

 PDF
PDF ePub
ePub Citation
Citation Print
Print



INTRODUCTION
The use of artificial intelligence (AI) for medicine has recently drawn much attention due to the advances in deep learning technologies (1). Notably, there is a remarkable interest in using AI for diagnostic analysis of various types of medical images, primarily through convolutional neural networks, a type of deep learning technology referred to as “computer vision” (234). As with any other medical devices or technologies, the importance of thorough clinical validation of AI algorithms before their adoption in clinical practice through adequately designed studies to ensure patient benefit and safety while avoiding any inadvertent harms cannot be overstated (5678910). Note that the term “validation” is used in this study to imply confirmation, as would be used in the medicine field, and not algorithm tuning, which is used as technical jargon in the field of machine learning (1112). Clinical validation of AI technologies can be performed at different levels of efficacy: diagnostic performance, effects on patient outcome, and societal efficacy that considers cost-benefit and cost-effectiveness (1113). Proper assessment of the real-world clinical performance of high-dimensional AI algorithms that analyze medical images using deep learning requires appropriately designed external validation. It is recommended for the external validation to use adequately sized datasets that are collected either from newly recruited patients or at institutions other than those that provided training data in a way to adequately represent the manifestation spectrum (i.e., all relevant variations in patient demographics and disease states) of target patients in real-world clinical settings where the AI will be applied (101214151617). Furthermore, use of data from multiple external institutions is important for the validation to verify the algorithm's ability to generalize across the expected variability in a variety of hospital systems (14161718). Complex mathematical/statistical AI models such as deep learning algorithms that analyze medical images need a large quantity of data for algorithm training; producing and annotating this magnitude of medical image data is especially resource intensive and difficult (1920). Therefore, individuals developing such AI algorithms might rely on whatever data are available (methodologically referred to as convenience case-control data), although these may be prone to selection biases and artificial disease prevalence and likely not represent real-world clinical settings well (121920). Since the performance of an AI algorithm is strongly dependent upon its training data, there is a genuine risk that AI algorithms may not perform well in real-world practice and that an algorithm trained at one institution provides inaccurate outputs when applied to data at another institution (9161718192122).
Despite the excitement around the use of AI for medicine, the lack of appropriate clinical validation for AI algorithms seems to be a current concern, a phenomenon referred to as “digital exceptionalism” (162324). For example, computer scientists typically evaluate the performance of AI algorithms on “test” datasets; however, these are usually random subsamples of the original dataset, and thus, adequate external validation of clinical performance is not possible (10162025). To our knowledge, concrete data showing the exact extent of this perceived problem are scarce. This study aimed to evaluate the design characteristics of recently published studies reporting the performance of AI algorithms that analyze medical images and determine if the study designs were appropriate for validating the clinical performance of AI algorithms in real-world practice. The study design features addressed in this study are crucial for validating the real-world clinical performance of AI but would be excessive for proof-of-concept technical feasibility studies (14). As not every research study about the use of AI for medical diagnosis is to validate the real-world clinical performance (14), the purpose of this study was not to bluntly judge the methodologic appropriateness of the published studies.
Go to : 
MATERIALS AND METHODS
This study did not require Institutional Review Board approval.
Literature Search and Screening
PubMed MEDLINE and Embase databases were thoroughly searched to identify original research articles that investigated the performance of AI algorithms that analyze medical images to provide diagnostic decisions (such as either diagnosing or finding specific diseases or giving information to categorize patients with a particular disease into subgroups according to disease states, subtypes, severity levels, stages, treatment responses, prognosis, and risks). We used the following search query: (“artificial intelligence” OR “machine learning” OR “deep learning” OR “convolutional neural network”) AND (diagnosis OR diagnostic OR diagnosing) AND (accuracy OR performance OR “receiver operating” OR ROC OR AUC). We limited the search period to year 2018 to obtain timely results (literature search update until August 17, 2018). Both print publications and electronic publications ahead of print were included.
After removing overlaps between the two databases, articles were screened for eligibility by two independent reviewers. Articles with any degree of ambiguity or that generated differences in opinion between the two reviewers were re-evaluated at a consensus meeting, for which a third reviewer was invited. Case reports, review articles, editorials, letters, comments, and conference abstract/proceedings were excluded. Our search was restricted to human subjects and English-language studies. We defined medical images as radiologic images and other medical photographs (e.g., endoscopic images, pathologic photos, and skin photos) and did not consider any line art graphs that typically plot unidimensional data across time, for example, electrocardiogram and A-mode ultrasound. Studies investigating AI algorithms that combined medical images and other types of clinical data were included. AI algorithms that performed image-related tasks other than direct diagnostic decision-making, for example, image segmentation, quantitative measurements, and augmentation of image acquisition/reconstruction, were not considered.
