

 PDF
PDF ePub
ePub Citation
Citation Print
Print



I. Introduction
The innovations in areas such as health information technology (HIT) [1] have the potential of improving people's health and leading to better quality in modern health systems. Moreover, human knowledge becomes a powerful strategic tool for a health organization [2]. Having this knowledge depends on the ability of individuals performing certain tasks. Because ontologies [3] constitute the standard knowledge representation mechanism for the semantic web and other information retrieval systems, it becomes necessary to develop ontologies that are capable of depicting health information. A well-accepted definition in the area of artificial intelligence (AI) is that of Studer et al. [4], who said: “an ontology is a formal and explicit specification of a shared conceptualization.”
The use of ontologies is becoming increasingly important in natural language processing (NLP) [56]. NLP is the discipline that deals with the automatic treatment of natural language [7]. It is a branch of AI and computational linguistics that is dedicated to understanding human language to exploit the linguistic knowledge of texts [8].
II. Case Description
This work developed a software architecture that enables, from a text written in natural language, the extraction of the necessary elements using NLP tools to then automatically create an instance of an ontology and to extract medical knowledge from the patient records of Panamanians. The software architecture was tested and validated by experts using precision, recall and F-measure metrics, obtaining excellent results.
1. Proposed Methodology
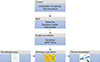
We developed a software architecture that enables the extraction of information from a clinical text written in natural language, which represents the corpus of the patient clinical records, followed by the extraction of the named entities and relevant knowledge elements, and finally, the generation and the instantiation of an ontology of the domain. It has four stages: (1) NLP, (2) extraction of annotations, (3) population of the ontology, and (4) showing the clinical knowledge. The proposed architecture complies with semantic interoperability standards because it extracts patient information using the HL7 electronic clinical records standard. Figure 1 shows the phases of this architecture.
2. Corpus
The corpus consists of clinical data of about 200 patients, whose medical notes were obtained from the primary care clinic of the Technological University of Panama and a public hospital, both in Panama City. They contain general data, clinical diagnoses, medications, history of laboratory services and clinical aspects described in Spanish by physicians. In addition, the software architecture was evaluated by experts using precision metrics, recovery and F-measure, which are typical of information retrieval systems [910].
3. Natural Language Processing
In this step, the objective was to perform a linguistical analysis of the text. This is done by dividing the text into sentences and words. The standard word segmentation task was completed with the application of a programming interface provided in the development framework for the NLP called GATE (General Architecture for Text Engineering) [1112].
4. Extraction of Annotations
For the extraction of information for labeling annotations, two GATE components called the Java Annotation Pattern Engine (JAPE) Transducer [13] and Gazetteer [14] were used. These components are responsible for compiling and executing a set of rules based on the JAPE grammar. A set of 65 semantic rules were constructed and coded in the JAPE grammar to extract the necessary annotations in this architecture. Figure 2 shows an extraction rule written in JAPE.
5. Ontology Population
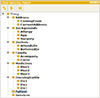
In this phase, the instances that populate the ontology will be inserted. In the defined architecture, the annotations recovered in the previous phase are used to carry out the process of instantiating the ontology. In Figure 3, with the Protégé [15] editor, the class hierarchy of the created domain ontology is shown.
6. Extracting Clinical Knowledge
The result of the architecture expressed in clinical knowledge was, first, a file in OWL format [16], that can be read from any ontology editor, either to create software agents or to reuse it, enriching it with more ontological elements. Second, a friendly user interface is used for the health professional. It enables knowledge management through the extraction process that will be used as support for medical decision making. Third, an XML file is generated following the HL7 Clinical Document Architecture (CDA) standard [17] that presents patient information schematically and can be used by other systems which enables interoperability through this standard.
III. Discussion
Most health centers in Panama handle unstructured information. Physicians and nurses write a patient's history in a text document. This makes it difficult for computers to read and understand this information. To solve this problem, a methodology and a software architecture that makes it possible, using NLP techniques to automatically create an ontology from unstructured documents, was proposed in this study.
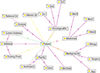
The developed architecture focuses on creating and populating an ontology from a text in natural language and with an appropriate level of efficiency, see Figure 4. In addition to this, the exchange of information through documents in CDA format was implemented. Figure 5 shows a segment of the CDA file in XML format.
The implemented architecture follows the functional requirements and develops the project according to the standards required by the software industry. The technological foundations presented here are those considered necessary to create a software that conveys NLP to ontologies in a clinical context.
It was decided to use free software tools that are available to the research community to perform the analysis, design and implementation of this computer program application so that other researches in the e-health community can modify or improve the original version of this software.
For the validation of the architecture, the project designers used the patients' clinical information domain. The total corpus consisted of the following set of data: general data (2,764 records), diagnosis (505 records), and medicines (590 records). The annotation extraction process was evaluated using the precision, recall and F-measure validation metrics shown in Table 1.
The methodology presented here has been validated in the patient clinical information domain in Spanish with promising results. It was carried out with the validation metrics most used in NLP systems, specifically the precision, recall and F-measure.
At present, there are very few ontological learning systems oriented to the information domain of patients for the construction of ontologies; therefore, research in this field is increasingly important.
To validate this methodology, a set of experiments were conducted. The system obtained satisfactory results for the annotation extraction process. The precision measures obtained for the extraction of annotations, in the corpus of palliative care, and in general medicine using the quality validation methods explained above were 95.56%, 88.56% and 91.93% which indicate a very good accuracy because they all are over 90%.



 XML Download
XML Download