

 PDF
PDF ePub
ePub Citation
Citation Print
Print


I. Introduction
Cardiovascular diseases include hyperlipidemia, myocardial infarction, and angina pectoris. Cardiovascular disease is diagnosed by electrocardiography, ultrasound, blood tests, angiography, and so on. These methods are time-consuming and costly because they require many different tests. Recently, a cardiovascular disease prediction technique using machine learning has been developed to replace these diagnostic methods [1].
Medical IT combined with machine learning technology has increased the accuracy of disease prediction using predictive models generated from disease-related learning data [2]. However, since complex data is analyzed, a deep learning technique is required [34].
Many studies have been conducted on cardiovascular disease using machine learning. Khatib and Montazer [5] developed a heart disease risk prediction model based on the Dempster-Shafer evidence theory by designing a fuzzy-evidential hybrid inference engine. Krishnaiah et al. [6] developed a cardiovascular risk prediction system using fuzzy K-nearest neighbor (K-NN) classifiers for measured values to remove uncertainty. However, research on a prediction model for domestic cardiovascular disease is lacking [78].
In recent years, attention has focused on how to construct a prediction model based on big data and the development of deep learning technology.
Prediction models are based on artificial intelligence (AI), and many methods using machine learning, data mining, databases, and statistics have been proposed [9]. Prediction models using these cutting-edge techniques have been used in many fields, and their value in the medical industry is gradually increasing.
A deep belief network (DBN) is an advanced learning method using artificial neural networks which involves a high level of technology and performs well [10]. A DBN consists of several layers of controlling restricted Boltzmann machine (RBM). It then performs supervised learning using backpropagation after unsupervised learning [11]. DBN has broad applications in various medical fields and is widely used for medical research because it performs well [121314].
In this paper, we propose a cardiovascular disease prediction model. The sixth Korea National Health and Nutrition Examination Survey (KNHANES-VI) 2013 data set [15] was used to find cardiovascular-related health data. First, statistical analysis was performed to find variables related to cardiovascular disease using health data related to cardiovascular disease. Second, a model of cardiovascular risk prediction by learning based on the DBN was developed. Thus, variables were selected using statistical techniques, and learning with DBN was conducted using the selected variables.
The remainder of this article is structured as follows. Section II describes the dataset and proposes the method. Section III outlines the system implementation and compares its ability to discriminate cardiovascular risk and probability tables. Finally, Section IV presents conclusions and specifies further directions for future research.
II. Methods
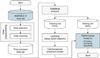
The research structure of this study is presented in Figure 1. First, the dataset was defined and data was preprocessed. Second, the dataset was statistically analyzed. We uses statistical techniques to select variables to be used for learning. The analyzed dataset was divided into a training set (70%) and a testing set (30%) (Table 1). Third, learning was done based on the DBN using the training set. Finally, the performance of the cardiovascular prediction model generated through learning was measured.
1. Dataset
The KNHANES-VI contains data from the Korea Centers for Disease Control and Prevention. KNHANES identifies the health and nutritional status of the population and selects the vulnerable groups that must be prioritized to calculate the statistics necessary to assess whether health policies and projects are being effectively delivered. It also provides statistical data on smoking, drinking, physical activity, and obesity requested by the World Health Organization (WHO) and the Organization for Economic Cooperation and Development (OECD) [15].
The Framingham risk score (FRS) has been used as a standard guideline for predicting cardiovascular risk for 10 years. Therefore, the attributes in these guidelines were used as a reference for data extraction [16].
Input variables for learning included age, gender, total cholesterol, high-density lipoprotein (HDL), systolic blood pressure (SBP), diastolic blood pressure (DBP), smoking, and diabetes. Output variables included cardiovascular diseases: hypertension, hyperlipidemia, myocardial infarction, and angina pectoris.
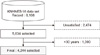
There are 8,108 experimental records in KNHANES-VI. Of these, 2,474 were from uncertain (non-respondent, null value) respondents, while 1,390 were records of people less than 30 years old. The final dataset comprised 4,244 records. Figure 2 shows the data preprocessing procedure.
2. Statistical Analysis
The statistical techniques for feature selection used the nonparametric Mann-Whitney U-test and chi-square. The age, SBP, DBP, total cholesterol, and HDL cholesterol variables were analyzed using the U-test. Chi-square testing was used to analyze the gender, diabetes, and smoking variables. Here, any variable whose p-value was less than or equal to 0.05 was excluded.
