

 PDF
PDF ePub
ePub Citation
Citation Print
Print


Abstract
In addition to identifying genetic differences between target populations, it is also important to determine the impact of genetic differences with regard to the respective target populations. In recent years, there has been an increasing number of cases where this approach is needed, and thus various statistical methods must be considered. In this study, genetic data from populations of Southeast and Southwest Asia were collected, and several statistical approaches were evaluated on the Y-chromosome short tandem repeat data. In order to develop a more accurate and practical classification model, we applied gradient boosting and ensemble techniques. To infer between the Southeast and Southwest Asian populations, the overall performance of the classification models was better than that of the decision trees and regression models used in the past. In conclusion, this study suggests that additional statistical approaches, such as data mining techniques, could provide more useful interpretations for forensic analyses. These trials are expected to be the basis for further studies extending from target regions to the entire continent of Asia as well as the use of additional genes such as mitochondrial genes.
Go to : 
REFERENCES
1.Butler JM. Advanced topics in forensic DNA typing: methodology. San Diego, CA: Academic Press;2011.
2.Enoch MA., Shen PH., Xu K, et al. Using ancestry-informative markers to define populations and detect population stratification. J Psychopharmacol. 2006. 20:(4 Suppl):. 19–26.

3.Li JZ., Absher DM., Tang H, et al. Worldwide human relationships inferred from genome-wide patterns of variation. Science. 2008. 319:1100–4.
4.Rosenberg NA., Pritchard JK., Weber JL, et al. Genetic structure of human populations. Science. 2002. 298:2381–5.
5.Pritchard JK., Stephens M., Donnelly P. Inference of population structure using multilocus genotype data. Genetics. 2000. 155:945–59.
6.Quinlan JR. Induction of decision trees. Mach Learn. 1986. 1:81–106.
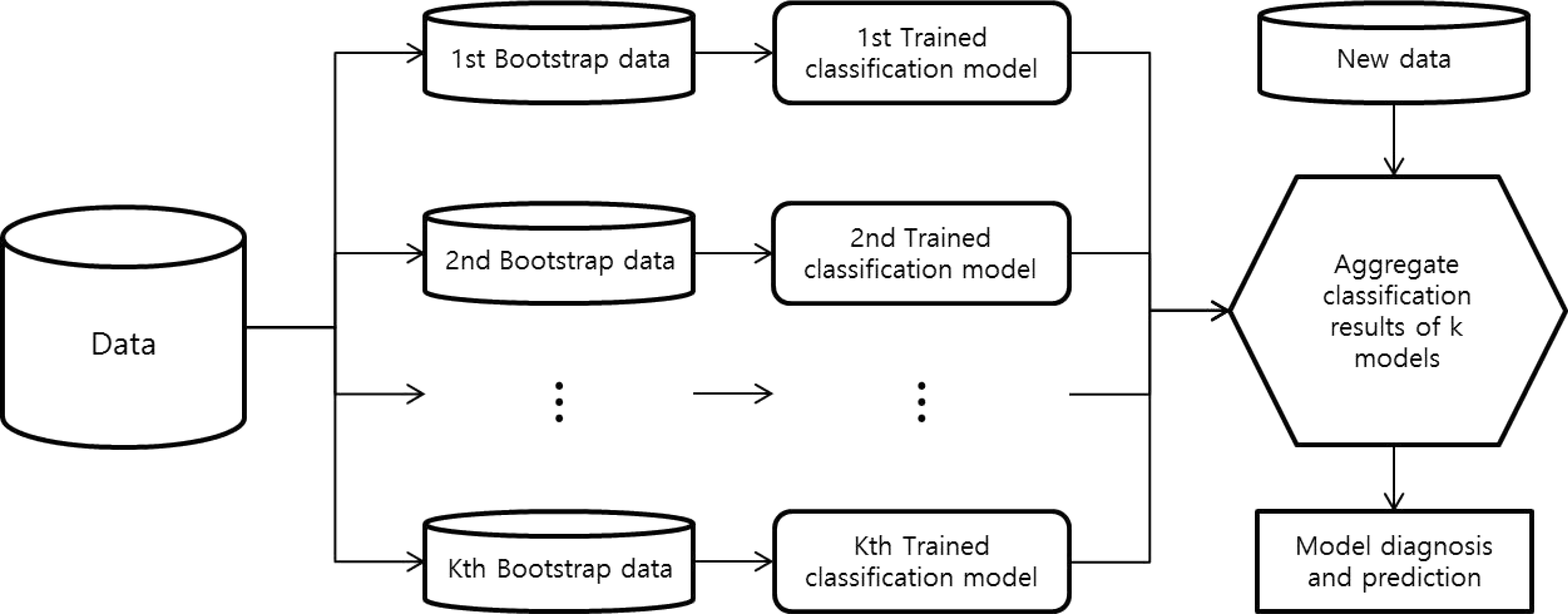
7.Opitz D., Maclin R. Popular ensemble methods: an empirical study. J Artif Intell Res. 1999. 11:169–98.
