

 PDF
PDF ePub
ePub Citation
Citation Print
Print



INTRODUCTION
The incidence of breast cancer has been rapidly increasing in Asian countries over the past two decades (1). Breast cancer in Asian countries has different characteristics compared with in developed Western countries. First, the incidence of breast cancer remains lower than in Western countries (1). Second, the age-specific incidence of female breast cancer in Asia peaks at age 40–50 years, whereas in Western countries the peak occurs at age 60–70 years (2). Third, mammography accuracy is reduced in high-density breast tissue, and Asian women characteristically have higher-density breasts (3).
The American College of Radiology (ACR) announced desirable goals for screening mammography outcomes (4). The performance recommendations of the ACR include recall rates of 5–12%, a cancer detection rate (CDR) of more than 2.5 per 1000 examinations, sensitivity greater than 75%, specificity of 88–96%, and a positive predictive value (PPV, abnormal interpretation) of 3–8%.
The Republic of Korea adopted the National Cancer Screening Program (NCSP) based on the results of randomized controlled trials conducted in developed countries since 1999. However, the diagnostic accuracy of the NCSP was suboptimal (5). Mammography interpretation is highly challenging and is not completely objective. Variability among radiologists in mammography interpretation is extensive, and radiologist characteristics affect screening accuracy (6789101112). Fellowship training in breast imaging improved the sensitivity and the overall accuracy (11). Greater interpretive volume improved the sensitivity, but decreased specificity (12).
The Alliance for Breast Cancer Screening in Korea began the Mammography and Ultrasonography Study for Breast Cancer Screening Effectiveness (MUST-BE) trial in 2016, which compared the diagnostic performance and the cost effectiveness of combined mammography and ultrasonography screenings versus conventional digital mammography screening alone for women of 40–59 years of age. In order for this trial to be successful and to achieve reliable results, quality management should be preceded by periodic monitoring of the diagnostic performances of the participating radiologists.
Our study had two purposes: to evaluate the interpretive performance and inter-radiologist agreement among radiologists who participated in the trial, and to investigate whether these performance and agreement levels differed according to radiologist characteristics.
Go to : 
MATERIALS AND METHODS
Study Subjects
This study was approved by the Institutional Review Boards of three institutions (approval number SCHBC 2017-10-002-002, CMC 2017-6203-0001, DKUH 2017-11-011).
The test sets consisted of 12 cancer cases and 988 non-recall cases. The cases were selected from women aged 40–69 years who received screening between 2010 and 2011 at one of three institutions in Seoul, Bucheon, and Cheonan. Three radiologists with 10, 13, and 15 years of experience interpreting mammography, but who did not otherwise participate in this study, each collected 340 non-recall cases and 10 cancer cases. One of the three reviewed all of the images and finally selected 1000 cases, including 12 cancer cases. The cancer cases were all detected upon screening and mammographically occult cancers were excluded (Table 1). Non-recall cases were included when mammography and follow-up images greater than 12 months showed negative or benign findings (range, 12–29 months; median, 18.5 months). In these cases, cancer was not found with either mammography or ultrasonography during follow-up. Mammographically dense breasts constituted 57.3% of the 1000 cases, which was similar to the 54.8% of the Korean population who present with this characteristic (13).
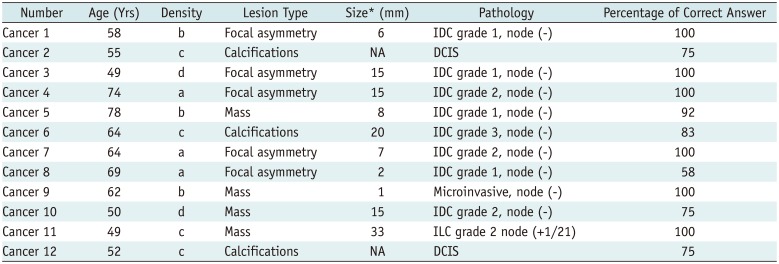
Table 1
Characteristics of Screen-Detected Cancers
![]()
Two views (mediolateral-oblique and craniocaudal) of full-field digital images were provided to radiologists as Digital Imaging and Communications in Medicine files.
Radiologist Characteristics
Radiologist characteristics were obtained from self-administered questionnaires. Questionnaires included the following data: years of experience interpreting mammography, fellowship training in breast imaging of more than one year, annual volumes, and percentage of examinations that were screening mammograms.
Data Review Process
Twelve radiologists independently interpreted all of the test set mammograms and did not review the follow up mammograms. These radiologists were blinded to the original mammographic interpretations and cancer status. Readers rated the mammograms using two scales: the four-point NCSP scale and the seven-point malignant scale. The NCSP scale was modified using the ACR Breast Imaging Reporting and Data System (BI-RADS) categories: 1, negative (BI-RADS category 1); 2, benign (category 2); 3, incomplete, additional evaluation needed (categories 3 and 0); 4, breast cancer doubt (categories 4 and 5).
