

 PDF
PDF Citation
Citation Print
Print



I. Introduction
Alcohol use disorders (AUDs) are characterized as chronic and relapsing conditions associated with high cost of care [1–3]. The overall economic burden of AUDs is remarkable, varying between 40 and 58 billion euros (€) in Europe [4,5].
The clinical course and prognosis of AUD in treated samples are known to be affected by several factors, including severity of the AUD, demographic and socio-economic factors, and mental health comorbidity [6–9], and long-term abstinence rates in treated populations vary only around 5.8% [10,11]. However, long-term studies on predictors of the future cost accumulation across social and healthcare service systems among this patient group have found mixed results, especially regarding the role of achieving stable remission [12–14]. Age, gender, employment status, co-occurring mental health problems, and abstinence status have all been associated with healthcare cost accumulation among individuals with AUD [14,15].
Electronic Health Records (EHRs) provide extensive information on individual health, and the performance of the treatment system and machine learning techniques have proved to be useful in predictive modeling based on these data [16–20]. Research on predicting healthcare costs in high-need patients is also gaining interest [21]. However, there has still been very little research regarding the causal links and direct effects between various risk factors and treatment costs among high-need AUD patients.
In this study, we aimed to identify the causal associations of various socio-economic and health-related factors with the 5-year cost of care for a clinical cohort of AUD patients. The specific aim was to assess the causal effect of AUD remission on the cost of care. We hypothesized that remission has a cost decreasing effect. We further produced a profile of independent variables’ values maximizing and minimizing costs during 5 years of follow-up, based on sensitivity analysis (SA) among variables.
Go to : 
II. Methods
1. Sample
To examine the magnitude of 16 risk factors on cost accumulation, we used a random sample (n = 363) of AUD patients identified through EHRs based on alcohol-related ICD-10 (the International Statistical Classification of Diseases and Related Health Problems, 10th revision) codes. Figure 1 presents the research flow. The study cohort was randomly sampled from the regional EHR system in the North Karelia region in Finland based on the following alcohol-related ICD-10 diagnosis codes: G312, G405, G4050, G4051, G4052, G621, I426, K292, F100, F101, F102, F103, F104, F105, F106, F108, F109, K860, K700, K701, K702, K703, K704, K709, T510, T511, T512, T513, T518, T519, X45, and X69 (see Appendix 1 for more detailed information). Retrospective sampling included the years 2011 and 2012. Of the identified overall AUD population of (n = 6,246) individuals, we first formed a random cohort of 396 individuals by using Excel random sampling, and their health service use cost data were retrieved from the EHRs for the years from 2011 to 2016. We then excluded individuals who died or remitted in 2011 because we were not able to explicitly identify which costs in 2011 were caused before remission and which were caused after. Thus, the final study sample included 363 individuals. Based on the manual assessment of the EHR data conducted by two reviewers, the principal researcher and research assistant, we identified that the cohort represented individuals with a severe form of AUD. AUD was defined according to the Diagnostic and Statistical Manual of Mental Disorders (DSM-V) and ICD-10 to include both harmful use and alcohol dependence.
2. Measurement
The examined outcome was the total cost of care. Data on the cost of care were used for the years from 2012 to 2016, and cost data from 2011 were used as a priori information. Specialized care costs were retrieved from the hospital EHR system, including all hospitalizations, outpatient visits and admissions, and their costs derived from the hospital’s cost accounting systems. Primary care costs were retrieved from the outpatient EHR system but were underestimates of the true costs, as the primary care database did not include e.g. private health service use costs (see Appendix 2 for more information). Total costs were discretized to quartiles. In the assessment of the causal effect of AUD remission on patients’ costs of care, those with continual AUD were used as a reference, and those who died before the year 2012 were excluded from analysis.
