

 PDF
PDF Citation
Citation Print
Print



I. Introduction
II. Methods
1. Data Acquisition
1) The mPower study
2) Cohort selection
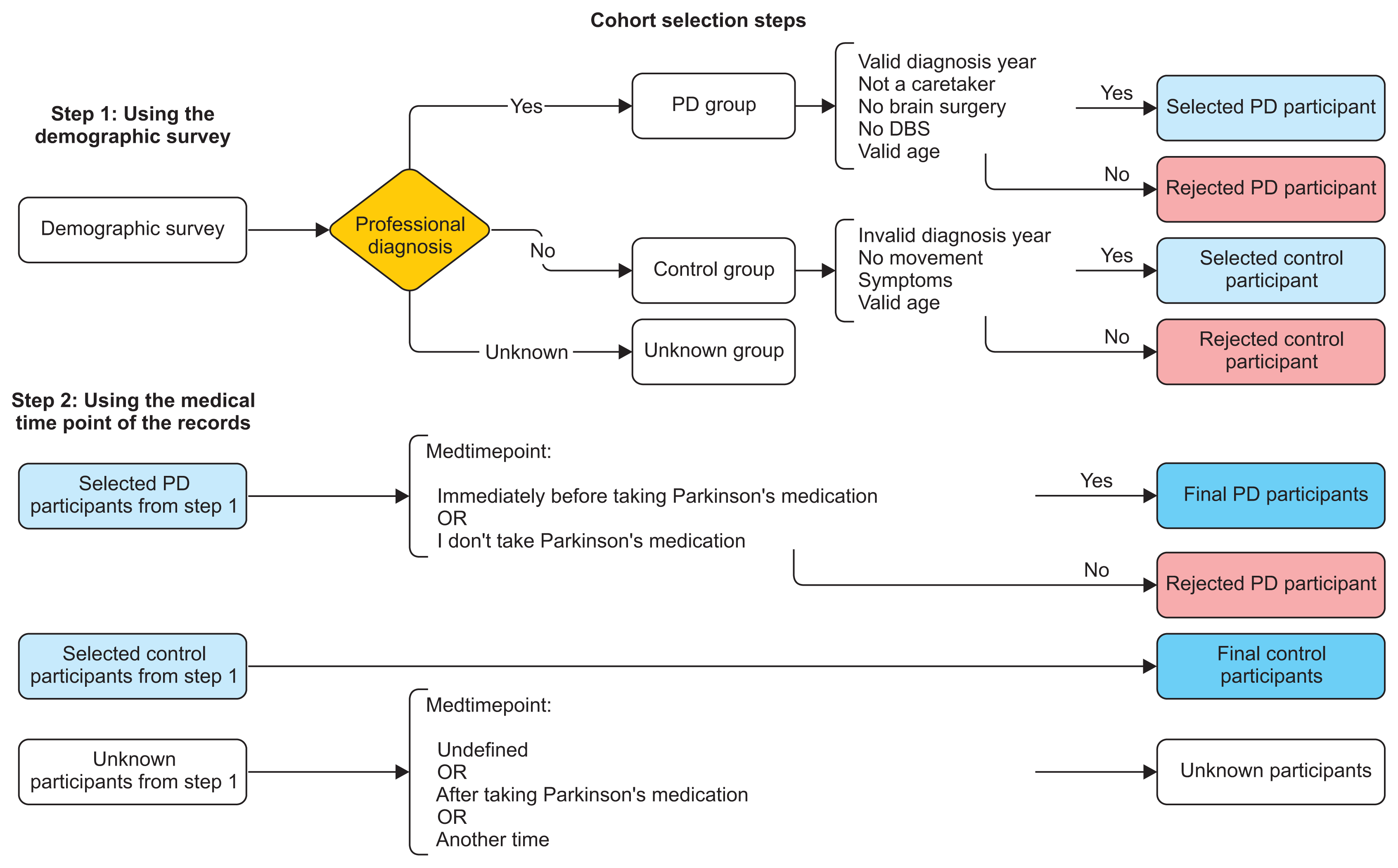
- PD group selection: If the participant is professionally diagnosed by a doctor AND he or she has a valid date of diagnosis, AND is actually a Parkinsonian, not a caretaker, AND has never had surgery to treat PD nor deep brain stimulation, AND his or her age is valid.
- HC group selection: If the participant is not professionally diagnosed by a doctor, AND he or she has no valid date of diagnosis, AND has no movement symptoms, AND his or her age is valid.
- Unknown group selection: A participant is said to be unknown if their professional diagnosis is unknown.
Table 1
![]()
- PD group selection: Selected PD participants from step 1 AND (recordings of participants immediately before taking PD medication OR recordings of participants who didn’t take PD medication).
- HC group selection: The same participants from step 2.
- Unknown group selection: Unknown group from step 1 OR (records with undefined medication time point OR recordings of participants after taking PD medication OR recordings of participants at another time of the day).