8.Rokach L. Ensemble-based classifiers. Artif Intell Rev. 2010. 33:1–39.
9.Quinlan JR. Bagging, boosting, and C4.5. AAAI/IAAI '96 Proceedings of the Thirteenth National Conference on Artificial Intelligence. 1996 Aug 4-8; Portland, OR, USA. Vol. 1. Palo Alto, CA: AAAI Press;. 1996. 725–30.
10.Breiman L. Bagging predictors. Mach Learn. 1996. 24:123–40.
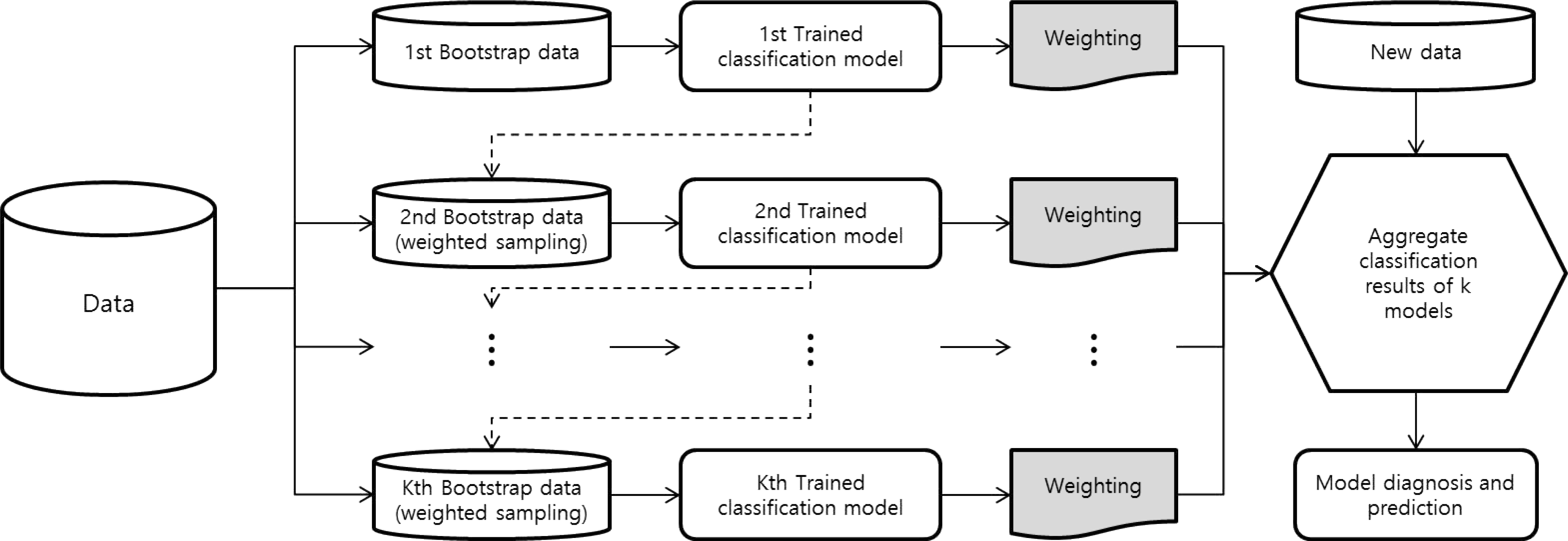
11.Schapire RE. The strength of weak learnability. Mach Learn. 1990. 5:197–227.
12.Freund Y., Schapire RE. A short introduction to boosting. J Jpn Soc Artif Intell. 1999. 14:771–80.
13.Friedman JH. Stochastic gradient boosting. Comput Stat Data Anal. 2002. 38:367–78.
14.Wang R., Lee N., Wei Y. A case study: improve classification of rare events with SAS Enterprise Miner. In: Proceedings of the SAS Global Forum 2015 Conference. Cary, NC: SAS Institute Inc.;2015.
15.Rahman MM., Davis DN. Addressing the class imbalance problem in medical datasets. Int J Mach Learn Comput. 2013. 3:224–8.
