

 PDF
PDF ePub
ePub Citation
Citation Print
Print



INTRODUCTION
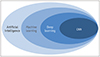
As artificial intelligence (AI) rapidly evolves, the fields to which it can be applied are also expanding to various industries worldwide. This has led to substantial advances in the specific fields, such as web search, self-driving cars, natural language processing, and computer vision. AI has also been applied in the medical field. AI is a branch of computer science devoted to creating systems to perform tasks that typically require human intelligence (1). AI is a term that encompasses various techniques. Among them, machine learning is a field of study that gives computers the ability to learn patterns from data without being explicitly programmed. Deep learning is a subset of machine learning that uses multiple layers to progressively extract higher-level features from raw input (Fig. 1). Deep learning is the most popular technique in the medical imaging field, especially for image classification, lesion detection, and segmentation (234). Studies using deep learning, also in the field of radiology, have been increasing with a rapidly growing propensity. Hence, many articles on deep learning have been published in radiology journals. However, the methods used differ between these studies and conventional clinical radiologic studies. The most significant difference is that the deep learning study, includes the process of developing algorithms. In this process, several concepts and terms unfamiliar to radiologists are used. As a result, radiologists who are not accustomed to deep learning may have difficulty in understanding and interpreting these studies. Therefore, in this review article, we aim to simplify the concepts and terms that frequently appear in deep learning radiology papers. We hope that this article will help general radiologists understand and interpret deep learning papers as well as make communication easier when collaborating with deep learning scientists.
Data
Ground Truth
Ground truth is a term used in various fields to refer to data and/or methods related to a greater consensus or to reliable values/aspects that can be used as references (5). In deep learning, it usually refers to “correct labels” prepared by experts. However, in practice, it is often difficult to make correct labels. For example, when developing an algorithm to diagnose pneumonia in chest radiography, the ground truth is whether there is pneumonia in the chest radiography. In this task, there are two ways to make labels. One is a method by which radiologists review images to make labels and the other is a method based on radiologic reports. In the former case, a lot of time and effort is required and there may be an inter-reader disagreement on the label. In the latter case, the correctness of the labels itself may not be satisfactory.
Data Curation
Data curation is the organization and integration of data collected from various sources to add value to the existing data. Data curation includes all the processes necessary for principled and controlled data creation, maintenance, and management. Medical imaging data curation may include data anonymization, checking the representative of the data, unification of data formats, minimizing noise of the data, annotation, and creation of structured metadata such as clinical data associated with imaging data.
Data Augmentation
Acquiring large amounts of good-quality data is often difficult in clinical radiology. Data augmentation is an approach that alters the training data in a way that changes the data representation while keeping the label the same. It provides a way to artificially expand a dataset and maximize the usefulness of a well-curated image dataset. Popular augmentations of image data include blurring or skewing an image, modifying the contrast or resolution, flipping or rotating the image, adjusting zoom, and changing the location of a lesion (6). These strategies essentially present a slightly different appearance of the same finding and can make a deep learning algorithm more robust and generalizable.
Training, Validation, and Test Dataset
Collected data are typically divided into three subsets according to their usage: training, validation, and test dataset. The training data are used to train and optimize the parameters of the model. The validation data are used to monitor the performance of the model during the training and to search for the best model. The test data are used to finally evaluate the performance of the developed model. It is crucial to divide the data to avoid any overlap between the training or validation datasets and the test dataset in terms of generalization of developed models. The required size of the dataset for training deep learning models depends on the nature and complexity of the task.
Development of the Model
Programming Languages and Deep Learning Frameworks
Programming language includes a vocabulary and a set of grammatical rules for instructing a computer to perform specific tasks. Popular programming languages include Python, Java, C, C++, C#, JavaScript, R, and MATLAB. The popularity of each programming language can be found on the TIOBE website (7). The deep learning framework is a collection of programs that facilitate the design, training, and validation of deep neural networks through a high-level programming interface. It supports massive arithmetic computation in the form of vectors, matrices, or multi-dimensional tensors on the latest graphics processing unit (GPU). Frameworks are generally written in a specific programming language. The popularity of Python is rising in the field of deep learning and data analysis owing to its ease of learning and the availability of many helpful deep learning libraries and frameworks written in python. There are several deep learning frameworks such as TensorFlow, Keras, PyTorch, Caffe, Theano, MXNet, and CNTK (8910). Google's TensorFlow and Facebook's PyTorch have been the most popular in recent times. Keras and Caffe will be merged into TensorFlow and PyTorch, respectively, in their next release. Theano has been deprecated and is no longer being maintained.