Data Extraction
The full text of eligible articles was evaluated by two reviewers for the following information: 1) whether the study used external validation as opposed to internal validation, and in case of external validation, whether the data for validation were collected, 2) with diagnostic cohort design instead of diagnostic case-control design, 3) from multiple institutions, and 4) in a prospective manner. These are fundamental methodologic features recommended for clinical validation of AI performance in real-world practice (10111214). The more of these questions receive a “Yes” answer, the more generalizable to real-world practice the algorithm performance is. If a study validated its AI performance in multiple ways, then the study received a “Yes” answer for each of the above questions if at least one analysis used the design features. We defined “external” a bit generously and included the use of validation data from institution(s) other than the one from which training data were obtained, as well as cases where training and validation data were collected from the same institution(s) but in different time periods, even though the latter is not considered external validation in a strict sense (101625). For studies in which the training and validation datasets were collected at the same institution(s), validation data were only considered external if the clinical settings and patient eligibility criteria for the validation dataset were specified separately from those of the training dataset. This was to ensure that the validation data were not just a time-split subsample of the original large dataset, as that results in a type of internal validation (25). A diagnostic cohort design was referred to as one in which the study defined the clinical setting and patient eligibility criteria first and then recruited patients consecutively or randomly to undergo a particular diagnostic procedure, such as AI algorithm application (15). In contrast, a diagnostic case-control design would involve the collection of disease-positive and disease-negative subjects separately (15). Diagnostic case-control designs are prone to spectrum bias, which can lead to an inflated estimation of the diagnostic performance, and unnatural prevalence, which creates uncertainty regarding the diagnostic performance (1226). Additionally, we noted the subject field (e.g., radiology, pathology, and ophthalmology) of each article and classified the publishing journals into either medical or non-medical journal groups. The journals were classified primarily based on the Journal Citation Reports (JCR) 2017 edition categories. For journals not included in JCR databases, we referred to journal websites and categorized them as medical if the scope/aim of the journal included any fields of medicine or if the editor-in-chief was a medical doctor. Articles with any degree of ambiguity or that generated differences in opinion between the two independent reviewers were re-evaluated at a consensus meeting including a third reviewer.
Outcome Measures and Statistical Analysis
We calculated the percentage of studies that performed external validation. For studies reporting the results of external validation, the proportions of studies that involved the features of diagnostic cohort designs, inclusion of multiple institutions, and prospective data collection for external validation were identified. The results were compared between medical and non-medical journals using Fisher's exact test. A p < 0.05 was considered significant.
Go to :
RESULTS
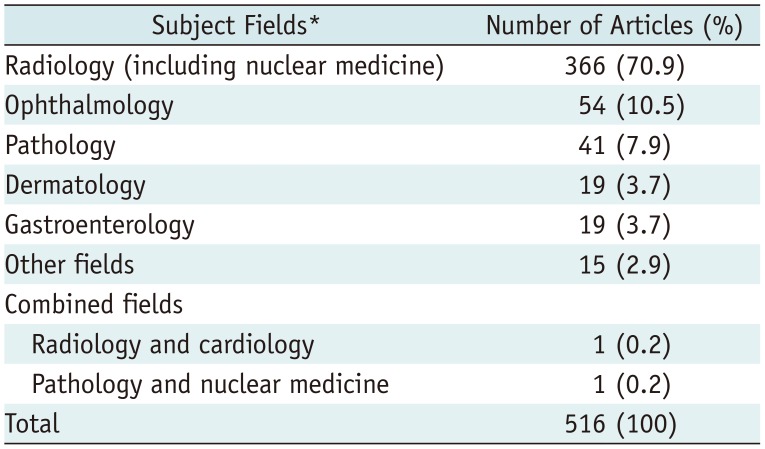
Of 2748 articles initially collected after removal of overlaps between PubMed MEDLINE and Embase, 516 articles were finally eligible (Fig. 1, Table 1). The full list of eligible articles analyzed in this study is available as an online supplement.
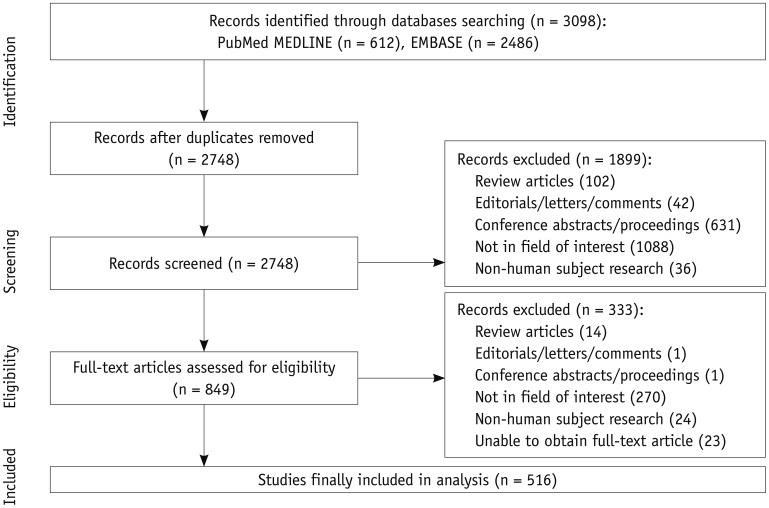 | Fig. 1Flow-chart of article selection based on preferred reporting items for systematic reviews and meta-analyses guidelines.
