

 PDF
PDF ePub
ePub Citation
Citation Print
Print



INTRODUCTION
Type 2 diabetes mellitus (T2DM) is a chronic disease in which the body's blood sugar metabolism is impaired and blood sugar levels are elevated.1 It is well known to be affected by lifestyle activities, such as drinking, exercise, dietary habits, and others. T2DM along with other chronic diseases, such as hypertension, obesity, dyslipidemia, arteriosclerosis, and angina, affects the quality of life and life expectancy.2 The short-term and long-term adverse effects associated with T2DM in patients with cardiovascular risk are well known.345 Thus, both early diagnosis and prevention of T2DM are very important to preventing multiple serious and potentially life-threatening complications in patients with cardiovascular risk. Recent studies have shown that improving lifestyle and medication interventions can prevent diabetic complications, and it maybe can prevent the onset of T2DM.67891011 Therefore, it is very important to identify individuals at high risk for T2DM in order to establish prevention strategies for T2DM.
Over the last few decades, many studies have proposed models for predicting T2DM. However, predictive models that are actively used in clinical practice have not been established.1213 The established models for predicting T2DM have typically been generated using Cox proportional or logistic regression (LR) analysis in non-diabetic patients between 5 to 15 years of follow up. These predictive models have some limitations: The performance of these predictive models have shown different results depending on the input variables, and the reproducibility of the prediction models is not guaranteed in not only established models but also other races and other populations. Also, a lot of time and resources are required to collect the data to make the model. In addition, models are just a statistical formula for multiple LR, and thus, the user accessibility of the model is not easy.
Machine learning has generally been used in the field of computer science, although it has been actively applied in the clinical medical field recently. Machine learning enables the definition of data attributes, and it allows for the prediction of various results using computational algorithms and computational power in large-scale databases with various parameters based on the available data.14151617 The purpose of this study was to develop a high-performance predictive model of T2DM using an electronic medical record (EMR) database and the machine learning method and to compare the performance of this model with predictive models developed using conventional statistical methods.
MATERIALS AND METHODS
Study population
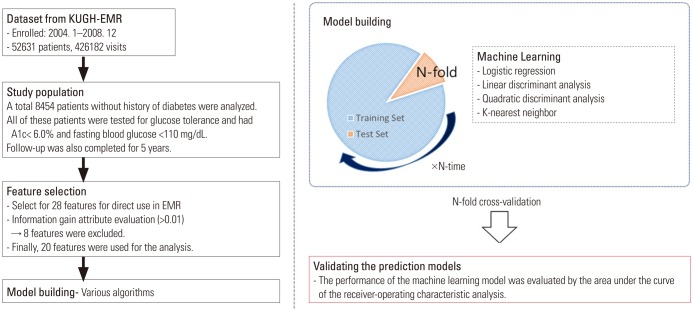
The data used in this study were obtained retrospectively from the EMR database of Korea University Guro Hospital (KUGH), and the protocol was approved by the Medical Device Institutional Review Board at KUGH (#KUGH 13017). The initially acquired subjects in the study comprised 52631 individuals (426182 visits during the study period) who visited the cardiovascular center of KUGH from January 2004 to December 2008. To clarify the results of the study, the subject with diabetes or without information on glycemic control were excluded. Finally, a total of 8454 patients who had no history of diabetes, a fasting blood glucose level of <110 mg/dL, glycated hemoglobin <6.0%, and no anti-diabetic agent treatment were enrolled in this study. All subjects completed 5 years of follow up (Fig. 1). The prevalence of T2DM was 4.78% (404/8454) during follow up.
