

 PDF
PDF ePub
ePub Citation
Citation Print
Print


Introduction
Determining a final model among many competitive models is usually not a matter of “right or wrong” but of “better or worse.” In other words, it is important to remember the famous statement by George Box, “All models are wrong, but some are useful.”
A result of bioequivalence study with separate hospitalization was discussed at the Central Pharmaceutical Affairs Advisory Committee (CPAC) by the Korea Ministry of Food and Drug Safety (MFDS) in January 2017. The content of this article is the authors' opinion as expert advisors. The sponsor company agreed on the publication this information and provided the data for this article.
Methods
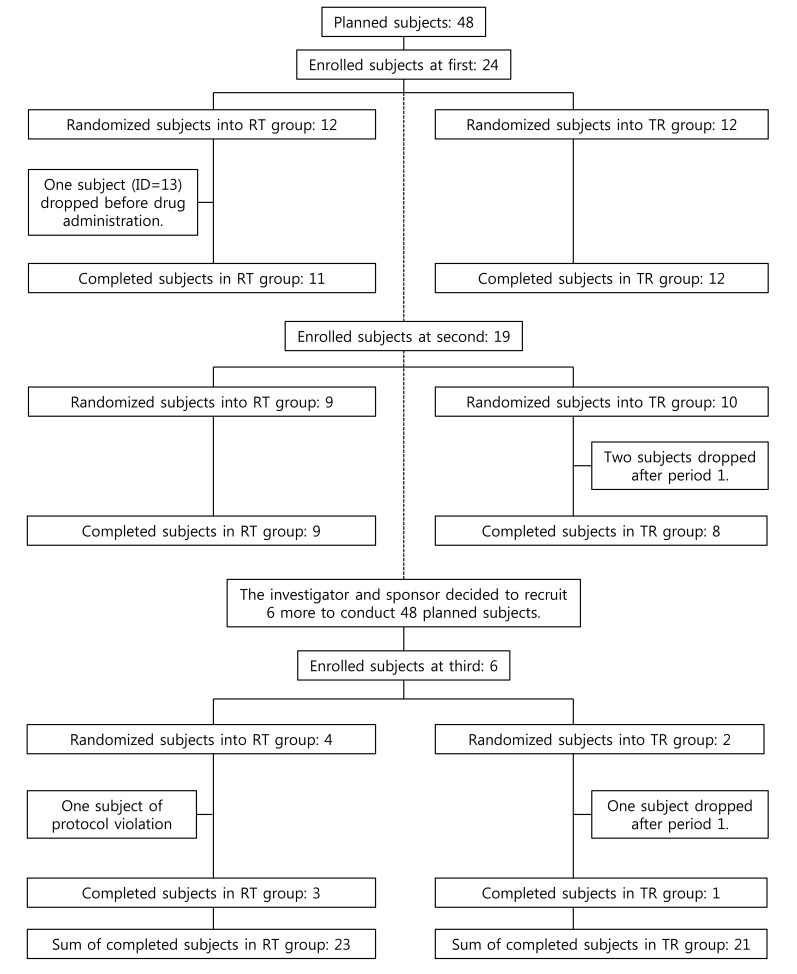
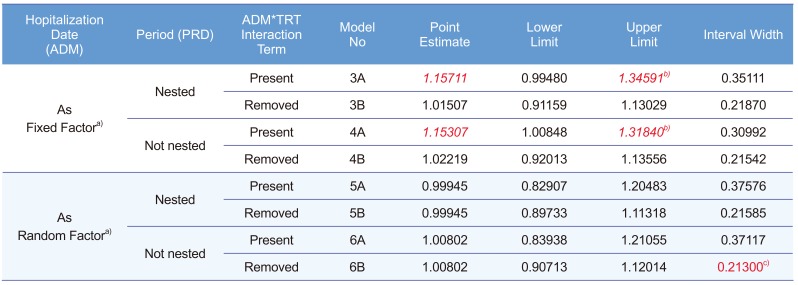
A 2×2 bioequivalence study was planned to include 24 subjects for each of the two treatment sequence groups (48 subjects in total). The study requested the subjects to have long period of hospitalization with strict inhibition of sunlight exposure. Therefore, there were not many volunteers for this condition. Subject disposition is shown in Figure 1 and maximum concentration (Cmax) data is listed in Table 1.