We identified 16 factors associated with AUD trajectories and their costs based on the literature [14,15,22], including socioeconomic variables encompassing age, gender, marital status, unemployment status, and social problems like homelessness, illicit drug use, criminal record, and drunk driving. Data on drinking status and socioeconomic variables were manually collected from EHRs and the municipal social services database mainly as dichotomous variables. In addition, clinical variables included the number of ICD-10 diagnoses of chronic conditions (i.e., permanent diagnoses). Diagnoses were classified into three groups, according to number: (1) none, (2) one, and (3) two or more. Mental health diagnoses included ICD-10 codes F00 to F99 (mental and behavioral disorders), excluding F10 codes. Drinking status was defined as continual AUD or stable AUD remission. Stable remission was defined as sustained abstinence or managed use that lasted until the end of the follow-up period, with a minimum duration of 6 months. Time estimate in AUD remission was based on health professionals’ objective notes and diagnosis information. Individuals with any shorter abstinence periods were included in the continual AUD group.
3. Ethical Considerations
The study was approved by the Research Ethics Committee of the Northern Savo Hospital District (No. IRB00006251). Consent was not obtained, as the study was based on registry information. Patients were not contacted.
4. Statistical Analysis
We performed the statistical analysis using the Bayesian network approach with the BayesiaLab 9.0 tool [23]. The visual form of a Bayesian network is a directed acyclic graph (DAG), from which direct and indirect effects, common causes, and effects can be discovered and mathematically expressed. A DAG consists of nodes presenting random variables Xi, and arcs or lines presenting associations between a pair of variables. A DAG defines a factorization of joint probability of a Bayesian network into a product of local probability distributions, one for each variable:
where paXi are parents of a variable Xi. This type of representation enables both deductive and abductive inference from the model, allowing fixing of (controlling for) one or several variables’ probability distributions for inference of the direct or total effect of the variables of interest on the target variable.
Bayesian networks are used for both non-causal (predictive or explanatory) and causal modeling. In the non-causal model, the arc describes probabilistic relationships between the parent variable(s) and the child variable(s), whereas in the causal model it describes the existence of a direct causal dependence between two variables. A Bayesian network structure is constructed by using a bottom-up modeling approach (i.e., using structural and parameter learning from data), a top-down approach (i.e., manual construction based on existing expert knowledge), or a hybrid of the bottom-up and top-down methods. Multiple algorithms exist for structural learning. A supervised learning method with a minimum description length (MDL) score [24] uses a naive structure, such as augmented naive Bayesian (ANB) and tree augmented naive Bayesian (TAN), whereas an unsupervised learning method uses greedy search (e.g., maximum spanning tree, taboo, and hill climbing) with MDL scoring to construct a non-naive Bayesian network. Supervised learning is used mainly for predictive modeling, and unsupervised learning is adapted for clustering and for the construction of a causal Bayesian network. However, human intervention is required to verify the correctness of causal directions.
The MDL score optimizes the model complexity against the model fit to data and can be expressed at a high level as
where BN is a Bayesian network including parameters, DL is a description length in bits, G is the graph part of a BN, CPTs are conditional probability tables for each variable Xi in the model, and SC is the structural coefficient. With the SC, the effect of the complexity of the network to the score can be increased (SC < 1) or decreased (SC > 1). A more detailed level MDL equation is provided in Appendix 3.
A true causal network between the variables and the target variables is hard to estimate. Especially in settings with numerous variables, information of a complete causal structure is often unknown. Nevertheless, causality can be estimated by applying van der Weele and Shiptser’s modified disjunctive confounder criteria (DCC) for calculating the direct causal effect of a variable on the target variable from a non-causal Bayesian network [25,26]. According to the DCC, correctly selected confounders are the key for successful blocking of all backdoor and frontdoor paths between the treatment and the target variables in a Bayesian network. Van der Weele and Shiptser [25] defined the original DCC as “controlling for each variable that is a cause of the treatment, or of the target, or both”. Van der Weele [26] added two additional qualifications to the DCC for practical use for confounder controlling and re-named it the modified disjunctive confounding criterion, called in this article modified DCC. Additional definitions are (1) discarding any variable known to be an instrumental variable and (2) including variables that do not satisfy criteria but are good proxies for unmeasured common causes of treatment.
