

 PDF
PDF Citation
Citation Print
Print



I. Introduction
Chronic renal failure (CRF) is an irreversible kidney condition that leads to end-stage renal disease (ESRD) [1]. ESRD patients require replacement interventions, such as kidney transplant or hemodialysis. Globally, ESRD is a substantial issue in the medical field. In the absence of replacement interventions for these patients, ESRD leads to death [2]. There were about 3,730,000 patients in ESRD by the end of 2016. Taiwan, Japan, and the United States have the highest ESRD prevalence in the world [3]. In Iran, ESRD prevalence is 610 per million people, which is greater than the global average (580 per one million people) [3]. Seventy percent of ESRD patients receive hemodialysis treatment. Due to the 5% to 6% annual increase in ESRD incidence and 1.1% increase in the global population, ESRD has become a major global health issues [3].
There is no indication in the early stages of CRF, and most of patients are identified in the end stage, in which the performance of the kidney has been totally disturbed. The accumulation of metabolic waste products occurs in CRF patients, which leads to changes in blood factors, such as serum creatinine. One way to diagnose patients with CRF is to check the serum creatinine [4,5].
In most clinical research, the outcome variable is collected longitudinally (multiple observations over time) for each patient or subject. For a longitudinal outcome, such as creatinine in CRF patients, the prediction of the actual values and checking their trend over time may be important. In longitudinal responses, due to unknown factors, the baseline value and the time trend of each patient may be different. Therefore, to predict and analyze these responses, methods should be used that consider the differences in baselines and time trends. In other words, there is a correlation structure among the observations of the subject that needs to be considered in the modeling.
There are several methods for analyzing longitudinal responses, including the linear mixed-effects model (LMM), generalized liner mixed-effects model (GLMM), and generalized estimation equation (GEE) [6–8]. The most widely used method for continuous outcomes is LMM. This model is an extension of linear regression (LR) that considers the differences of baseline values and time trends using random effect terms. Linear or limited nonlinear relationships between covariates and response can be considered in LMM. Therefore, LMM may not be useful in the presence of complex nonlinear relationships between outcome and features.
Recently, machine learning approaches have often been applied to various prediction problems as classification or regression [9–11]. The least-squares support vector regression (LS-SVR) method is a machine learning approach that can be used for the prediction of continuous responses [12,13]. Complex nonlinear relationships between response and covariates can be considered in LS-SVR by using a kernel technique [12,14]. There have been a few studies that used the LS-SVR technique to predict longitudinal responses [14–17].
In this study, we used an LS-SVR method that takes into account random effects, in addition to complex relations. We used a mixed-effects least-squares support-vector regression (MLS-SVR) method presented for longitudinal data sets [15,16]. The aim of this study is to evaluate the prediction performance of LMM and MLS-SVR for serum creatinine. To the best of our knowledge there has been no study that has used the LS-SVR method for CRF patients. Also we investigated the efficacy of random effects in the prediction of creatinine in hemodialysis patients. Obtaining the important variables in prediction of creatinine using the MLS-SVR method is another objective of this paper.
Go to : 
II. Methods
1. Data and Setting
We used a longitudinal dataset related to a study on hemodialysis patients in the hemodialysis department of Shahid Beheshti Medical Education Center of Hamadan city (Iran) between 2013 and 2016, which was collected for a master of science thesis [18]. There were 3,492 observations regarding 158 hemodialysis patients in the dataset. Some laboratory variables were collected longitudinally in the dataset, such as creatinine, fasting blood sugar (FBS), hematocrit (HCT), hemoglobin (HB), calcium (Ca), potassium (K), phosphorous (P), and blood urea nitrogen (BUN). Also, there were multiple fixed factors, such as the number of dialysis sessions in a week, gender, age, diabetes (yes or no), and hypertension (yes or no) in the dataset. We used the serum creatinine as the longitudinal response and the other variables as the fixed effects covariates. Also, the random intercept and trend were considered in the LMM and MLS-SVR methods as the random effects.