Results
Model 1. Independent two-group t-test
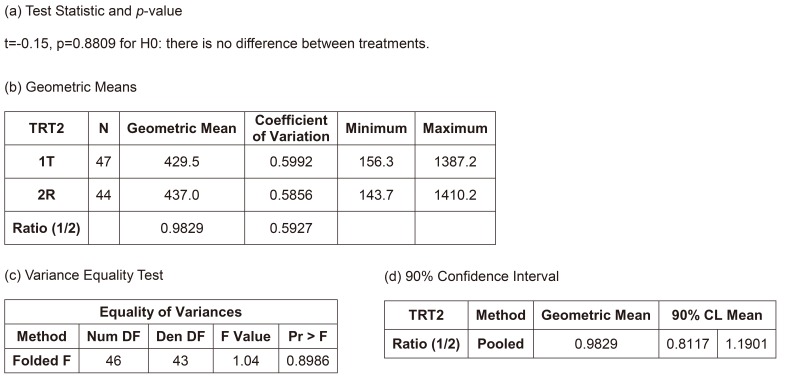
Figure 3 shows the summary of results of the independent two-group t-test, the most naïve approach. The equality of variances between the treatments could be assumed (p=0.8986), and the null hypothesis (i.e., there is no difference between the treatments) could not be rejected (p=0.8809). The width of 90% confidence interval (CI) for the geometric mean ratio was 0.3784, which is relatively wide and means the most inefficient method presented in Table 2. However, the bioequivalence of the test treatment, within the limit of [0.8, 1.25], was observed. However, this model is not acceptable as a final model by any regulatory body. Current regulatory guidelines request bioequivalence study to include the effects such as sequence, period, and random subject effect nested within the sequence in the final model.
Model 2. Conventional 2×2 model
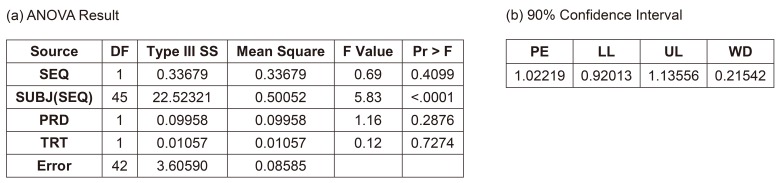
If we ignore the effect of separate hospitalization (drug administration), the final model could be the conventional 2×2 crossover bioequivalence study model (Fig. 4). This model can only be used after the full model (considering the effect of separate hospitalization) is examined and when the additional effects such as hospitalization date can be ignored. This was the final model of the sponsor company after consulting a professor of statistics who advised that those insignificant additional effects (hospitalization and its interaction effects) could be removed.
Model 3A. Full model with administration (ADM) as fixed factor and period (PRD) nested within ADM
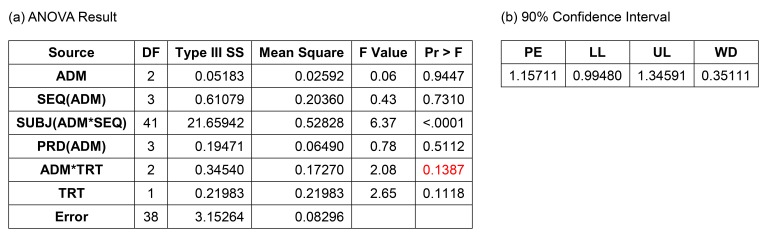