Clinical data and data collection
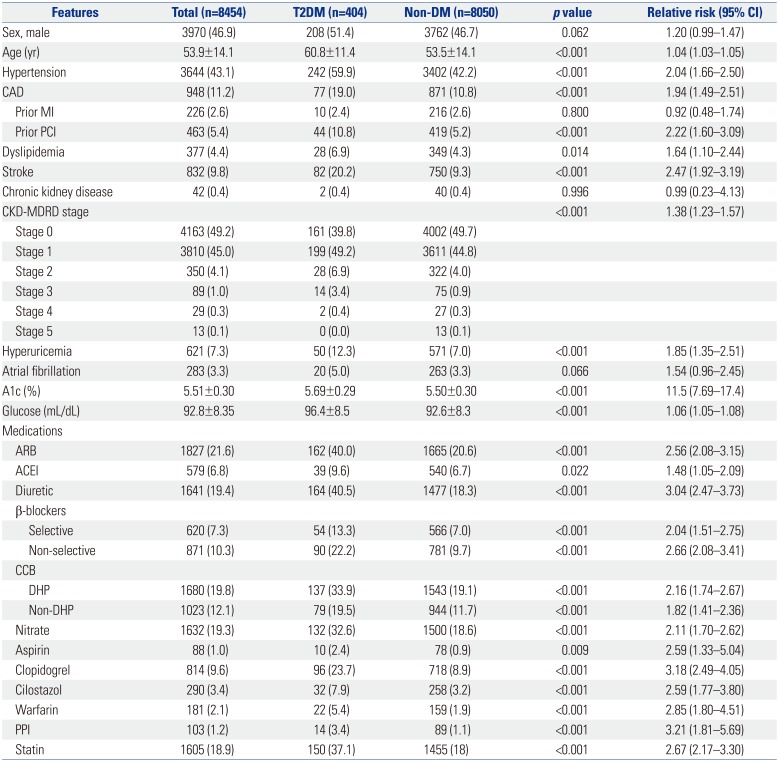
Personal data, such as ‘patient name’ and ‘personal identification code,’ among the data used in the analysis were provided from KUGH by generating a separate code in the dataset for privacy protection and patient identification. The predictors (or features) chosen to develop prediction of T2DM that could be extracted from the EMR were as follows: sex, age, body mass index, history of particular diseases (hypertension, coronary artery disease, myocardial infarction, coronary intervention, dyslipidemia, cerebrovascular disease, renal disease, and hyperuricemia), blood test results (fasting serum glucose, glycated hemoglobin, creatinine, total cholesterol, triglyceride, high density apolipoprotein, and low density apolipoprotein), pharmaceutical treatments for cardiovascular disease (renin-angiotensin system inhibitors, diuretics, beta blockers, calcium channel blockers, anti-anginal agent, antiplatelet agents, and statins), and pharmaceutical treatments for T2DM (meglitinides, biguanides, sulfonylureas, α-glucosidase inhibitors, thiazolidinediones, dipeptidyl peptidase-4 inhibitors, and insulin) (Table 1, Fig. 2). Among these variables, those missing information by more than a total of 30%, such as body mass index, were excluded from the model. Antidiabetic agents were used to identify the presence of diabetes in the subject at baseline or follow-up.
Definition and study endpoints
In this study, T2DM was defined as fasting blood glucose ≥126 mg/dL, glycated hemoglobin ≥6.5%, or the presence of a prescription for antidiabetic medication by a clinician.1 To improve the accuracy of the predictors used in the study, we cross-analyzed the records of the international conference for the ninth revision of the International Classification of Diseases (ICD-9) and clinical prescribing records recorded in the dataset. Hypertension was defined as ICD-9; 401–405 and the prescription of antihypertensive agents, myocardial infarction (ICD-9; 410–412), angina pectoris (ICD-9; 413), and cerebrovascular disease (ICD-9; 430–438). Dyslipidemia, hyperuricemia, and renal disease were defined according to relevant guidelines reflecting blood test results. Dyslipidemia was defined according to the guidelines of the National Cholesterol Education Program.18 Hyperuricemia was defined as >7.0 mg/dL for men and >6.5 mg/dL for women.19 Renal disease was assessed by the risk of an impaired glomerular filtration rate (MDRD: modification of diet in renal disease).20 The endpoint of this study was the generation of a model predicting the occurrence of T2DM within 5 years of follow-up, presenting the predictive rates of the models as the receiver operating characteristic (ROC) curve and the area under an ROC curve (AUC).
Machine learning
For this study, 28 features were available from the EMRs for model development (Table 1, Fig. 2). The use of continuous variables, such as blood test results, in machine learning model generation requires a lot of computing power and time. In this study, these continuous variables were reflected as categorical variables, such as dyslipidemia, hyperuricemia, and renal disease, for efficient allocation of resources. The T2DM prediction model was generated by LR, linear discriminant analysis (LDA), quadratic discriminant analysis (QDA), and the K-nearest neighbor (KNN) classification algorithm for machine learning. MATLAB® R2016b (MathWorks, Natick, MA, USA) was used for technical support of the machine learning techniques.