To evaluate the performance of the methods in the prediction of creatinine, the data was divided into two subsets, training and testing samples. Thus, because of the longitudinal nature of the data, the first 70% of observations related to each patient were considered as the training sample and the remainder were considered as the testing set. We fitted the LMM and MLS-SVR methods to the training and testing samples by considering the random intercept and trend in the models. Also, the LR model and ordinary LS-SVR were fitted to the data to assess the influence of taking into account random effects terms in the performance of the models in prediction of outcome. The data preprocessing is shown in Figure 1.
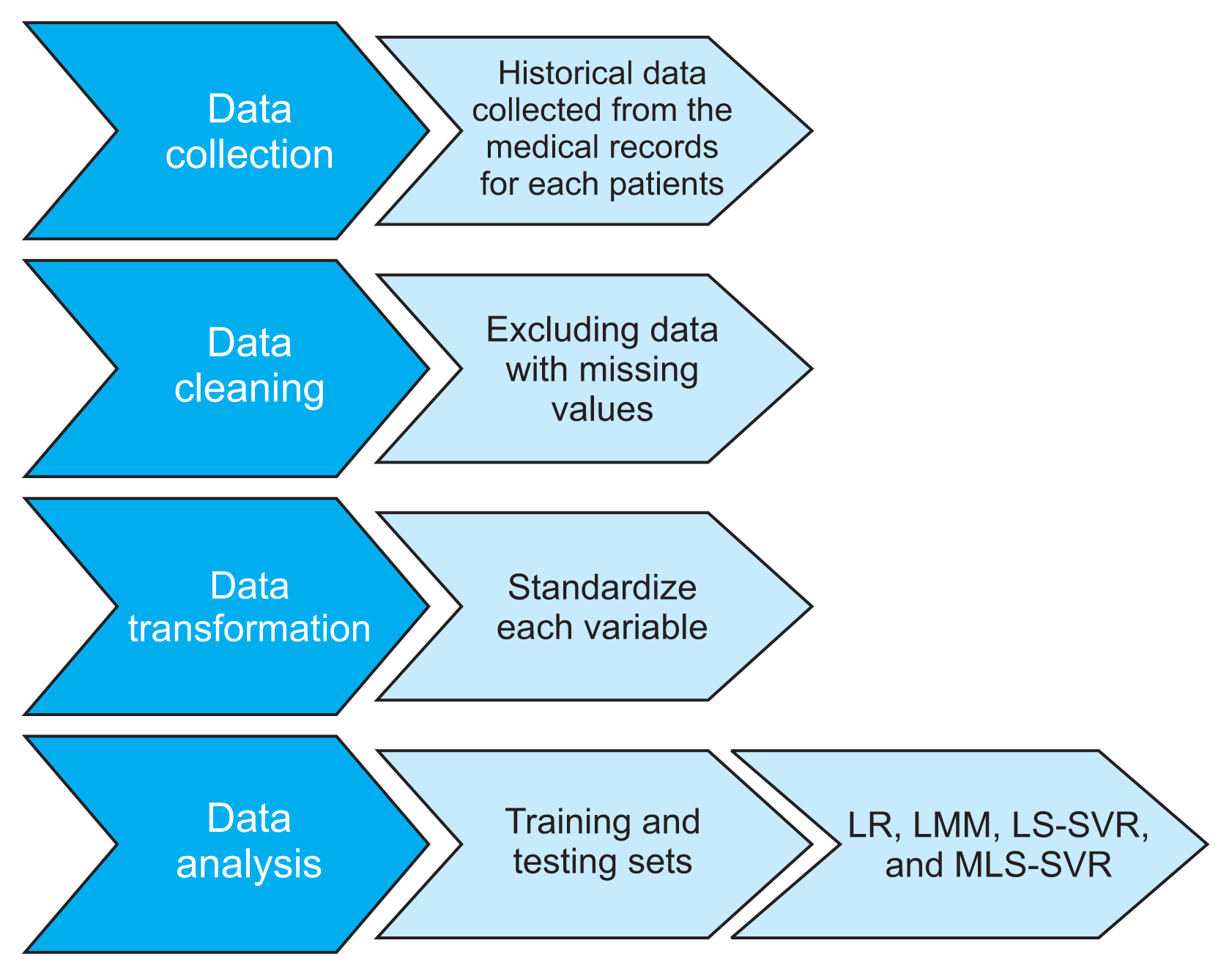
2. Classical Methods
LR and LMM are two classical models that were used in this study. The LR model is the most commonly used method for analyzing a continuous response variable with normal distribution. The effect of multiple covariates can be evaluated on the response variable in LR models [19]. For a N × p covariate matrix (x0), the prediction function of LR is expressed as
where (β0, βi) are the regression parameters.
