사는 분석에 포함되지 않았다. 또한 한글형태소 사전의 한계로 고유 명사나 전문 용어 일부도 분석에 포함되지 않았을 가능성이 있다. 셋째, 동시 출현 단어를 분석하기 위하여 단어 간 네트워크를 구성하고 이를 시각화 하였으나, 중심성(centrality) 분석 등 세부적인 네트워크 분석은 본 연구에 포함시키지 않았다. 이는 본 연구의 수행 범위를 넘을 것으로 판단되며, 향후 추가 연구를 통해 다루도록 하겠다. 넷째, 가용한 한국어 감성어 사전(sentiment lexicon)이 없는 관계로 본 연구에서는 위에서 언급한 바와 같이 감정 분석을 수행되지 않았다.
이와 같은 제한점에도 불구하고, 본 연구는 조현병 관련 언론 기사를 텍스트 마이닝 기법으로 분석한 국내 최초의 연구로, 최근 언론에서 다루어진 조현병 관련 이슈를 정량적으로 확인하였다. 향후 연구를 통해 텍스트 데이터에 대한 수학적 분석 방법을 이용하여 조현병 관련 사회 이슈와 그에 대한 언론 동향, 그리고 소셜 미디어에서의 여론을 통합적으로 분석해 볼 필요가 있다.
Go to :
 XML Download
XML Download