2. Audio Signal Feature Extraction
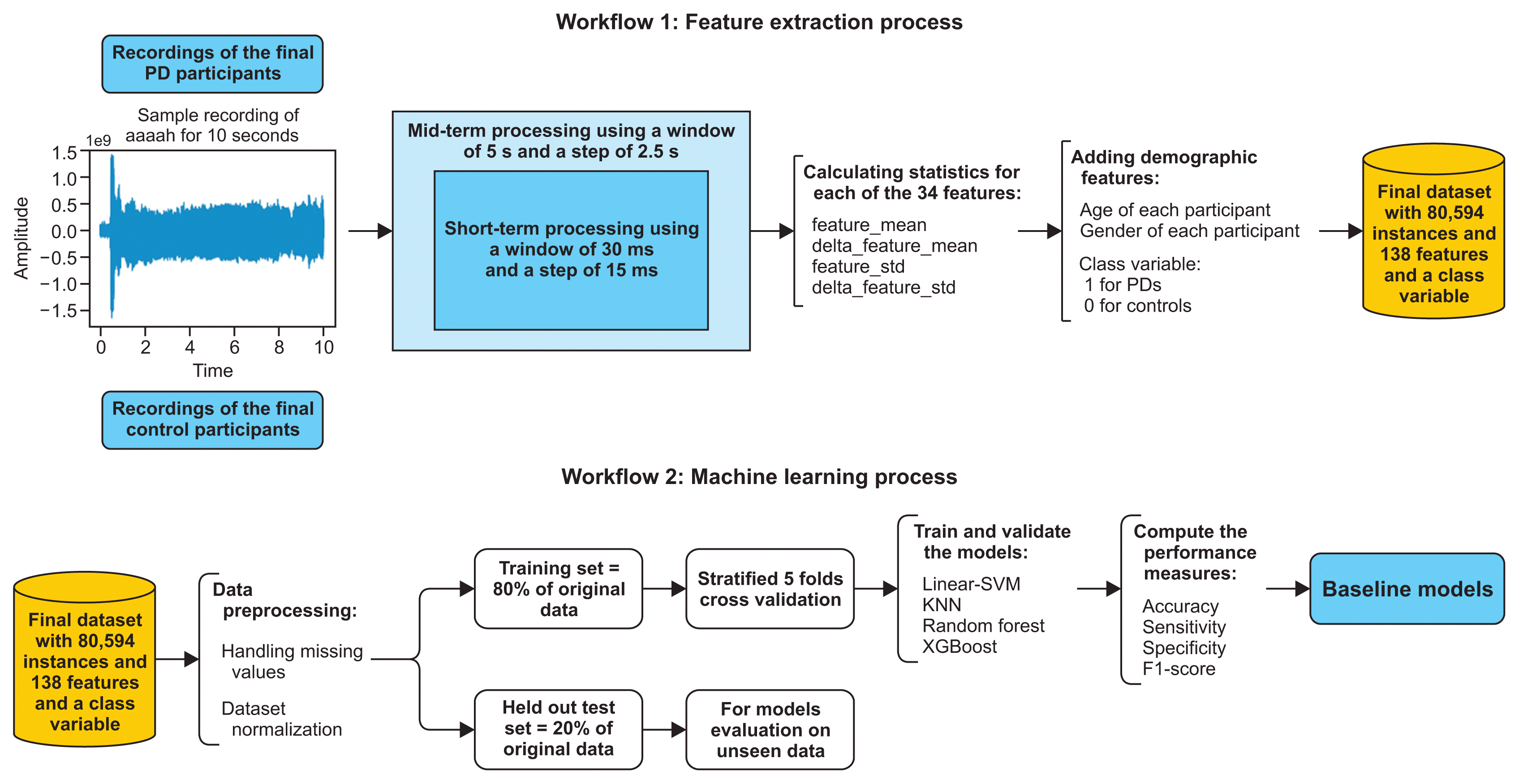
3. Baseline Models
1) Dataset cleaning: handling missing values
2) Dataset normalization
- Dataset rescaling between 0 and 1 and between −1 and 1;
- Dataset normalization;
- Dataset standardization.
4. Feature Selection
1) Filter method: ANOVA
2) Embedded method: LASSO
Table 3
![]()
III. Results
1. Baseline Models Results
2. Feature Selection Results
3. Hyperparameter Tuning Results
Table 5
![]()
IV. Discussion
Table 7
| Study | Dataset | Methodology | Results |
|---|---|---|---|
| Little et al. [10] | They used an original dataset consisting of 195 recordings collected from 31 patients where 23 were diagnosed with PD | They detected dysphonia by discriminating HCs from PD participants, by extracting time domain and frequency domain features | They achieved an accuracy of 91.4% using SVM classifier with 10 highly uncorrelated measures. |
| Benba et al. [11] | They used a dataset consisting of 17 PD patients and 17 HCs | They classified PD participants from HCs using a set of recordings recorded using a computer’s microphone, and by extracting 20 MFCC coefficients | They achieved an accuracy of 91.17% using linear SVM with 12 MFCC coefficients. |
| Hemmerling et al. [12] | They used an original dataset consisting of 198 recordings collected from 66 patients where 33 were diagnosed with PD | They extracted several acoustic features, and applied Principal Component Analysis (PCA) for feature selection | They achieved and accuracy of 93.43% using linear SVM |
| Singh and Xu [19] | They selected randomly 1,000 recordings from the mPower database | They extracted MFCC coefficients using the python_speech_ features library and compared different feature selection techniques | They achieved an accuracy of 99% using SVM with an RBF kernel and by selecting important features using L1 feature selection technique |
| This study | We have used a set of 18,210 smartphone recordings from the mPower database where 9,105 recordings are of PD participants and 9,105 recordings are of healthy controls | We have extracted several features, from time frequency and cepstral domains, we have applied different preprocessing techniques and used two feature selection methods ANOVA and LASSO to compare Four different classifiers using 5-fold cross-validation | We have achieved on unseen data a high accuracy, sensitivity, and specificity of 95.78%, 95.32%, and 96.23% respectively, and an F1-score of 95.74% using XGBoost with 33 features out of 138 that were chosen using LASSO with C = 0.03 |
![]()
 XML Download
XML Download