A seven-point malignant scale was used to obtain suitable receiver-operating-characteristic (ROCs) curves for analysis (14): 1, definitely not malignant; 2, almost definitely not malignant; 3, probably not malignant; 4, possibly malignant; 5, probably malignant; 6, almost definitely malignant; 7, definitely malignant. We collapsed these assessments into two categories for recall (yes or no): recall, NCSP scale 3–4 and malignant scale 4–7; no recall, NCSP scale 1–2 and malignant scale 1–3. The percentage of correct answers was expressed as the percentage of radiologists who recalled the cancer cases.
To evaluate intra-radiologist agreement, 150 mammograms were interpreted a second time by the participating radiologists. The 150 cases were selected using random numbers out of non-recall cases (n = 988). There was an interval of three months between the readings.
Statistical Analysis
We calculated performance indicators as a function of each radiologist's performance and characteristics. Performance indicators included the recall rate, CDR, PPV, sensitivity, specificity, and false positive rate (FPR). The recall rate was calculated as the percentage of women screened who were recalled for further evaluation. The CDR was calculated as the number of breast cancer cases detected per 1000 examinations. The overall mammography accuracy according to radiologist characteristics was assessed using a ROC curve that plotted the true positive rate against the FPR. The significance of the differences among individual characteristics was estimated using the Wilcoxon rank sum test.
We measured intra- and inter-radiologist agreement using percent agreement and the kappa statistic. Percent agreement was a “row measure” that provided the percentage of interpretations for which both radiologists agreed. Cohen's kappa and its 95% confidence interval (CI) were calculated to measure intra- and inter-radiologist variability for both assessments. Because both variables used an ordinal scale, we also used the weighted kappa statistic. The method used to estimate an overall kappa in the case of multiple radiologists and multiple categories was based on the work of Hayes and Krippendorff (15): Hayes' interpretation of Krippendorff's alpha, which is equivalent to an overall weighted kappa, was used as a measure of the overall agreement among the twelve radiologists. Kappa values were interpreted as follows: poor agreement, kappa less than 0.0; slight agreement, 0.0–0.2; fair agreement, 0.2–0.4; moderate agreement, 0.4–0.6; substantial agreement, 0.6–0.8; almost perfect agreement, 0.8–1.0 (16). All statistical analyses were conducted using SAS software, version 9.2 (SAS Institute Inc., Cary, NC, USA) and p values of less than 0.05 were considered statistically significant.
Go to :
RESULTS
Pathologic and mammographic characteristics of cancer cases are summarized in Table 1. Cancers were ductal carcinoma in situ (n = 2), microinvasive cancer (n = 1), and invasive cancers (n = 9). Mammographic abnormalities were focal asymmetry (n = 5), mass (n = 4), and calcifications (n = 3). The percentage of correct answers was 75–100% for mass and calcifications and 58–100% for focal asymmetry.
The radiologist characteristics are summarized in Table 2. Most radiologists had less than 10 years of experience interpreting mammography (mean, 9.22; range, 3–16 years) (58.3%), reported no fellowship training in breast imaging (58.3%), had a mean annual diagnostic mammography volume of < 3000 (75%), had a mean annual screening mammography volume of < 3000 (58.3%), and a mammography screening percentage of ≥ 50% (58.3%).
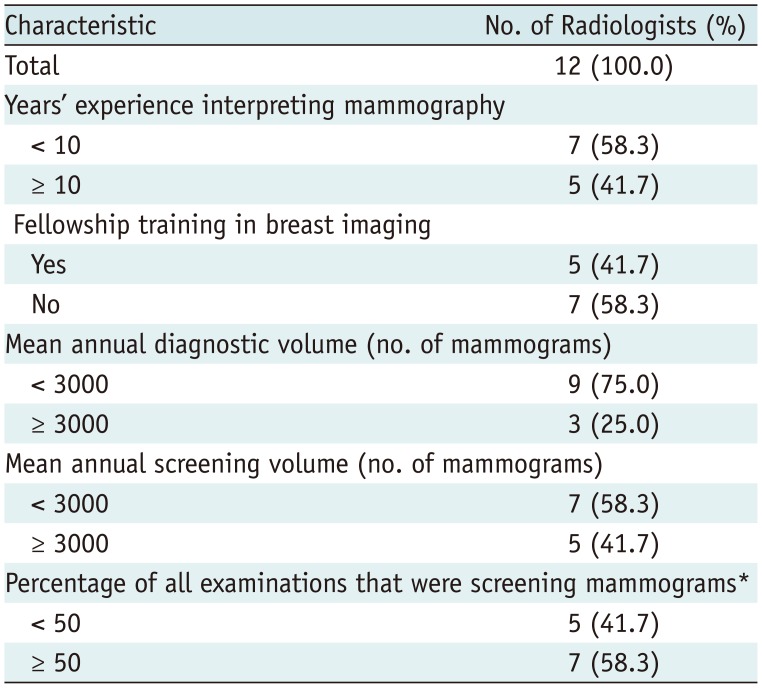
Table 2
Characteristics of Radiologists Participating in Study
![]()
Interpretive Performance
The mean and range of performance indicators were as follows: recall rate, 7.5% and 3.3–10.2%; number of cancer detections, 10.6 and 8.0–12.0 per 1000 examinations; PPV, 15.9% and 8.8–33.3%; sensitivity, 88.2% and 66.7–100%; specificity, 93.5% and 90.6–97.8%; FPR, 6.5% and 2.2–9.4%; area under the curve, 0.93 and 0.82–0.99, respectively (Table 3, Fig. 1). Radiologists interpreting more than 3000 screening mammograms annually tended to have higher CDRs and sensitivities than those interpreting less than 3000 mammograms; however, there was no statistical significance (p = 0.064). Years of experience, fellowship training in breast imaging, volume of diagnostic mammograms and percentage of screening mammograms did not affect interpretive performance.