Continuous variables were discretized using a convenience distribution for the variable age with 10-year intervals. The variables implying costs were discretized to quarters having 25% of observations in each class. The outcome variable was cumulative healthcare costs (totalcost_2012–2016), which was discretized into equal quartiles, qualitatively described as “low cost” (≤€4,486.54), “medium cost” (€4,486.55–€15,746.10), “high cost” (€15,746.11–€46,864.36), and “very high cost” (€46,864.37–€1,180,863.75).
Supervised ANB learning was used in the study to construct a Bayesian network. To find the optimal complexity of the model in the ANB learning phase, an SC analysis was performed as part of MDL scoring, and the value SC = 0.6 was used in the analysis.
The result was a non-causal ANB network model with 16 independent variables. BayesiaLab allows every variable and their combinations to be fixed to certain values. For example, the variable “status2012” can be fixed to the value “remitted” = fixed to 100%. Then the model gives the values of the outcome in that hypothetical case that individuals had an AUD remission. We analyzed the probabilistic effect of independent variables by fixing each variable’s values separately to be 100%.
Following the modified DCC, we examined the effect of AUD remission in 2012 (continuous drinking vs. remission) by fixing marginal distributions of all other independent variables except drinking status (status2012). We analyzed the variables associated with the variable status2012 (continuous AUD/AUD remission) by a semi-structured search with status2012 as the target. The following variables were associated with status2012: drug use (strongest effect), homelessness, criminal background, gender, marital status, and income support, fulfilling the criteria of the DCC. In a similar analysis, we found the following variables to be associated with the outcome totalcost_2012–2016: number of somatic diagnoses, age, income support, municipality, and specialized care costs 2011. The variable “income support” was the only variable associated with both the outcome and index variable status2012. We also used the variable “number of psychiatric diagnoses” in ANB modeling for a measurement of psychiatric background.
We used Jouffe’s proprietary likelihood matching (PLM) algorithm, which implements the modified DCC and allowed us to estimate the independent variables’ causal effect on the target while holding others constant [27].
An SA among variables allows the identification of combinations of variable values that have the maximum or minimum effect on the target variable. SA was performed twice using hard evidence, showing first the maximum and then the minimum effect on costs (target variable totalcost_2012–2016).
A tornado diagram is a design for SA. The diagram consists of two-sided horizontal bars to visualize the factors with the largest impact (positive or negative) on the outcome variable. The widest bar showing the largest impact is placed at the top. Bars to the right of the midline show the positive effect on the outcome variable, whereas bars to the left represent a negative effect. The diagram is presented separately for each value of the outcome variable.
Go to :
III. Results
The dataset with discretization of numerical variables is presented in Table 1. Until the end of 2016, 62.8% continued drinking, 16.5% died, and 20.7% remitted. The research data contained 335 missing values (4.2% of the dataset), whose type was missing at random. We input the missing values by using an expectation-maximization algorithm. The predictive performance of the model as an area under ROC curve (AUC) was 79.2%.
Table 1
Characteristics of the study cohort (n = 363)
![]()
The ANB model is presented in Figure 2. The corresponding table of direct effects is Table 2, and the fixation table of the model is Tables 3–5. The main finding was that a high number of somatic diagnoses was the strongest contributor to the 5-year total costs, causing over €26,000 mean excess cost per patient.