Feature selection
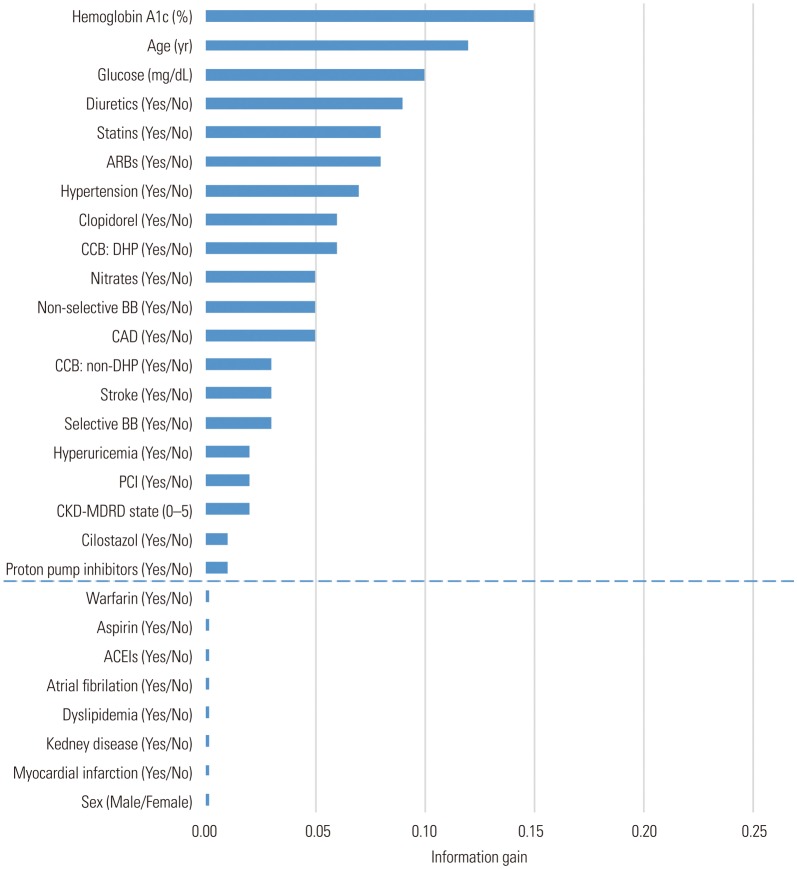
The selection of features for generation of the T2DM prediction model was performed by ‘information gain attribute evaluation.’2122 This is a classifier strategy for selecting the features of the prediction model. The selected features are derived from the Ensemble classification model using a single-node decision tree and the LogitBoost algorithm.21222324
Cross-validation test
Model performance and general error estimates in the machine learning process were evaluated using stratified 10-fold cross-validation tests, which is a preferred technique in the field of data mining.2526 This technique randomly divides the dataset into 10 equal parts, so that each part has the same number of events. A 10-fold cross-validation test is used for the validation of each part, and the remaining nine parts are used as the learning dataset, so that, ultimately, 10 LogitBoost models are generated. The performance of the entire machine learning strategy is measured by combining the validation results of the 10 generated models (Fig. 2).
Machine learning algorithms
Logistic regression
LR is a widely used algorithm in epidemiological studies and was used as a reference for comparison with the other algorithms for analyzing data. The purpose of LR is to use the relationship between the dependent and independent variables, as detailed, for the purpose of general regression analysis for future prediction models. The LR dependent variable can be understood as a classification technique because it divides the results into specific categories for the categorical data.
Linear discriminant analysis
LDA is the most commonly used algorithm in the field of machine learning. It is a method of classifying data by learning the distribution of the data and creating a decision boundary. When classifying the given data into K classes, it is directed to find a straight line where the center (average) of each class is distant and dispersion is small.
Quadratic discriminant analysis
QDA is a more flexible classification method than LDA, which can only identify linear boundaries, because QDA can also identify secondary boundaries. Both QDA and LDA assume that the observations of each class follow a normal distribution; however, QDA assumes that the covariance matrix of each class is different from LDA. This implies that the Bayesian theorem assigns an initial estimate to the parameter. QDA assigns an observation to the class that maximizes the quantity of the parameter so that a quadratic function-type discriminant emerges.