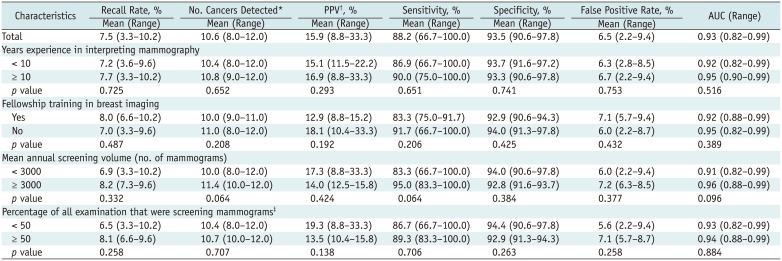
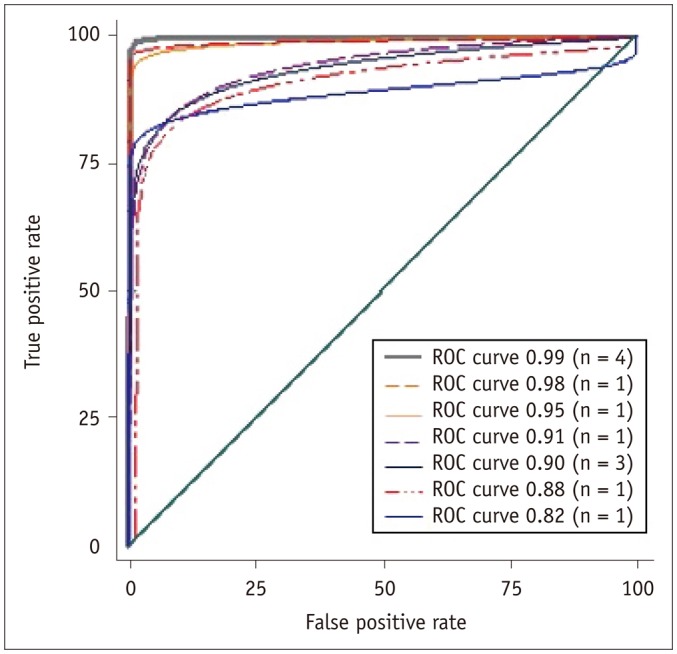 | Fig. 1Areas under curve of twelve radiologists ranged from 0.82 to 0.99 with mean value of 0.93.ROC = receiver-operating-characteristic
|
Table 3
Interpretive Performances and Radiologist Characteristics
![]()
Observer Variability
All twelve radiologists completed the first assessment of 1000 cases and the repeat assessment of 150 cases. Table 4 shows intra- and inter-radiologist agreement.
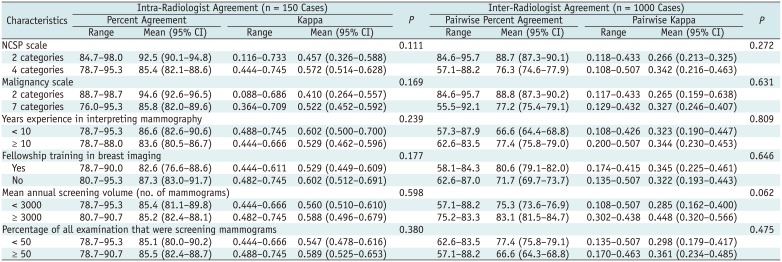
Table 4
Intra- and Inter-Radiologist Agreement and Radiologist Characteristics
![]()
All radiologists had more than 76% intra-individual agreement, ranging from 85.4% (95% CI, 82.1–88.6%) to 94.6% (95% CI, 92.6–96.5%); kappa values of 0.410 (95% CI, 0.264–0.557) to 0.572 (95% CI, 0.514–0.628) indicated moderate agreement. There was no difference in the intra-radiologist agreement according to the radiologist characteristics.