LR may not be useful when the dataset has a multilevel or longitudinal structure. There is a correlation structure in longitudinal data that needs to be taken into account in analysis. The LMM is an extended form of the LR model. Random effects terms have been added to the LR for consideration of the correlation structure of the longitudinal data. The LMM prediction function for a given data of (x0, z0) is obtained as
Here, (β0, βi) are the model’s fixed parameters related to the N × p covariate matrix (x0), and vi~N(0, ∑v) are the random effects parameters related to z0 which are the random effect variables.
3. Machine Learning Approaches
We used the ordinary LS-SVR and the MLS-SVR methods to predict serum creatinine. The LS-SVR model was explained by Suykens et al. [12] for regression problems in linear or nonlinear forms. The basic property of nonlinear LS-SVR is the use of the kernel technique. The input data are mapped into a higher-dimensional space with kernel functions. Although a linear fitting is done in the new high-dimensional space, the fitting in the original input space is non-linear [20]. There are multiple kernel functions; the one that is most commonly used is the radial basis function (RBF) [12]. We used the RBF as the kernel function in this study. The prediction function of nonlinear LS-SVR for a given N × p matrix (x0) is introduced as
where (α,b) are the model parameters, and K(xi, xo) = ϕ′(xi) ϕ(x0) is the kernel function. Here, ϕ(.) is the nonlinear mapping function, which is used in LS-SVR for nonlinear fitting of the data [12].
The MLS-SVR is the extended model of ordinary LS-SVR in which random effect terms are added for consideration of the correlation structure of the longitudinal data [16]. The MLS-SVR has the following prediction function for a given (x0, z0):
Here, vi~N(0,∑v) are the random effects parameters related to the random-effects covariate matrix, and x0 is the fixed-effects covariate matrix, and K is the kernel function. Also, xij is the jth observation of the ith patient for j = 1, 2,…, ni and i = 1, 2,…, N.
The parameters in the Equations (3) and (4) are estimated by constructing the Lagrange function and solving a linear system [12,14].
4. Evaluation Criteria
We evaluated the generalization performance of each model in the training and testing samples. Some criteria were used to compare the performance of the models, such as mean squared error (MSE), mean absolute error (MAE), mean absolute prediction error (MAPE), and determination coefficient (R2) as follows:
5. Variable Importance
Evaluating the variable importance (VIMP) was another aim of this study. We used a permutation procedure with 100 iterations to specify the importance of each variable in predicting creatinine [21,22]. In the permutation procedure, one variable was permuted, and the others were fixed. The original MAE was obtained from the prediction of creatinine in the original dataset. Then each variable was permuted 100 times, and the new MAE was obtained from each permutation for each variable. The mean of differences between the new and the original MAEs was considered as the importance criterion.
Go to :
III. Results
Among 158 hemodialysis patients in the study, 53.8% were male, 43% were hypertensive, and 39.9% were diabetic. Also, 58% of the patients were given dialysis three or four times in a week. The descriptive statistics of some variables of the patients are shown in Table 1.
Table 1
Descriptive statistics of hemodialysis data
![]()
The results of fitting the LMM for serum creatinine are displayed in Table 2. All of the independent variables were significant except the FBS and diabetes variables.