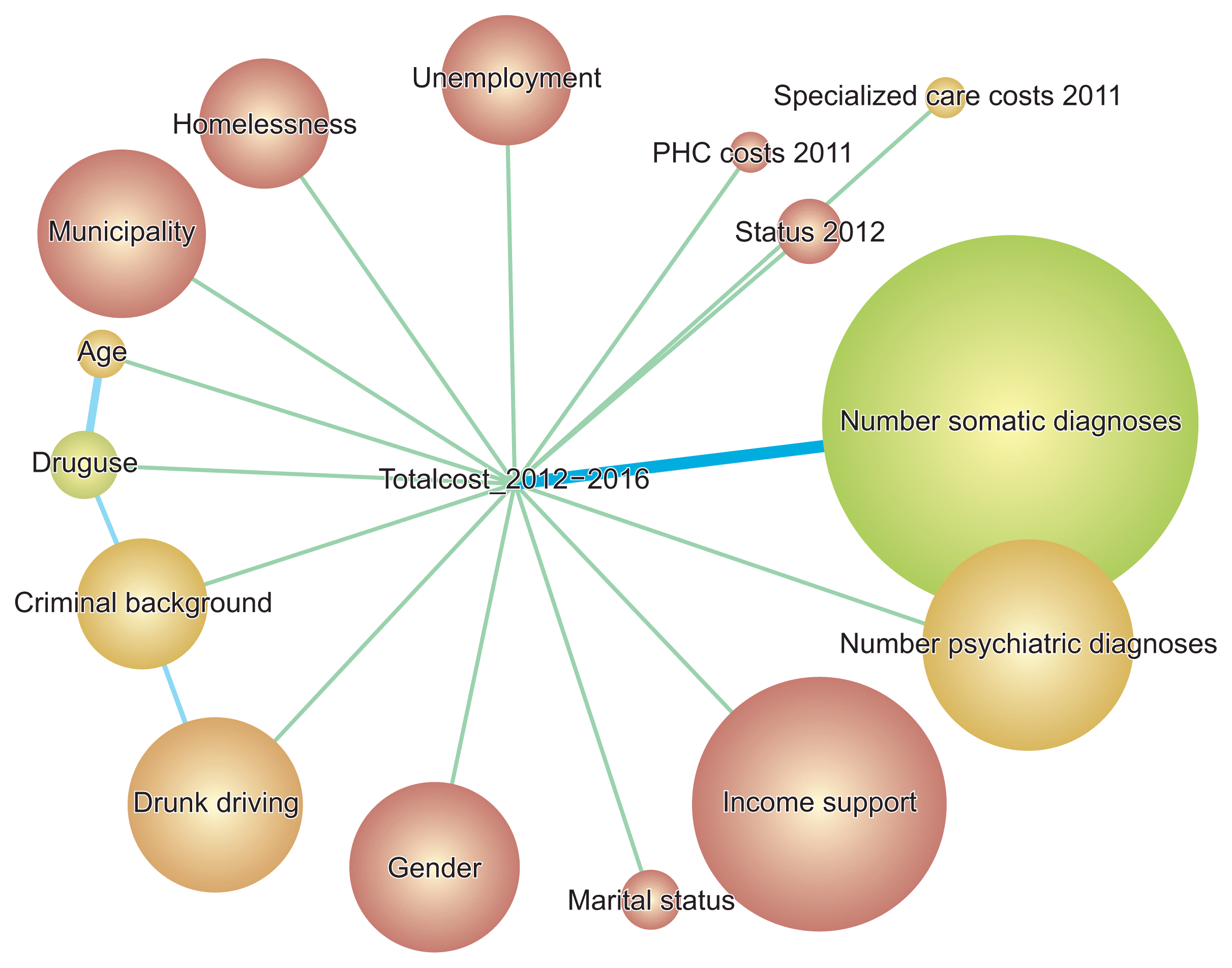 | Figure 2The augmented naive Bayes model of factors associated with the outcome variable total costs (totalcost_2012–2016). Node sizes express each variable’s direct effect on the target node. Node colors indicate node force, with green being the highest and red lowest, and yellow in between. Lines between nodes indicate the relationship between them (Kullback-Leibler divergence).
|
Table 2
Variables’ direct effects on and contributions to the target (totalcosts_2012–2016)
![]()
Table 3
Fixation table demonstrating values of the outcome variable (totalcosts_2012–2016) when the model is fixed to selected values (socio-economic variables)
![]()
Table 4
Fixation table demonstrating values of the outcome variable (totalcosts_2012–2016) when the model is fixed to selected values (clinical variables)
![]()
Table 5
Fixation table demonstrating values of the outcome variable (totalcosts_2012–2016) when the model is fixed to selected values (social deprivation variables)
![]()
Secondly, the causal effect of an AUD remission was produced by fixing the variable “status2012” by turns to values 1 = continuous drinking and 3 = remitted. All other variables were controlled by fixing them to their original value distributions. The results presented in Figure 3 confirm our hypothesis that remission had a cost-decreasing effect on the cost accumulation, as the percentage of the lowest cost quartile was 42.86%, compared with the respective figure of 25.07% for current drinkers. Correspondingly, the percentage of the high-cost quartile was among remitters (10.71%) and among current drinkers (26.27%), while the proportion of very high costs remained on a rather similar level.