The inter-radiologist agreement for twelve radiologists was as follows. Pairwise percent agreements ranged from 77.2% (95% CI, 75.4–79.1%) to 88.8% (95% CI, 87.3–90.2%); pairwise kappa values were fair: from 0.27 (95% CI, 0.15–0.63) to 0.34 (95% CI, 0.21–0.46). There was no difference in observer variability according to radiologist characteristics.
Go to :
DISCUSSION
In the present study, radiologists who participated in the MUST-BE trial exhibited good interpretive performance for digital screening mammography, and surpassed most performance recommendations of the ACR (4) and performance measures of the Breast Cancer Surveillance Consortium (BCSC) for screening digital mammography examinations (17). The BCSC assessed the trends in screening mammography performance in the United States and published screening mammography performance benchmarks (17). The mean recall rate of the present study was lower than that of the BCSC (7.5% vs. 11.6%, respectively). In addition, the mean PPV and specificity of the present study were higher than those of the BCSC (15.9% vs. 4.4% and 93.5% vs. 88.9%, respectively), and the mean sensitivities were similar (88.2% vs. 86.9%). The results of the present study are evidences of quality control of the MUST-BE trial, which was to investigate the diagnostic performance and the cost effectiveness of combined mammography and ultrasonography screenings in comparison with those of conventional digital mammography screening for women in their forties and fifties.
There were several reports that characteristics of radiologists affected the diagnostic performance of mammographic screening (6789101112), but this study did not show any significant difference. The mean annual screening volume 3000 or more alone showed a tendency to increase the CDR and sensitivity. This result supports the previous results that an increased volume of screening mammography improved the CDR (18). These results agreed with the basic rationale that radiologists who participate in funded screening programs must comply with the national accreditation standards and requirements. The annual minimum number of mammograms that radiologists read is 480 in the United States, 5000 in the United Kingdom and Germany, and 2000 in Canada (1819). The Korean National Cancer Screening quality guidelines recommend that radiologists read an annual minimum number of 1000 mammograms (20), but it is necessary to systematically monitor the quantity of screening volume and diagnostic performance of radiologists to manage quality of breast cancer screening, as in Western Europe.
There was a study that reported that the volume of diagnostic mammography was associated with improved sensitivity and decreased FPR (21), but there were no differences between the diagnostic volume and performance of radiologists in the present study.
We expected that radiologists who completed fellowship training in breast imaging would have a better diagnostic performance, as with the previous result (11), but the present study did not show a significant effect. This may be due to more intensive fellowship training of diagnosis for symptomatic patients and preoperative evaluation for breast cancer patients than breast cancer screening. A curriculum that gives a greater weight to the education of breast cancer screening is needed.
Variability in radiologist performance due to differences in both lesion detection and interpretation has been observed (22). Several studies reported considerable variability in the assignment of BI-RADS categories (678910), resulting in a wide range of recall and FPRs. Such false positives can cause increased anxiety and breast cancer-specific worry, as well as financial loss to patients (23). The present study showed a fair degree of agreement among the twelve radiologists; however, the recall rate was within the acceptable range of the ACR recommendations (4). The FPR was similar to previous results that reported the range of FPRs as 3.5–7.9% after adjusting for patient, radiologist, and testing factors (222425). Proper training and continued practice might improve variability and performance.
There are some limitations to this study. First, the mammography test sets were composed of non-recall cases (true negativity) and recall cases (true positivity). False positive and false negative cases were not included and the test sets may not have adequately represented actual clinical practices in community-based screening settings. In addition, the test sets included more cancer cases compared to the incidence of breast cancer in the real world. So, it is questionable as to whether the diagnostic performance measured using the test sets would reflect the diagnostic performance in actual clinical practice. As such, the comparison of the results between them is limited. Second, breast cancer epidemics show different characteristics in Western and Asian countries and, therefore, the populations' desirable performance goals are different. Although we compared our results to published Western data, this was not the most appropriate comparison. Performance goals appropriate for Korean women need to be developed. Third, 150 non-recall cases were selected to evaluate the intra-radiology agreement. Cancer cases were excluded, resulting in selection bias. Nevertheless, this is the first study that used test sets to evaluate digital mammography performance in breast cancer screening in Korea.
In conclusion, the interpretative performances of radiologists participating in the MUST-BE trial fulfilled the ACR goal of screening mammography, although inter-observer variability persisted. Sufficient volume of screening mammography and specialized training for radiologists are needed to perform the national breast cancer screening successfully.
Go to :
 XML Download
XML Download