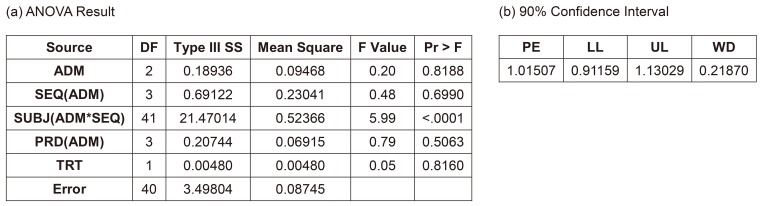
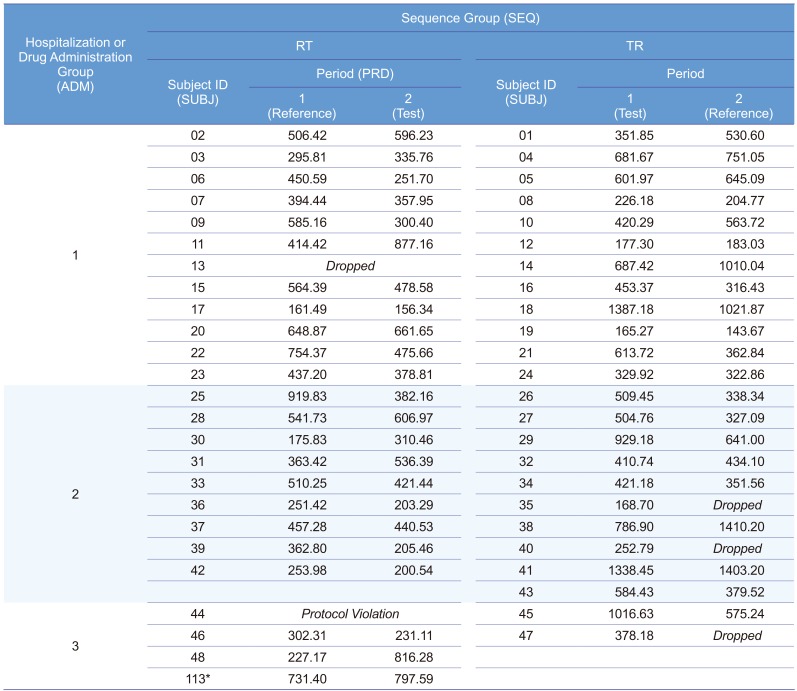
Figure 5 shows the result of this model. The interaction term between ADM and treatment was not significant (p = 0.1387), and many statisticians would agree to remove this term. The 90% CI (0.99480–1.34591) did not meet the bioequivalence limit, which was the main reason why the Korea MFDS summoned CPAC. In fact, European Medicines Agency (EMA) prohibited this kind of analysis, but some CPAC members wanted this to be the final model or analysis.
Model 3B. Reduced model of 3A by removing the interaction term between ADM and treatment
After removing the insignificant interaction term, the CI (0.91159–1.13029) satisfied the bioequivalence criteria, and the analysis of variance (ANOVA) result was acceptable (Fig. 6). Many statisticians would be comfortable with this as a final model. A more simplified model, such as Model 2, would also be acceptable. The ANOVA table shows satisfactory F values for further pooling of the terms into the error term to increase the efficiency of the estimation, which are explained in the statistics textbooks of experimental designs.[1] A rule of thumb for pooling is “F ≤1.” This model is the same one that the EMA suggested.[2]
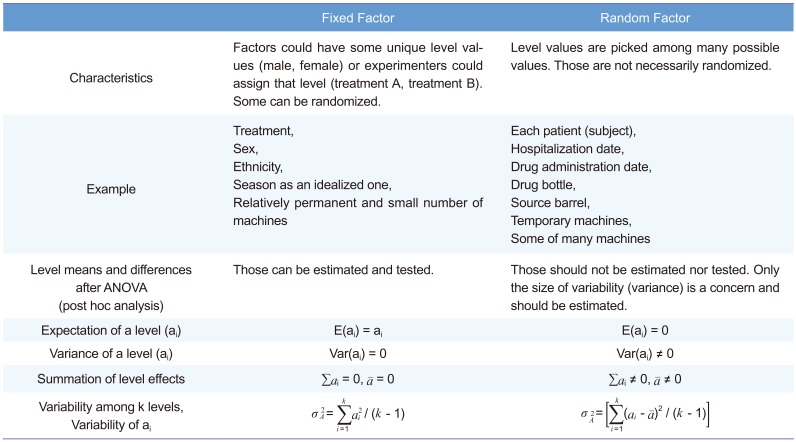
Model 4A. Full model with ADM as fixed factor and PRD not nested
The EMA suggests using Model 3B, in which PRD is nested within the ADM. However, some may consider PRD as not-being nested. The ANOVA result are not much different (data not shown), the CIs of this and other models are summarized in Table 3. This model along with all the following models showed desirable ANOVA results and satisfied the bioequivalence criteria.