IBM SPSS Statistics ver. 22.0 (IBM, Armonk, NY, USA) was used for statistical analysis. Several statistical analysis methods with several preoperative variables were compared to determine the most effective method to predict cardiovascular risk.
A confusion matrix and receiver operating characteristic (ROC) curve were used to compare predictive ability. A confusion matrix is a measure to evaluate the performance of the classifier. As shown in Figure 3, accuracy, sensitivity, and specificity were measured. The matrix was constructed for output variables (low risk, high risk) in the testing dataset for each analysis. The limit of significance for all tests was p < 0.05.
3. Deep Belief Network
A DBN is a deep learning technique that learns by composing multiple RBM layers. MATLAB R2016b was used for the DBN in this research. The DeepLearnToolbox by R. B. Palm was used for the DBN library [17].
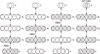
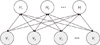
The RBM, which is based on the Hopfield network, employs the energy function and obtains unit values probabilistically (using a Boltzmann distribution). The RBM is shown in Figure 4. The RBM consists of a visible unit layer and a hidden unit layer, and its internal connection intensity is 0 [18]. The DBN, in which structures of the RBM are connected sequentially, is shown in Figure 5 [10].
In the structure, the forefront hidden unit layer acts as the previous visible unit layer. DBN learning is done by configuring the visible layer and hidden layer 1 into a single RBM [19]. Once learning is complete, hidden layers 1 and 2 are trained via the RBM by giving a new input as a value of hidden layer 1. As such, learning is sequential up to the last layer.
A supervised learning-based classification technique using the DBN is the back propagation algorithm, which is configured in the uppermost layer in the DBN [20]. A classification prediction model using the backpropagation-DBN was created for this paper.
III. Results
1. Dataset Characteristics
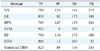
The distribution of preoperative parameters among low- and high-risk records is shown in Table 2. The p-value >0.05 were gender and total cholesterol. In other words, there were six variables related to cardiovascular disease risk.
2. DBN Model
The DBN constructed a learning model using a training set. Six input variables (age, SBP, DBP, HDL, diabetes, smoking) and 1 output data were used. The DBN consisted of two steps. The first phase was the construction of the RBM network using unsupervised learning. The RBM settings were epoch, batch size, and momentum at 200, 12, and 0, respectively. In the second phase, the RBM network learned the backpropagation algorithm of supervised learning. The backpropagation options were epoch and batch size at 200 and 12, respectively.
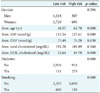
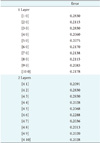
The performance of the model differed depending on the number of nodes constituting the DBN. The error rate according to the number of nodes is shown in Table 3. Six nodes with one layer [4 8] showed the lowest error rate (0.2013). Therefore, it is best for construction of a DBN [4 8] (see Figure 6).
3. Experimental Results
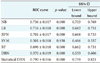
We compared the performance of the proposed DBN with that of various machine learning techniques. The comparison models were naïve Bayesian (NB), logistics regression (LR), back propagation network (BPN), support vector machine (SVM), random forest (RF), DBN (using nine-variable input), and the proposed statistical DBN (using six-variable input) method. The confusion matrix results appear in Table 4. The ROC curve results are shown in Table 5.
Experimental results show that the proposed statistical DBN achieved the highest sensitivity, accuracy, and ROC curve performance. Specificity was 100% for SVM, and that for all others was low. In other words, SVM was effective in measuring low risk, but it could not predict important high risk. Sensitivity to measure high-risk prediction was highest at 87.6% for the proposed statistical DBN. Also, the existing DBN showed low performance because it does not consider unnecessary variables. It can be seen that unnecessary variables have a great influence on the measurement of cardiovascular disease. Therefore, the proposed model is able to achieve higher performance because it considers important variables.
IV. Discussion
This paper investigated methods that can be applied to predict the risk of cardiovascular disease. The existing methods for diagnosing cardiovascular disease are time-consuming and costly. However, cardiovascular disease risk can be predicted using various types of measured data when machine learning is applied.
In this paper, we implemented a risk prediction model using KNHANES-VI data. A DBN was used to implement the cardiovascular disease risk prediction model. Data analysis using statistical techniques showed that age, SBP, DBP, HDL, smoking, and diabetes were associated with cardiovascular risk. In other words, the prediction system can predict risk using six variables. The prediction model utilizes a DBN. The DBN consists of four input variables and one output variable. The experimental results show that it performed better than other methods. The method proposed in this paper appears to be effective for the risk prediction of cardiovascular disease and is expected to be particularly applicable to cardiovascular disease prediction in Koreans.
Future research will focus on deep learning research to improve the performance of DBN node optimization and prediction.







 XML Download
XML Download