Parameter Versus Hyperparameter
The terms “parameter” and “hyperparameter” frequently appear in papers on deep learning. A parameter refers to a variable that is automatically adjusted during the model training. In general, weight is used as the same term as a parameter. However, weight is sometimes used as a sub-concept of a parameter in a convolutional neural network (CNN) to distinguish it from another term, “kernel.” In this case, weight refers to the parameters of a fully connected layer of CNN and kernel refers to the parameters of a convolutional layer of CNN. (The layers of CNN will be highlighted in the section, Convolutional Neural Network). Furthermore, a “hyperparameter” is a variable used to design the deep learning model and is a variable to be set before training the model. Hyperparameters in a CNN include kernel size, the number of kernels, stride, padding, activation function, pooling method, model architecture, optimizer, learning rate, cost function, batch size, and epochs. Some of these hyperparameters will be highlighted later in this paper.
CNN
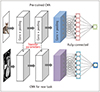
CNN is one of the artificial neural networks that can be characterized by a convolutional layer, which differs from other neural networks (Fig. 2). A typical CNN is composed of a convolutional layer, a pooling layer, and a fully connected layer (11). The convolutional layer is the core of a CNN. In mathematical terms, “convolution” refers to the mathematical combination of two functions to produce a third function. When used in a CNN, convolution means that a kernel (or filter = small matrix) is applied to the input data to produce a feature map (Fig. 3). The convolution operation has been widely used in image processing such as edge detection, sharpening, blurring, and so on. Through this process, different characteristics of the input images are extracted at different levels. The next step, pooling, is a down-sampling operation that reduces the in-plane dimension of the feature maps. The two common pooling methods are average pooling and max pooling method. Average pooling calculates the average value in the target area while max pooling extracts the maximum value in the target area. The fully connected layers (dense layers) map the features extracted by both the convolutional layers and the pooling layers to the final outputs of the model. One of the important components of CNN is an activation function. The activation function transforms the outputs of linear operations such as convolutions nonlinearly making the neural network capable of learning and performing more complex tasks. Although sigmoid or hyperbolic tangent functions were used previously, the most common nonlinear activation function is the rectified linear unit (ReLU) function. CNN is the most widely used deep learning model in medical image analysis for the following reasons (12). First, CNN is more efficient in terms of the number of parameters to be trained. In other regular neural networks, each layer is fully connected to all neurons in the next layer. The fact that two neurons are connected indicates that there is a parameter to be trained between the two neurons (not considering bias). Therefore, the number of parameters to be trained is huge in these regular neural networks. On the other hand, the neurons in one layer of CNN do not connect to all the neurons in the next layer but only to a small region of neurons in the next layer through the same kernel in the convolutional layers of CNN. In other words, the only parameters to be trained in the convolutional layers are the kernel in the convolutional layers. As a result, the number of parameters can be reduced in CNN. For example, when there is an input layer of 256 × 256 and an output layer of 256 × 256, there are a total of 42,9496,7296 ([256 × 256] × [256 × 256]) parameters in fully connected neural networks. On the other hand, if a 3 × 3 kernel is used in CNN, there are only 9 parameters that need to be trained. (Here we assume that the number of channels is only 1, i.e., gray-scale image.). Second, relevant features can be learned from an image (feature learning). In traditional image processing such as blurring or sharpening, kernels of the function are specific pre-defined filters. For example, smartphone applications can be used to make an original photo blurred or sharpened by using filters. In CNN, however, kernels are not pre-defined but are trained to perform a specific task from raw data. Kernels that are determined as the result of training are applied to the input images, then various feature maps at different levels are produced in the CNN. Third, CNN is more efficient for a completely new task because an already trained CNN (with trained parameters from another task, a concept that will be explained in more detail in transfer learning) can be slightly tuned for the new task. Finally, CNN has outperformed other algorithms on image analysis especially in pattern and image recognition applications until now. For example, all winners of the ImageNet Large Scale Visual Recognition Challenge (ILSVRC) that used CNN-based models, AlexNet, won the challenge in 2012 (12).
Recurrent Neural Network and Generative Adversarial Network
Recurrent neural network (RNN) is a class of neural networks effective at processing sequential inputs such as language, speech, and time-series data. In the radiologic field, RNN can be applied within domains such as electronic health records, including radiologic reports (1314). Generative adversarial network (GAN) is another deep learning algorithm where two neural networks of the generator and the discriminator compete and cooperate with each other. In the radiology field, GAN has been applied to synthesize realistic medical images (1516).
Pre-Trained CNN Models
As mentioned above, one of the advantages of CNN is its ability to use the pre-trained CNN models. Many recent studies have developed models based on these pre-trained CNN models. For tasks related to object recognition, many CNN models have been developed through the ILSVRC, which is an annual software competition conducted by the ImageNet project. The CNN models of the top competitors of ILSVRC include LeNet, AlexNet, ZFNet, GoogLeNet/Inception, VGG Net, DenseNet, and ResNet. Tasks related to segmentation include U-Net and Mask-RCNN (121718192021222324).