K-nearest neighbor
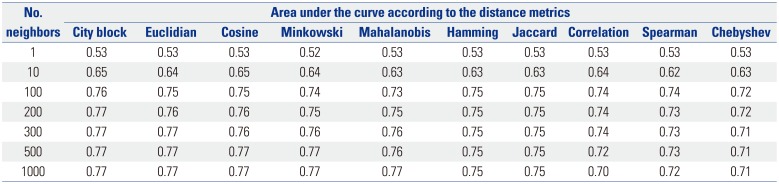
The KNN algorithm is a new method to predict new data with K neighbors from the existing data when new data is provided. This is a method of classification using only the instance, without a model generation process. The hyper-parameters (detailed tuning options for efficient learning of the model) of the KNN algorithm are the number of neighbors (K) to be searched and the distance measurement method. If K is small, it overestimates the regional characteristics of the data (Overfitting), and if it is very large, the model tends to be over-normalized (Underfitting). Also, the KNN algorithm is one whose result is greatly affected by the distance measurement method chosen. In this study, we investigated the optimal K in the KNN analysis of the clinical medical data and verified the model performance according to each distance measurement method. The distance measurement method of KNN was evaluated for each city block, Euclidian, Cosine, Minkowski, Mahalanobis, Hamming, Jaccard, Correlation, Spearman, and Chebyshev models.
Statistical analysis
In this study, the comparison of ‘continuous variables’ between the two groups was evaluated by unpaired t-test or Mann-Whitney rank test and expressed as the mean±standard deviation (SD). Comparisons of categorical variables between the two groups were assessed by χ2 or Fisher's exact test and expressed as a number and a percentage. Each parameter used to predict T2DM underwent a relative risk analysis. The performance evaluation of the learning model generated by machine learning was evaluated by the AUC of ROC analysis. The statistical significance in this study was p<0.05.27
RESULTS
In this study, a total of available 8454 patients who had no history of diabetes and were treated at the cardiovascular center of KUGH were enrolled. Also, a total of 28 features were extracted from the EMRs. Basic information for the patients at the time of registration is shown in Table 1. The prevalence of T2DM was 4.78% (404/8454) during follow up.
In order to develop a predictive model of T2DM using machine learning, the ‘information gain attribute evaluation method’ was performed (Fig. 2). Among the 28 features, parameters regarding sex, dyslipidemia, chronic renal failure, history of myocardial infarction, and cardiovascular medication (aspirin, warfarin, angiotensin-converting enzyme inhibitor) were excluded because they carried information values less than 0.01.
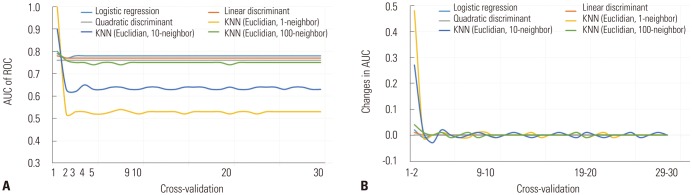
In order to verify the cross-validation test, various predictive models were generated using LR, LDA, QDA, and KNN algorithms and machine learning. KNN algorithm models were generated to Euclidean distance measurement with nearest neighbors equal to 1, 10, and 100. The change in AUC value was assessed by performing a cross-validation test from 1 to 30 fold. The SD of the AUC of the LR, LDA, QDA, and KNN (Euclidean model with the nearest neighbor 100 neighbors) models were within a range of 0.01, and the SDs of the AUCs of the Euclidean KNN model with 1 and 10 near neighbors were 0.08 and 0.05, respectively, for the cross-validation test from 1 to 30 fold. All of the predictive models maintained a change within the SD of the AUC <0.01 in the analysis after the 10-fold cross-validation test (Fig. 3).
The KNN model for the generation of the predictive model of T2DM was composed of 1, 10, 100, 200, 300, 500, and 1000 near neighbors for the optimization evaluation of the prediction model according to the hyper-parameters. Distance measurement between neighbors was Euclidian, Cosine, Minkowski, Mahalanobis, Hamming, Jaccard, Correlation, Spearman, and Chebyshev. The 10-fold cross-validation test was applied to assess the results and is shown in Table 2. In performance evaluation of the KNN model, the highest AUC was 0.77, with the near-neighbor values equal to 200 for the city block, 300 for the Euclidian, 500 for the Cosine and Minkowski, and 1000 for the Mahalanobis distance.