Table 2
Regression coeficient of covariates of fitting the linear mixed-effects model to serum creatinine
![]()
We used serum creatinine as the response variable. After dividing the longitudinal dataset into training and testing sets, we fitted the LR, LMM, LS-SVR, and MLS-SVR methods to the training set and investigated the fitting performance of each model. Then we evaluated the generalization performance of the models using the testing set. The results are shown in Table 3.
Table 3
Performance of the models in predicting creatinine for training and testing sets
![]()
As seen in Table 3, the MLS-SVR method achieved the best generalization performance based on all criteria. Also, there was a decrease in the prediction performance by ignoring the random effect terms in both LMM and MLS-SVR methods.
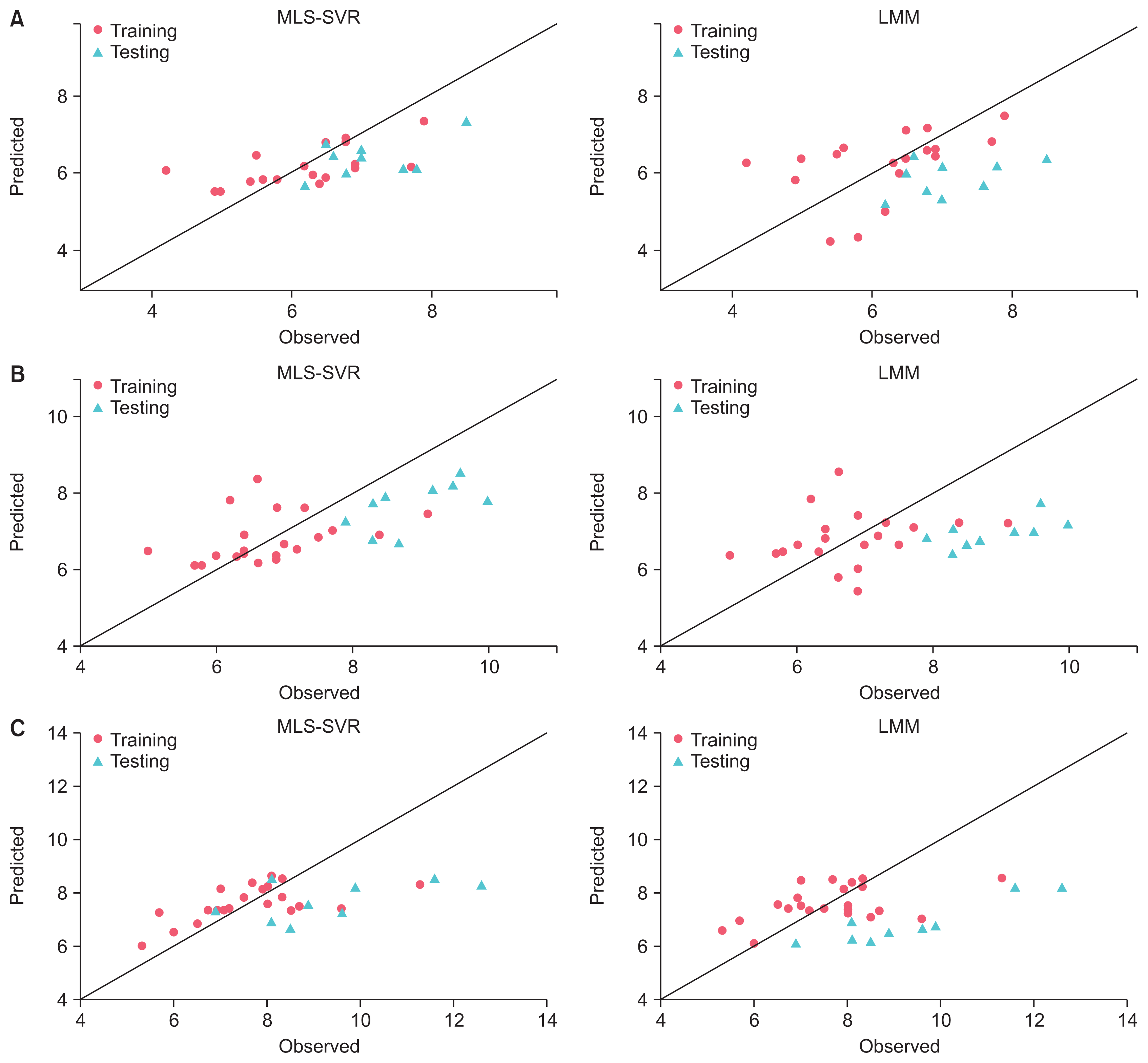
Figure 2 shows the observed versus predicted values of training and testing sets of 3 patients to compare the prediction performance of the MLS-SVR and LMM methods. As seen, the prediction performance of the MLS-SVR method was better than that of LMM for both the training and testing data (the points in the MLS-SVR method were closer than those in the LMM method to the bisector line).