|
Table 1
Subject Fields of Articles Analyzed
![]()
Table 2 presents the proportions of the articles that had each design feature, including breakdowns for medical vs. non-medical journals. Only 6% (31 of 516) of the studies performed external validation. None of the external validation studies adopted all three design features, namely, diagnostic cohort design, inclusion of multiple institutions, and prospective data collection. No significant difference was found between medical and non-medical journals (Table 2).
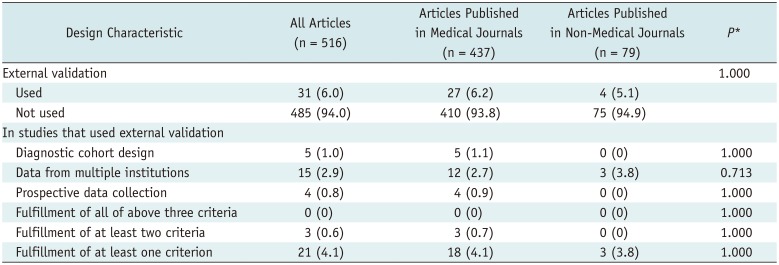
Table 2
Study Design Characteristics of Articles Analyzed
![]()
Go to :
DISCUSSION
Our results reveal that most recently published studies reporting the performance of AI algorithms for diagnostic analysis of medical images did not have design features that are recommended for robust validation of the clinical performance of AI algorithms, confirming the worries that premier journals have recently raised (2324). Our study did not consider various detailed methodologic quality measures for AI research studies (14), but simply evaluated major macroscopic study design features. Therefore, the extent of deficiency in the clinical validation of AI algorithms could likely be even more significant.
However, it should be noted that these results do not necessarily mean that the published studies were inadequately designed by all means. The four criteria used in this study–external validation and data for external validation being obtained using a diagnostic cohort study, from multiple institutions, and in a prospective manner–are fundamental requirements for studies that intend to evaluate the clinical performance of AI algorithms in real-world practice. These would be excessive for studies that merely investigate technical feasibility (14). Readers and investigators alike should distinguish between proof-of-concept technical feasibility studies and studies to validate clinical performance of AI (14) and should avoid incorrectly considering the results from studies that do not fulfill the criteria mentioned above as sound proof of clinical validation.
Some related methodologic guides have recently been published (111214). We suspect that most studies that we analyzed in this study may have been conceived or executed before these methodologic guides were made available. Therefore, the design features of studies that intend to evaluate the clinical performance of AI algorithms for medicine may improve in the future.
Another issue that was not directly addressed in our study but is worth mentioning is transparency regarding a priori analysis plans and full publication of all results in studies validating the clinical performance of AI algorithms (6111427). As the performance of an AI algorithm may vary across different institutions (161718), some researchers or sponsors might be inclined to selectively report favorable results, which would result in underreporting of unfavorable results. Prospective registration of studies, including a priori analysis plans, similar to the registration of clinical trials of interventions (e.g., at https://clinicaltrials.gov), would help increase the transparency of these studies (27). Prospective registration of diagnostic test accuracy studies, which include studies to validate AI performance, has already been proposed (28). The adoption of this policy by academic journals would help enhance transparency in the reporting of studies that validate the clinical performance of AI algorithms.
Our current study has some limitations. First, while the timeliness of research data is important (29), as AI is a rapidly evolving field with numerous new studies being published, the shelf life of our study results could be short. Ironically, we hope to see substantial improvements in the design of studies reporting clinical performance of AI in medicine soon. Despite such rapid changes, our research remains meaningful as the baseline against which comparisons can be made to see if any improvements are made in the future, given that most published studies that were analyzed here likely predated the recent release of related methodologic guides (111214). Second, while this study only evaluated studies reporting the diagnostic performance of AI, clinical validation of AI extends to evaluating the impact of AI on patient outcomes (1230). However, to our knowledge, studies of how AI application affects patient outcomes are scarce, and systematically reviewing published studies is not feasible.
In conclusion, nearly all of the studies published in the study period that evaluated the performance of AI algorithms for diagnostic analysis of medical images were designed as proof-of-concept technical feasibility studies and did not have the design features that are recommended for robust validation of the real-world clinical performance of AI algorithms.
Go to :
 XML Download
XML Download