16.Purps J., Siegert S., Willuweit S, et al. A global analysis of Y-chromosomal haplotype diversity for 23 STR loci. Forensic Sci Int Genet. 2014. 12:12–23.
Go to :
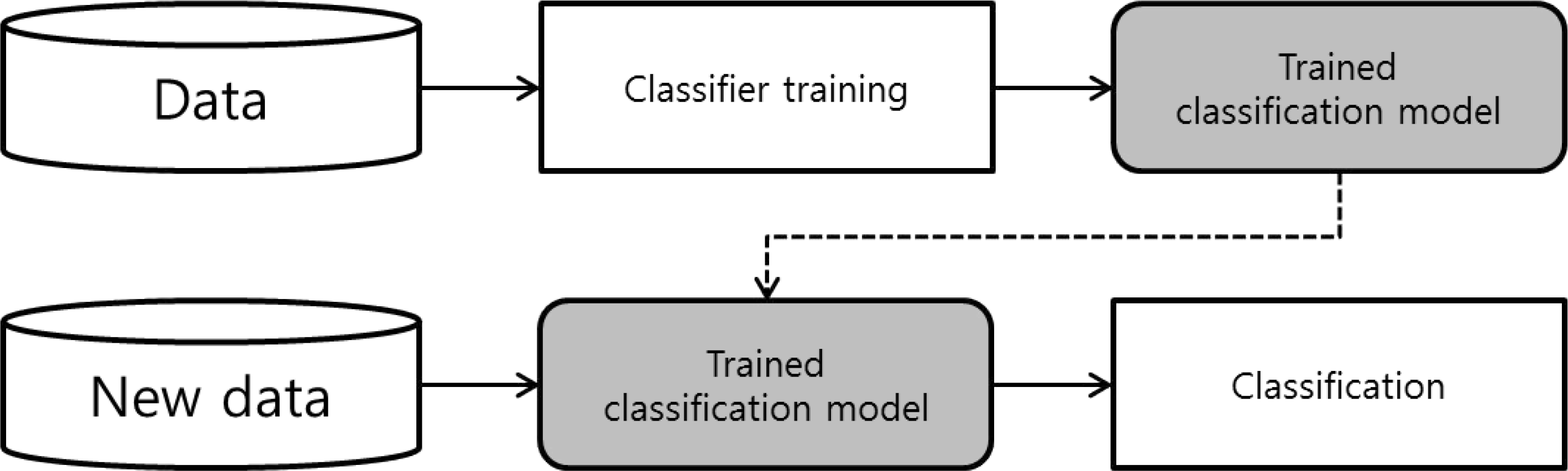
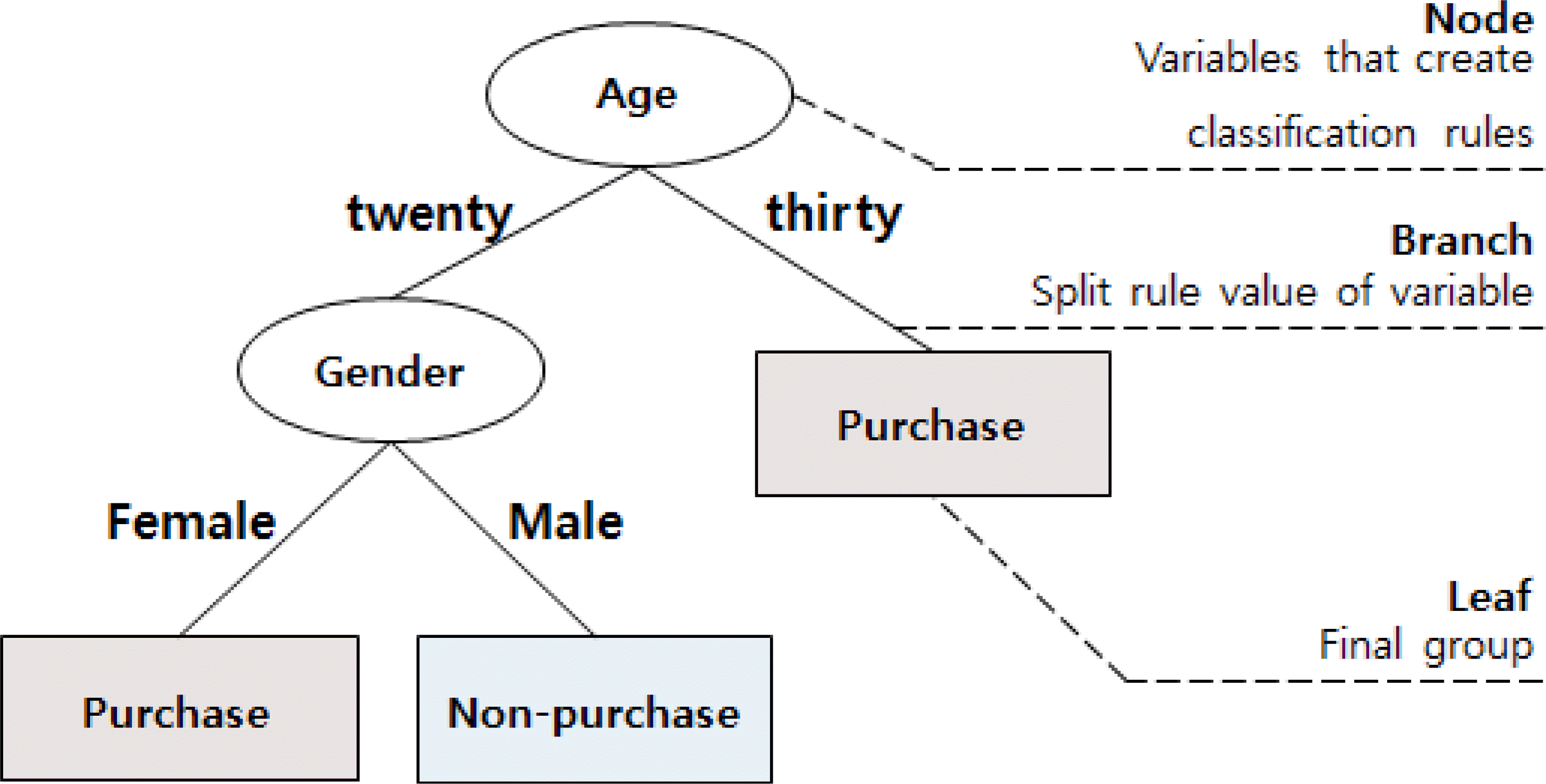
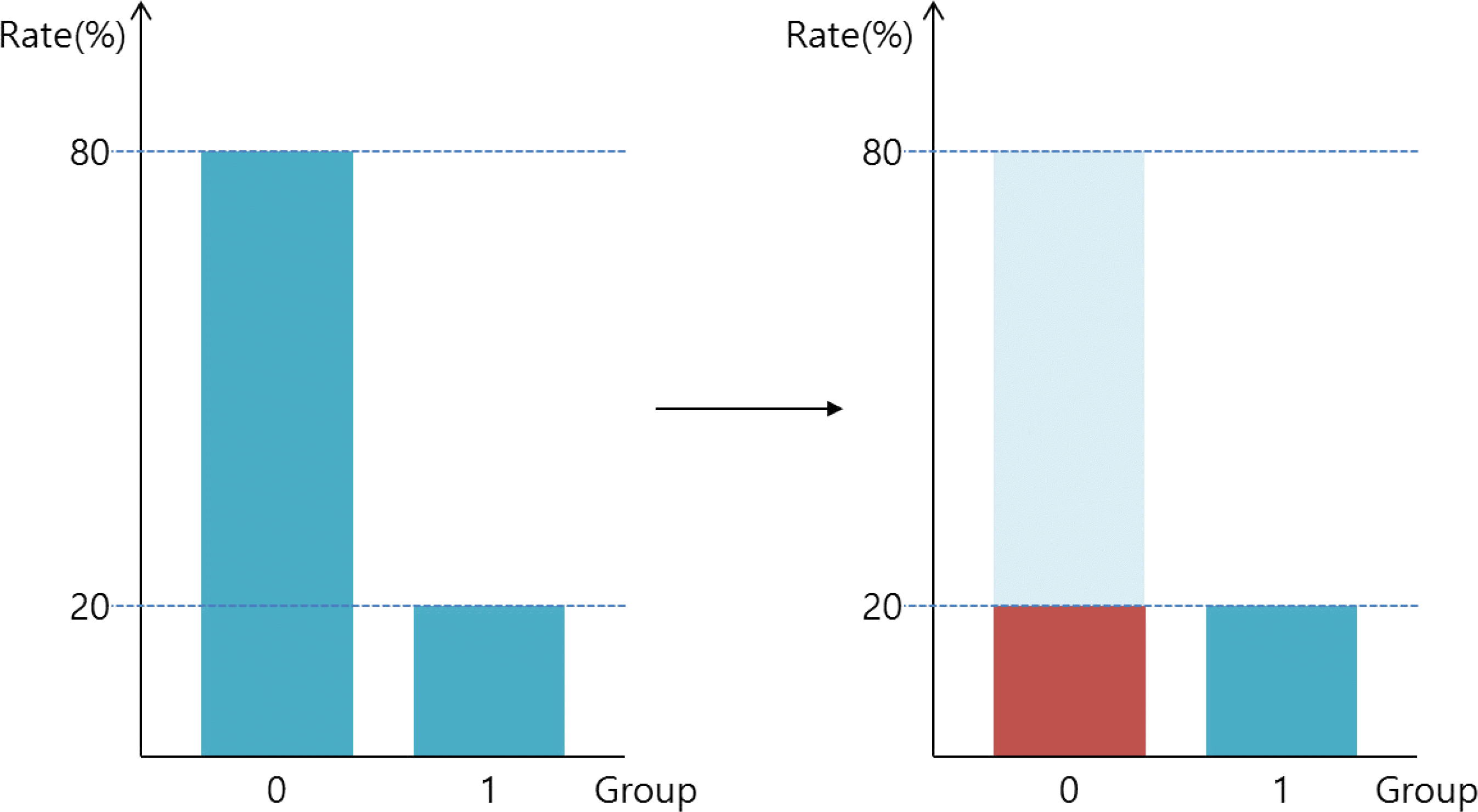