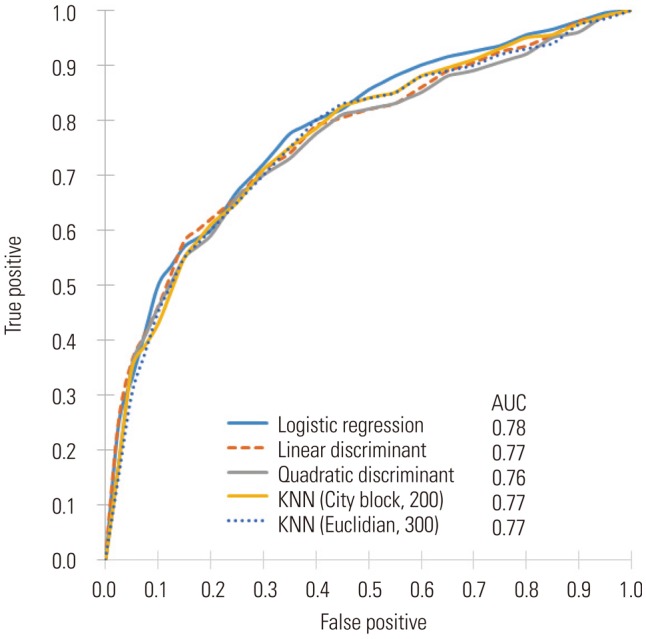
Fig. 4 shows the results of the 10-fold cross-validation test regarding the T2DM predictive model using LR, LDA, QDA, and KNN with Euclidian and near-neighbor values equal to 200 or 300. Mostly, the performance of the developed T2DM prediction models converged around AUC 0.77 in this study. Compared with the LR model, in which the performance was greatest (AUC=0.78), the models of the LDA, QDA, and KNN algorithms did not show a statistically significant difference.
DISCUSSION
Recently, as medical records have become electronic databases, the utilization of big data is considered to be clinically valuable. However, if these data cannot be made clinically relevant to our real-world clinical practice, they become useless. In order to be useful and valuable, data must be analyzed, interpreted, and translated into clinical practice. Machine learning is an emerging tool for processing and utilizing big data.14151617 The development of machine learning in clinical medicine is expected to be a powerful tool for clinicians.15 Thus, studies are being actively conducted to apply machine learning to clinical medicine.222628 In the present study, we generated a predictive model of T2DM using LR, LDA, QDA, and KNN algorithms and performed a cross-validation test to verify the performance of a machine learning disease prediction model. Moreover, in the prediction of T2DM, optimization of the prediction model according to the hyper-parameter settings of the KNN learning model was sought, and the performance of the optimized prediction models was compared. This approach successfully predicted the 5-year occurrence of T2DM compared with a traditional prediction model.
Machine learning develops a programmed prediction model using data, algorithms, and computing power. This process requires more computing power as the number of data variables increases. Accordingly, the efficient use of meaningful variables is important. The present study collected 28 features for analysis, including patient information, disease status, test results, and medication information, from a single-center EMR database, which was used to analyze 8454 non-diabetic subjects. In order to generate an efficient prediction model of T2DM, the information gain attribute evaluation method and a 10-fold cross-validation test were performed, and 20 out of the 28 features were selected for model generation. Generally, in the data mining and machine learning field, 10-fold cross-validation is performed to assess the validity of the generated features or models. However, use of 10-fold cross-validation in the field of clinical medical data is very limited.222526 In this study, LR, LDA, and QDA learning models, as well as the KNN learning model (using 1, 10, and 100 neighbors with the Euclidian distance measurement method), were created to verify the validation test according to the learning models, and the cross-validity test was performed from 1 to 30 fold. The cut-off of the section that was most stable was searched. As shown in Fig. 3B, all of the predictive models showed a SD of the 3-fold AUC of less than 0.05 and a SD of the 10-fold AUC of less than 0.01. Our results indicated that the 10-fold cross-validation test is an effective method for verifying clinical data. Previous studies that have reported predictive models of T2DM have been developed in the form of regression formula or risk scores using regression analysis, such as Cox proportional or logistic, with predictive ranges of 0.71 to 0.91 in AUC measurement.1213 Meanwhile, however, these predictive models were evaluated in the same cohort in which they were developed, thus allowing for overfitting.2526 This can be a very important limitation. Thus, if the cross-validation test in the generation of predictive models is applied, it could improve problems with overfitting.