Finally, we obtained the VIMP (the mean of changes in MAE after permutation in each variable) in the prediction of creatinine using the MLS-SVR method (Figure 3). BUN, time, age, FBS, and HCT were the top rank variables among other variables. Indeed, there were more changes in the MAE criterion after the permutation of these variables.
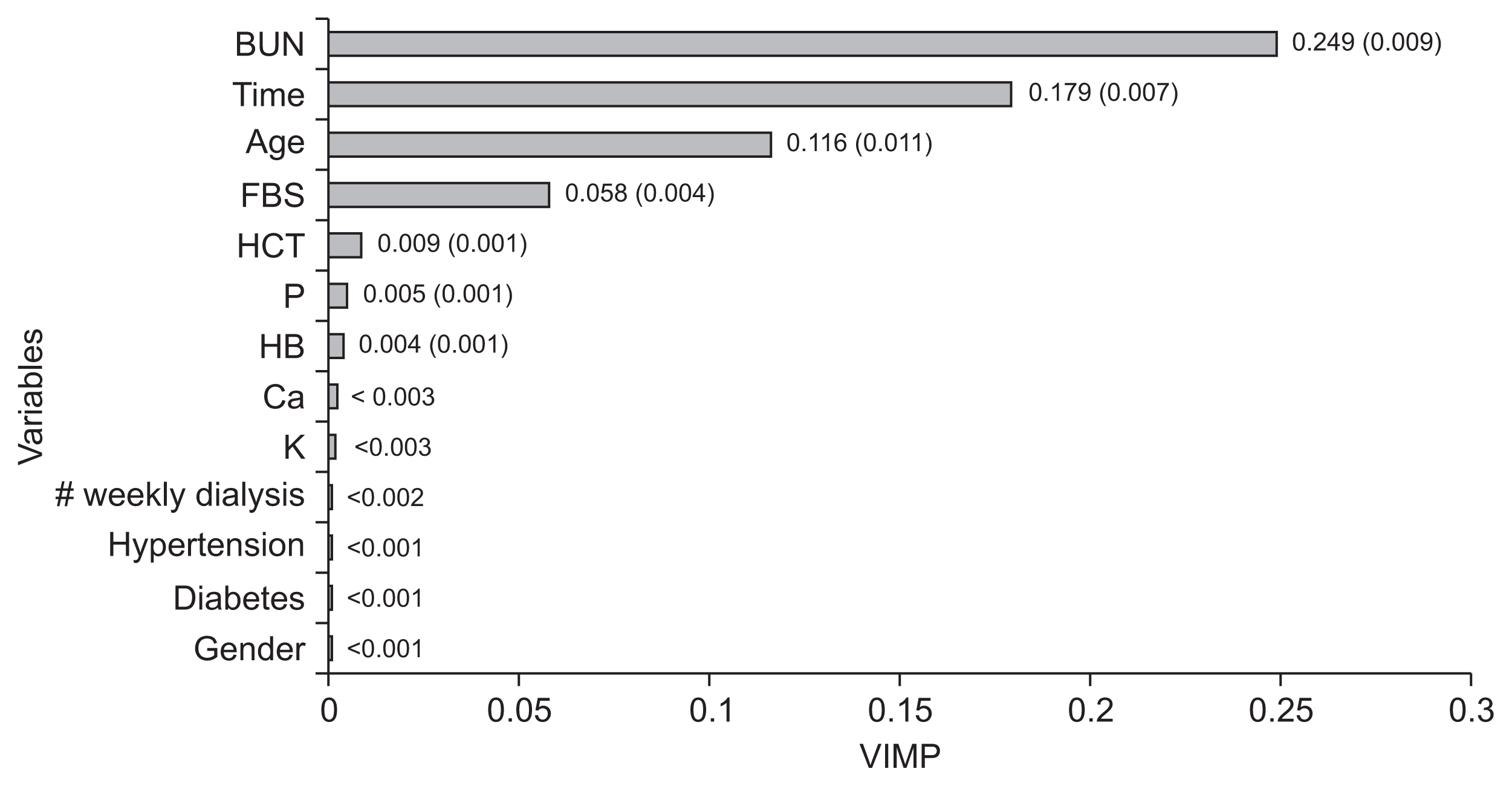 | Figure 3Variable importance (VIMP) of each factor in prediction of creatinine using MLS-SVR method. Mean of changes in MAE after each permutation (standard error). BUN: blood urea nitrogen, FBS: fasting blood sugar, HCT: hematocrit, P: phosphorous, HB: hemoglobin, Ca: calcium, K: potassium, MLS-SVR: mixed-effects least-squares support-vector regression, MAE: mean absolute error.
|
Go to :
IV. Discussion
In this study we compared the performance of four models in predicting the serum creatinine of hemodialysis patients by various random and fixed-effects approaches. The performance of both random effects models (MLS-SVR and LMM) was better than that of their fixed-effects counterpart models (LS-SVR and LM) in terms of generalization. It was demonstrated that random effect terms were effective in the prediction of creatinine and that they must be considered in the modeling process.
The MLS-SVR method achieved better performance than the LMM for both the training and testing datasets based on all criteria (Table 3). Figure 2 confirms this result, where the MLS-SVR achieved better performance for both training and testing samples for all 3 patients (the points are closer to the bisector line). Also, the prediction performance of the LS-SVR was better than that of the LR in the fixed-effects models (Table 2). Therefore, it is possible that there are complex or nonlinear relationships between some covariates and creatinine which the LMM and LR could not take it into account.