Transfer Learning
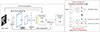
Transfer learning is the process of taking a pre-trained model and “fine-tuning” the model with a new dataset (Fig. 4). The idea is that this pre-trained model acts as a feature extractor. More specifically, the pre-trained CNN models of the ILSVRC extract features such as edges and curves for object detection and image classification. Unless a new task differs totally from the ImageNet project in the dataset and the problem, the layers of the pre-trained model can be reused for feature extraction. Fully connected layers, with or without parts of the kernels of the convolutional layers of the pre-trained model, are then replaced with a new set and are trained with the dataset of the new task. Transfer learning can lessen the data demands for development of CNN models because the number of parameters for training can be reduced by reusing the parameters of the pre-trained models. Transfer learning can be useful in radiology since the number of medical images is usually limited.
Cost Function (Loss Function)
Cost (loss) is the difference (not necessarily a mathematical difference) or compatibility between the true values (ground truth) and the values predicted by the model. A cost function (loss function) is a function comprising the true value and the predicted value and it is used to measure cost. The choice of the cost function used is determined based on the given tasks. Cross entropy and mean squared error are commonly used cost functions for classification tasks and regression tasks, respectively.
Forward Propagation and Back Propagation
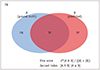
Forward propagation is a process used to calculate the predicted value from input data through the model. Back propagation is a process used to adjust each parameter of the model to minimize the cost (Fig. 5).
Gradient Descent
Model training is a process of parameter optimization used to minimize the difference between the true value and the model's predicted value. In CNN, the gradient descent method is used for parameter optimization, which further uses the gradient and learning rate to adjust the parameters. (Fig. 6). The gradient is a derivative of the cost function at a specific value of the parameter. The learning rate is a hyperparameter that controls how much the parameters of the model are adjusted. It is crucial to set the learning rate to an appropriate value. If the learning rate is very small, the model will converge too slowly. Conversely, if the learning rate is too large, the model will diverge (Fig. 7). There are three types of gradient descent that primarily differ in how much data are used to compute the gradient of the cost function. Batch gradient descent refers to calculating the derivative from all training data before calculating an update. Stochastic gradient descent (SGD) refers to calculating the derivative from each training data instance and calculating the update immediately. Finally, mini-batch gradient descent takes the best of batch gradient descent and SGD and performs an update for every mini-batch of n-training examples. Optimizing parameters with the gradient descent method may lead to problems when the same learning rate is uniformly applied to all parameters. Therefore, several algorithms have been developed for the optimization of the gradient and learning rate that need to be applied. These gradient descent optimization algorithms include SGD with momentum, Nesterov accelerated gradient, Adagrad, Adadelta, Adaptive Moment Estimation, and AdaMax (2526272829). However, none of them has a clear advantage over the other. The gradient descent optimization algorithm (the optimizer) is one of the important hyperparameters that must be determined in the model training process.
Epoch, Batch, and Iteration
In general, the entire large dataset cannot pass into the neural network at once. Therefore, the dataset should be divided in order to pass. An Epoch refers to one forward pass and one backward pass of all the training data through the model. Usually, we repeat several epochs to train a model. Batch size is the fixed number of training data in one forward/backward pass. Batch size is determined by considering the total size of the dataset, the number of weights in the model, and the available memory of the GPU. Batch size usually ranges from 1 to 128. The higher the batch size, the more memory space will be needed. The number of iterations is the total number of passes (Fig. 8).
Ensemble Method
An ensemble of models implies to train multiple models by varying architectures, hyperparameter settings and training techniques and to combine predictions of each model. This method generally improves prediction performance compared to that of a single model.
K-Fold Cross-Validation
Although the final performance of the model is determined by its performance on a test dataset, there is no means to predict how well a model will perform until its performance is tested on a test dataset. Cross-validation is a technique employed to estimate the performance of models in the “training” phase to check for overfitting and to get an idea about how the models will generalize to the given test dataset. In k-fold cross-validation, the training dataset is partitioned into k equal subsets. One data subset is kept as the validation set, and the others (k-1 subsets) are kept as a cross-validation training set. The model is then trained using the cross-validation training set, and the performance of the model is evaluated using the validation set. This process is repeated a total of k times while changing the validation set. The results from all the rounds are averaged to estimate the performance of the model.
Evaluation of Model Performance
For a classification task, receiver operating characteristic (ROC) curves are used for the model performance measurement. For a segmentation task, the Dice score (Sørensen-Dice coefficient = F1 score) and the Jaccard index (Jaccard similarity coefficient, Jaccard score = Intersection over Union) are used for model performance measurement (Fig. 9). In addition, the true positive rate = sensitivity = recall, true negative rate = specificity, false-positive rate, and false-negative rate can be used for model performance measurement depending on the given tasks.
CONCLUSION
This review article discusses the basic concepts of deep learning, especially CNN, and its commonly used terms. Radiologists who familiarize themselves with its concepts and terms will be better prepared to understand deep learning articles and to communicate with deep learning scientists.





 XML Download
XML Download