In this study, the LR model was considered as a standard regression analysis method. Thus, a LR model was created to compare the machine learning predictive models, such as LDA, QDA, and KNN model. Along with LR, the LDA, QDA, and KNN algorithms are the most common and proven machine learning algorithms in the computer science field. Since the principles of these algorithms are slightly different, it is worth exploring algorithms that exhibit optimal performance. All predictive models for performance comparisons were finally assessed with the 10-fold cross-validation test, and performance was compared by analysis of AUC. LDA and QDA algorithms are the most commonly used statistical algorithms in the field of machine learning.2324 The KNN algorithm measures the distance of the nearest K neighbors among the given data and clustering of similar groups. This can be seen as a way of assessing risk according to the attributes of a particular group. We considered that this may be effective when the target group is local or a variable whose risk is unknown is used as a predictor in the analysis of clinical medical data. Unlike the LR, LDA, and QDA algorithms, the KNN algorithm needs to be verified for model generation because the performance of the model depends on the setting of hyper-parameters.24 The hyper-parameters of the KNN algorithm are the number of near neighbors and the distance measurement. In clinical medicine, the proper distance measurement of the KNN algorithm is unclear. As shown in Table 2 and Fig. 3, we measured the change in the predictive performance of the model according to the hyper-parameters and were able to select the best performing model. However, these methods must be re-evaluated according to the number of cohort subjects, samples, and variables that will be specific to each study.
In this study, we developed a prediction system using machine learning algorithms, including LR, LDA, QDA, and KNN models with 200 neighbors and a city block or 300 neighbors and the Euclidian. The machine learning predictive models have successfully predicted the 5-year occurrence of T2DM and showed similar prediction performance with a traditional prediction model. As shown in Fig. 4, all of the models developed in this study showed concordant discrimination, with AUCs consistently around 0.77. Our results may have been influenced by the fact that all of the predictive models for T2DM were developed using the same 20 features. This can be an important reason for the consistent performance of all the predictive models. Also, regression analysis has traditionally been a representative method for assessing the causal relationship between features and diseases in medical science. The development of predictive models using typical medical features and LR algorithms (one regression analysis) may have shown the best performance of the LR algorithm model.
In our study, the source data of the predictive model were readily obtained from an EMR database. We suspect that prediction models could be programmed into EMR databases, facilitating race or locality-optimized diagnosis or prediction models of a disease. Furthermore, when patient information is updated and unknown parameters are discovered and applied, the performance of these models may be improved. Further, this may help reduce the development costs of prediction models. With this expectation, many researchers are working on applying machine learning or deep learning to medicine. However, at the moment, the performance improvements with machine learning do not yet expand beyond the abilities of humans. In our study, the maximum performance among all of the developed models showed an AUC of 0.78, which was not significantly different from that of a previous study. Similarly, Gulshan, et al.28 verified the deep learning algorithm for detection of diabetic retinopathy in retinal fundus photographs. In the evaluation of retinal fundus photographs of diabetic patients, the deep running algorithm showed high sensitivity and specificity for detecting diabetic retinopathy; however, there was no statistical difference with current ophthalmologic assessment. As such, while machine learning methods using computer power, mathematical algorithms, and EMR data can provide convenience in model development and use, it seems that this does not yet show the performance level to replace humans. Further research is needed to determine the feasibility of applying machine learning in a clinical setting and to determine whether machine learning can lead to improved outcomes in comparison to clinical assessments.
In this study, there were several limitations. First, the source data of this study included subjects with cardiovascular risks, so the results of this study cannot be generalized to everyone. Thus, in further study, it is necessary to collect cases and improve performance based on the model from this study. Second, ICD codes were used to diagnose disease. The use of ICD codes indicates the presence or absence of disease, but does not reflect the progression of the disease. To overcome these drawbacks, the results of blood tests and medication information were used for analysis, although this may not be enough. Third, the study used an EMR database, and missing information from the EMR was not reflected. This can influence the outcomes of the study. Fourth, unlike previous traditional studies, our study applied 10-fold validation in the development of the models. However, throughout the study, model development and validation was conducted with only one database. Thus, it is necessary to collect additional cases and verify the model derived in this study using other data sources. Finally, the LR model was considered as a standard regression analysis method in this study. Nevertheless, the LR model is derived from machine learning and may show the different performance than regression formulas and risk scores based on regression analysis.
 XML Download
XML Download