Model 4B. Reduced model of 4A by removing the interaction term between ADM and treatment
After removing the insignificant interaction term, the result met the bioequivalence criteria. The confidence limit is summarized in Table 3.
Model 5A–6B. Models considering ADM as a random factor and using PROC MIXED to include the subject data with PRD 1 only
The Models 5A–6B corresponded to Models 3A–4B, respectively, using PROC MIXED instead of PROC GLM for the CI calculation. PROC MIXED used the data of subjects who dropped out after PRD 1, whereas PROC GLM did not. Another important difference of these models is considering ADM as a random factor based on the statistics textbook.[1] Models 5A and 5B seem controversial because some consider that a fixed factor (PRD) nested within a random factor (ADM) should be a random factor.[3] All models examined here showed satisfactory results and met the equivalence criteria. The CIs are summarized in Table 3. Model 6B was the most efficient model and showed the narrowest CI (Table 3). In addition, Models 3A and 4A show seemingly biased point estimations compared with the other models.
Discussion
All acquired data during the trial should be included, if they increase the precision, and do not cause more bias. Thus, we suggest that using PROC MIXED is better than using PROC GLM. Many references comparing PROC MIXED and PROC GLM are available recently.[456]
Another point of discussion is how to deal with the drug ADM (hospitalization) date as a fixed or a random effect. We strongly suggest that this effect should be considered random, following the textbook[1] written by Sung Hyun Park, a professor of statistics at Seoul National University and president of the South Korean Academy of Science and Technology. Many other references also support that.[3,7891011] Table 4 summarizes the fixed versus random factor concept. For both fixed and random factors, randomization is easy for some (treatment for fixed factor, drug bottle for random factor), while difficult for some others (sex for fixed factor, hospitalization date for random factor). Therefore, randomization is not a classification criterion.
Precision or efficiency (small or minimum variance) is one of the criteria used to judge whether an estimation is good or not. If bias is not a problem, a more precise estimation will result in a narrower CI. As seen in Table 3, Model 6B was the most efficient (CI width, 0.21300), and Model 6B is likely to be less biased than Models 3A or 4A. A possible reason for Models 3A and 4A being biased and less efficient can be found in the following paragraph from the EMA[2]:
A model which also includes a term for a formulation*stage interaction would give equal weight to the two stages, even if the number of subjects in each stage is very different. The results can be very misleading; hence, such a model is not considered acceptable. Furthermore, this model assumes that the formulation effect is truly different in each stage. If such an assumption were true, there is no single formulation effect that can be applied to the general population, and the estimate from the study has no real meaning.
Conclusion
...
3) A term for a formulation*stage interaction should not be fitted.
“Formulation” and “stage” in the above passage are equivalent to “treatment” and “hospitalization,” respectively, in the present article.
Many more models can be considered with different arrangement of effect terms. However, all important models are addressed here.
In a retrospective view, the third hospitalization should not be done, because the sample size of the earlier two hospitalization groups appeared sufficient (post hoc power analysis indicated 16 subjects/group achieved a power of 80%[12]), whereas the third hospitalization group was too small to be balanced. With one subject drop, the allocation ratio became 3:1. Therefore, one seemingly outlier subject (ID: 48) had high influence on the third group, which in turn had too much weight for the estimation, if we had used a fixed effect model. Meanwhile, random effect models of ADM were resistant to this kind of bias or outlier. In practice, we could not assign or specify ADM at the time of protocol development or trial planning nor could we reproduce that date effect thereafter. Moreover, ADM could not (and should not) be the concern of the fixed effect (i.e., the level means of specific dates are not our concern). A very large inter-day variability compared with that of the treatment effect can be a concern for doctors. However, this was not the case (F <1). Therefore, the authors insist the use of a random effect model for the hospitalization (or drug administration) date to increase efficiency and robustness. Table 5 shows the comparison of PROC MIXED and PROC GLM to help choosing a procedure.
Our prescriptive conclusions are summarized below from the highest to lowest priority:



 XML Download
XML Download