

 PDF
PDF Citation
Citation Print
Print



INTRODUCTION
Artificial intelligence (AI) is projected to substantially influence clinical practice in the foreseeable future, especially in areas of diagnosis, risk assessment and prognostication through predictive algorithms. Notably, promising results have recently been reported regarding the application of convolutional neural networks,123 a deep learning technology used for analyzing images. In medicine, convolutional neural networks have been utilized in the diagnostic analysis of a variety of medical images such as those of the retinal fundus,45 histopathology,6 endoscopy,7 and the full range of radiologic891011 images. However, despite the excitement around the technologies, it is yet rare to see examples of robust clinical validation of these clinical applications and, as a result, very few are currently in clinical use.121314 Despite the potential of AI technologies, it cannot be denied that the application of AI in health care is overhyped and is at risk of commercial exploitation to a certain extent.13 The ultimate purpose of introducing AI into medicine is to achieve better, safer care for our patients. A thorough, systematic validation of AI technologies using adequately designed clinical research studies before their integration into clinical practice is critical to ensure patient benefit and safety while avoiding any inadvertent harms. The importance of proper clinical validation of AI technologies used for medicine has recently been underscored by multiple premier peer-reviewed medical journals13141516 and a comprehensive methodologic guide for the clinical validation17 has also recently been published. Peer-reviewed medical journals play a crucial role in the pathway towards the clinical validation of AI technologies used for medicine as the peer-reviewed medical journals employ a fundamental mechanism that vets the scientific and clinical value, validity, and integrity of research studies. The importance of peer-reviewed medical journals as more authoritative and reliable sources for updates regarding clinical validation of AI technologies is further highlighted these days since many related research studies are also published without peer review, in repositories such as https://arxiv.org, a repository of electronic preprints, which is moderated but not peer-reviewed, and does rely on peer to peer expertise in clinical evaluation of these technologies, thereby potentially adding to the existing hype around AI.18
With these issues in mind, we would like to suggest several specific points regarding the role that peer-reviewed medical journals can play to help achieve proper and meaningful clinical validation of AI technologies designed for use in medicine, especially diagnostic and predictive software tools developed with deep learning technology and high-dimensional data. AI can be applied to medicine in various ways. Of those, in this article, we will consider AI technologies designed to make medical diagnosis and prediction, i.e., classification tasks (for example, a distinction between cancer and benign disease or between good and poor responders to a therapy), built with “big” clinical datasets, as such technologies underpin the data-driven precision medicine in the AI era. Appraisal of AI technologies for medical diagnosis and prediction can be performed at different levels of efficacy19 such as diagnostic accuracy efficacy (for example, a study by Ting et al.5), patient outcome efficacy (for example, a study by the INFANT Collaborative Group20), and societal efficacy that considers cost-benefit and cost-effectiveness. This article will focus on the evaluation of diagnostic accuracy efficacy. Although this article deals with some fundamental methodologic principles, the purpose of this article is not to provide comprehensive explanations on related methodology. Further methodologic details can be found in a recent methodologic guide.17 Also, for an exemplary paper which successfully addressed the points to be discussed in this article, a study by Ting et al.5 could be referred.
POINTS FOR PEER-REVIEWED MEDICAL JOURNALS TO EMPHASIZE TO HELP ACHIEVE PROPER CLINICAL VALIDATION OF AI
First, clarification of the meaning of the word validation as used in AI and machine learning (ML) articles would be helpful since, unlike the commonly accepted definition of the term validation in medicine/health literature,21 this term is also used in AI/ML literature as technical jargon with a somewhat different meaning. According to the convention in the field of AI/ML, validation as the technical jargon also refers to a particular step in the sequence of training, validation, and test steps for algorithm development (Fig. 1), where the validation step is to fine-tune the algorithm after training (see studies by Lakhani and Sundaram8 and Larson et al.9 for example).1722 Journals should try to avoid confusion with the use of the term, for example, by referring to the fine-tuning step and clinical validation as “internal validation” and “external validation,” respectively, or explicitly naming them “fine-tuning step” and “clinical validation,” respectively.
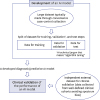 | Fig. 1Typical processes for development and clinical validation of an artificial intelligence model such as a deep learning algorithm for medical diagnosis and prediction.The dataset used to develop a deep learning algorithm is typically convenience case-control data, which is prone to spectrum bias.17 The algorithm development goes through training, validation, and test steps, for which the entire dataset is then split, for example, 50% for the training step and 25% each for the validation and test steps.22 The term validation here is a technical jargon that means tuning of the algorithm under development, unlike the commonly accepted definition in medicine/health literature as in clinical validation. The test step, if performed using the typical split-sample “internal” validation method, should be distinguished from the true external validation as the former falls short of validating the clinical performance or generalizability of the developed algorithm. The use of a dataset that is collected in a manner that minimizes spectrum bias in newly recruited patients or at different sites than the dataset used for algorithm development, which effectively represents the target patients in a real-world clinical practice, is essential for external validation of the clinical performance of an AI algorithm.