Limited studies have used support vector machine (SVM) approaches in the prediction of longitudinal continuous or categorical responses. In a study that compared several SVM methods for classification problems using simulation and real longitudinal data, the mixed-effects SVM achieved better performance than the other SVM models [23]. For a regression problem, Seok et al. proposed a mixed-effects LS-SVR. They used their proposed method for pharmacokinetic (PK) and pharmacodynamic (PD) datasets and compared their proposed model with the standard approach for the analysis of population PK and PD data. It was shown that the proposed MLS-SVR achieved the best performance for both training and testing data [16]. In another study that used the LS-SVR technique for longitudinal data, the LS-SVR method achieved better prediction performance than LMM in two real data examples and two simulation studies [14]. In a study on a three-level brucellosis frequency data, the MLS-SVR method achieved better prediction performance than the ordinary LS-SVR and classical models [15].
According to the variable importance that was calculated using the random effects MLS-SVR, BUN was the most important variable in the prediction of the creatinine. Time, age, and FBS were the other variables that were important for creatinine prediction. Also, as seen in Table 2, BUN, HCT, HB, K, P, Ca, age, gender, number of weekly dialysis sessions, and hypertension had a significant effect on the value of serum creatinine. The age factor has been reported as a variable that affects serum creatinine [24,25].
In conclusion, our study showed that the MLS-SVR achieved the best performance in terms of generalization and that it could produce more accurate predictions of serum creatinine. Also, random effect terms had an impressive positive effect on prediction performance. Finally, in the presence of high dimensional or/and complex data-sets SVM approaches may be more useful than classical methods.
Go to :
 XML Download
XML Download