 | Fig. 7.Gradient boosting and decision tree (chi-square) ensemble model separation rule tree. |
Table 1.
Details of populations analyzed
| Population | Sample size | Data source |
|---|---|---|
| Vietnam | 46 | Seoul National University |
| Nepal | 69 | |
| India | 23 | |
| Vietnam | 45 | Purps et al. [16] |
| Philippines | 798 | |
| Singapore | 104 | |
| India | 298 | |
| Total | 1,383 |
Table 2.
Composition of data
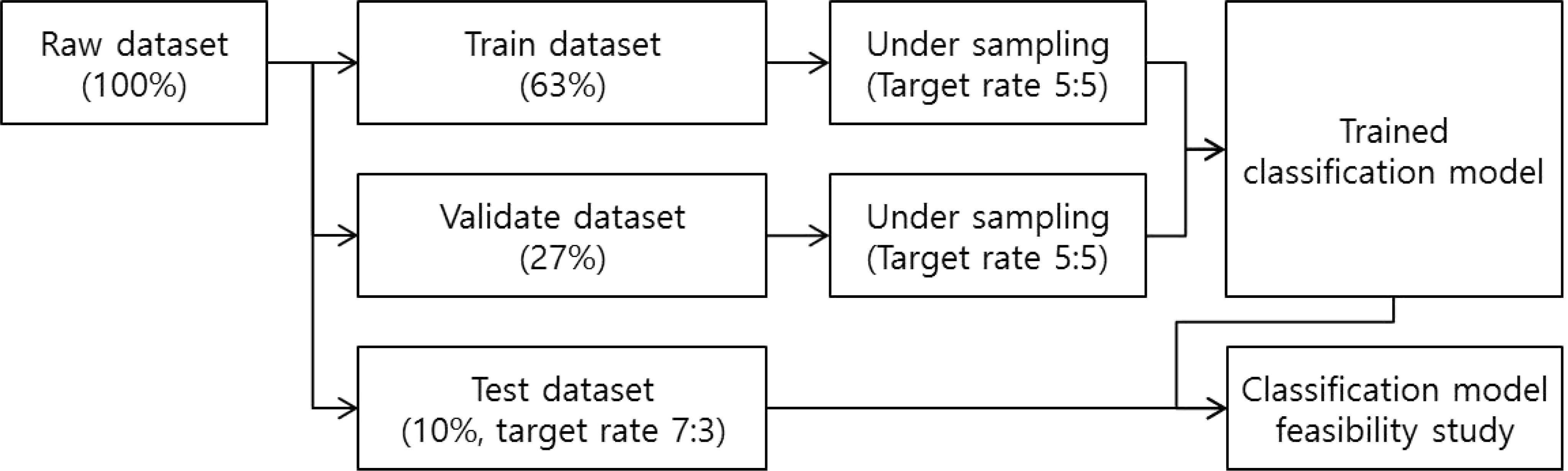
Table 3.
The results of data splitting and under sampling
Table 4.
Result of classification model
 XML Download
XML Download