AI = artificial intelligence.
|
Second, the use of adequately sized datasets that are collected in newly recruited patients or at different sites than the dataset used for algorithm development and training which effectively represent the target patients undergoing a given diagnostic/predictive procedure in a “real-world” clinical practice setting are essential for “external” validation of the clinical performance of AI systems (for example, a study by Ting et al.5) to achieve an unbiased assessment (Fig. 1). The importance of using proper external datasets in validating the performance of AI systems built with deep learning cannot be overstated because mechanistic interrogations of the results created by a deep learning network are difficult due to the “black-box” nature of the technology, i.e., one cannot simply look inside a deep neural network to understand how it works to give a particular output due to the complex web of multiple interconnected layers and innumerable individual weights calculated with back-propagation for myriad artificial neuronal connections.1131516 In addition, split-sample “internal” validation, i.e., validation of the performance using a fraction of data that is randomly split from the entire dataset and is kept unused for algorithm training (for example, studies by Ehteshami Bejnordi et al.6, Lakhani and Sundaram8, and Yasaka et al.10) should be distinguished from the true external validation mentioned above (Fig. 1). In contrast with the true external validation, split-sample validation, which has on occasion been termed as external validation in published papers, is statistically inadequate to account for overfitting and cannot generally avoid spectrum bias.17 Therefore, although split-sample validation may demonstrate the internal technical validity of an AI algorithm, it falls short of validating its clinical performance or generalizability.17 More in-depth explanations can be found elsewhere.17 Overfitting and spectrum bias are significant pitfalls that can substantially exaggerate the performance of an AI system.161723 Overfitting refers to a situation in which a learning algorithm customizes itself too much to the training data, including idiosyncratic spurious statistical associations, to the extent that it negatively impacts the algorithm's ability to generalize to new data while exaggerating its performance on the training dataset.117 It can be particularly problematic in overparameterized classification models built with high-dimensional data.2425 An overparameterized model is a mathematical model that contains too many “x” parameters (called high-dimensional) relative to the number of data to feed the model for training.2425 An example is an AI algorithm using convolutional neural network to analyze medical images as each pixel of an image is considered a separate x parameter in the mathematical model. Spectrum bias indicates a situation in which the spectrum of patient manifestations (e.g., severity, stage, or duration of the disease; presence and severity of comorbidities; demographic characteristics, etc.) in the data used for algorithm training does not adequately reflect the spectrum in those to whom the algorithm will be applied in clinical practice. This can be another source of data overfitting. Use of proper external datasets as explained earlier is crucial to avoid these pitfalls, for which prospectively collected data are better than those obtained in retrospective cohorts.
Third, use of large datasets obtained from multiple institutions for validation of the clinical performance of an AI system should be encouraged. Performance of an AI system may vary according to the selection of validation datasets due to differences in the degree of overfitting and patient manifestation spectrum between the datasets. Some types of data such as radiologic images may also be subject to additional sources of variability as different scanners/vendors and scan parameters/techniques may also influence the performance of AI systems.1626 Therefore, using datasets obtained from multiple institutions would be advantageous in achieving more robust validation of the performance. One good example is a study by Ting et al.5 in which authors used ten multiethnic cohorts obtained from multiple institutions for external validation of the performance of their AI algorithm.
Fourth, prospective registration of studies to validate the performance of AI systems, like registration of clinical trials of interventions (for example, at clinicaltrials.gov), can be proposed to increase transparency in the validation. With varying performance results obtained with different datasets from multiple institutions as previously mentioned, some researchers or sponsors might be inclined to selectively report favorable results, which would create a problem of under-reporting unfavorable results. Such under-reporting was a significant reason why the policy of prospectively registering clinical trials was first introduced in 2005 by the International Committee of Medical Journal Editors (ICMJE). In compliance with the ICMJE policy, numerous medical journals consider reports of trials for publication only if they had been registered in any of the publicly accessible trial registries accepted by the ICMJE before enrollment of the first study participant. Similar requirements have also been implemented by regulatory governmental organizations and funders. Likewise, prospective registration of diagnostic test accuracy studies, which include studies to validate the performance of AI systems, has already been proposed.27 Adoption of this policy by medical journals as well as by governmental agencies and funders will enhance transparency in the validation of the performance of AI systems.
Fifth, in addition to the points mentioned above to improve the quality and transparency in validating the performance of AI systems, for AI systems developed with supervised learning (i.e., outcome statuses for an algorithm to predict are provided as labeled data for algorithm training) using data labeled by human interpreters, it would be important to advise the investigators to clarify the experience and training of the individuals doing the labeling and the variability between those doing the labeling. The ultimate performance of an AI system is profoundly influenced by the quality of the data used for training the system, and the quality of labeling is an important factor for evaluating the performance of an AI system.
Lastly, encouraging authors to refer to Standards for Reporting Diagnostic Accuracy (STARD)28 and Transparent Reporting of a multivariable prediction model for Individual Prognosis Or Diagnosis (TRIPOD),21 the Enhancing the QUAlity and Transparency Of health Research (EQUATOR) Network guidelines for reporting diagnostic accuracy studies and multivariable prediction model for individual prognosis or diagnosis, respectively, would be helpful for improving the completeness and consistency in reporting studies to validate the performance of AI systems although these guidelines are not customized for AI. Guidelines specific to reporting AI/ML predictive models29 are also available albeit not as widely implemented as STARD or TRIPOD and would facilitate better reporting of the research results.
SUMMARY
Peer-reviewed medical journals can encourage investigators who wish to validate the performance of AI systems for medical diagnosis and prediction to pay closer attention to the factors listed in this article by emphasizing their importance. Thereby, peer-reviewed medical journals can promote execution and reporting of more robust clinical validation of AI systems and can ultimately facilitate translating the technological innovations into real-world practice while securing patient safety and benefit.
 XML Download
XML Download