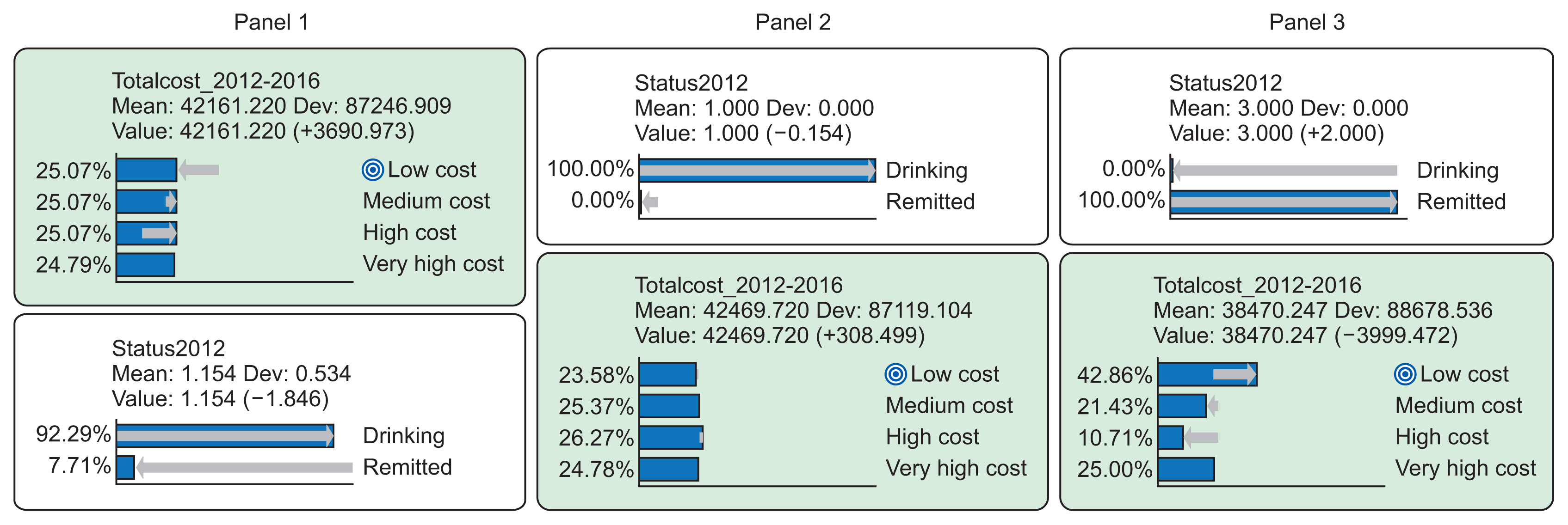 | Figure 3Panels showing the outcome variable “total cost_2012–2016” in relation to drinking “status2012”. Cost quartiles include: low costs, ≤€4,486.54; medium cost, €4,486.55–€15,746.10; high cost, €15,746.11–€46,864.36; and very high cost, €46,864.37–€1,180,863.75 and drinking status in 2012 was defined as continuous drinking versus remitted. In Panel 1, both variables are unfixed. Panel 2 shows the distribution of costs in the outcome variable “totalcost_2012–2016” when the variable “status2012” is fixed for the value drinking=100% and all other variables (not shown) are fixed to their original distribution. In Panel 3, the variable “status2012” is fixed for the value remitted=100%, demonstrating the causal change in costs (totalcost_2012–2016) after achieving remission.
|
Comparative SAs with tornado diagrams are presented in Figure 4. The diagrams show that the number of somatic diseases, specialized care costs, number of psychiatric diagnoses, age, and drug use have the strongest impact on high and very high costs of care. SAs of values that (1) maximize the costs and (2) minimize the costs during the 5-year follow-up are presented in Tables 6 and 7. These profiles strongly suggest that the excess costs of AUD patients are caused by multimorbidity. Joint probability values less than 1 (in both Tables 6 and 7) indicate the results in this cohort, but we consider them ungeneralizable outside this cohort.
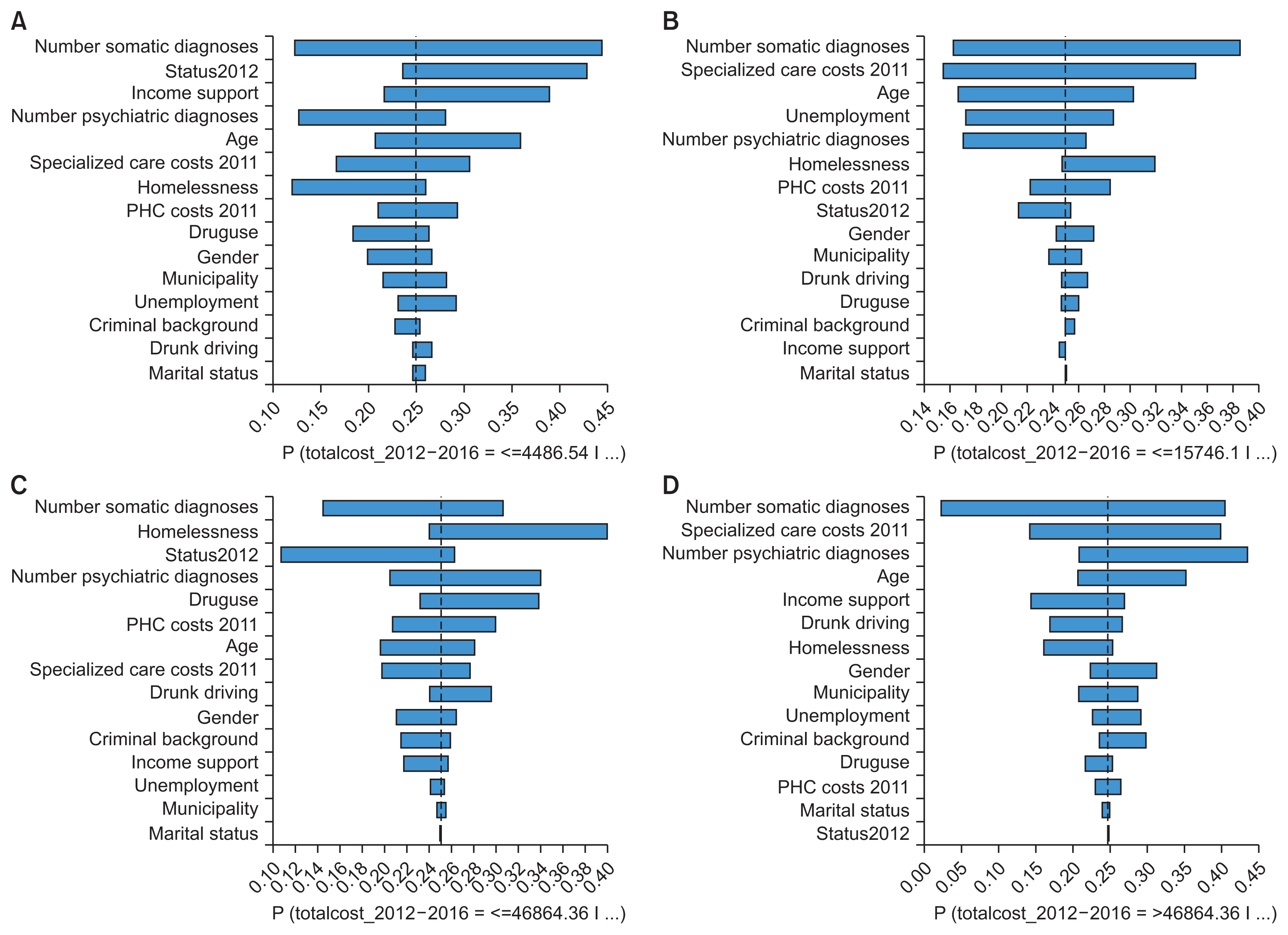 | Figure 4Tornado diagrams showing variables with the strongest impact on the outcome variable. Bars pointing to the right represent a positive impact, and bars to the left a negative impact. (A) Panel 1 shows the effect on “low cost” value of the outcome variable, (B) Panel 2 on “medium cost”, (C) Panel 3 on “high cost”, and (D) Panel 4 on “very high cost”.
|
Table 6
Dynamic profile of values maximizing the outcome variable total 5-year cost (totalcosts_2012–2016)
![]()
Table 7
Dynamic profile of values minimizing the outcome variable total 5-year costs (totalcosts_2012–2016)
![]()
Go to :
IV. Discussion
This is the first time that causality between multiple risk factors and cumulative healthcare costs among AUD patients was studied by using EHR data with the application of van der Weele and Shiptser’s modified DCC [24]. As the etiology and clinical course of AUD are complex and affected by numerous variables, a true causal network between the variables and the outcome variable remain unknown. In this study, causality was estimated by using the modified DCC to calculate the direct causal effect of individual variables on the cumulative healthcare costs from a non-causal Bayesian network. The results suggest that multiple chronic conditions together with high specialized care costs, receiving income support, region capital as a place of residence, and age over 55 years fulfilled the DCC and were the strongest explanatory factors maximizing the 5-year total costs. Respectively, the prevalence of the lowest cost quartile increased notably among those who remitted.
The clearest causal relationship was observed between the number of chronic conditions and the total costs of care. The SA of values maximizing the total cost of care identified a high number of chronic conditions to be the main contributor to the excess cost of care in this cohort and to increase the mean total cost by €26,000 per patient. Furthermore, SA with tornado diagrams showed that the variables that had the strongest impact on the total cost of care varied; for low cost value (<€4,486) of the target interval, the number of chronic conditions and baseline drinking status (status2012) had the strongest role. For the high (≤€46,864) and very high cost value (>€46,864.4) of the target interval, the role of comorbidity, social problems such as illicit drug use and homelessness, specialized care costs, psychiatric comorbidity, and age had the strongest impact.
However, there were certain limitations, and they should be considered when interpreting the findings. First, the cohort was formed retrospectively, and then follow-up was managed prospectively. We consider this method better than a completely retrospective method. Also, follow-up data from 33 individuals were missing (8.3%). Second, the DCC is used in situations in which the exact causal relations between variables are unknown. In this study, we were able to recognize only a few clear causal relations, such as the effect of multiple diseases, to increasing costs. Causalities between independent variables remained mostly unknown. The use of the DCC has two requirements. All independent variables should be known in pre-treatment condition, in this study, before the year 2012. Only variables fulfilling this criterion were used in this DCC analysis. The other requirement is that any unmeasured variable should have no effect on the index variable (status2012), the outcome, or both. For example, the genetic basis of AUD and motivation to adhere to treatment are potential unmeasured variables with an effect on AUD remission and costs. We consider these unmeasured variables as parent variables to the measured ones, and with regard to the motivation, status in 2012 is thought to function as a marker condition for motivation. However, we cannot rule out the potential bias generated by unmeasured variables. Third, the direct effect on the outcome variable shown in Table 2 requires that the impact of independent variables should be linear. However, some variables show an increasing nonlinear association with the outcome in the highest values. This was seen in the following variables: age, number of psychiatric diagnoses, and drug use. We consider that the direct effect analysis showed in Table 2 moderately underestimates their impact.
Although the results cannot be directly compared with those of previous studies due to differences in the study design and methodologies used, our findings support the previous evidence regarding the cost-decreasing effect of AUD remission [12,13]. Application of the DCC to study patients with AUD provided evidence that achieving stable remission decreased the total cost of care during the 5-year follow-up. Likewise, previous studies have indicated that high prevalence of comorbidities explains the increases in cost accumulation, especially among high-cost patients [22], which include patients with addictions [28]. Thus, our results are in line with those of previous studies identifying an association between the number of comorbidities and increased costs of care among patients with chronic conditions [22,29,30]. This research identified factors that minimize and maximize the total cost among AUD patients. The information provided by this study, especially regarding the cost-offset pattern of achieving AUD remission, supports decision-making in both clinical settings and at the policy level.
Go to :
 XML Download
XML Download