

 PDF
PDF ePub
ePub Citation
Citation Print
Print


I. Introduction
Major public repositories for microarray gene-expression data, including the Gene Expression Omnibus (GEO) [1] and ArrayExpress [2] have started accepting whole-genome epigenetic datasets created by RNA-seq and ChIP-seq technologies. These very large datasets present a challenge for efficient data retrieval system developers. Current tools for microarray data retrieval can be classified into a few categories (Table 1). The first category includes the Gene Expression Atlas [3], developed by the European Bioinformatics Institute (EBI), and GEO, developed by the National Center for Biotechnology Information (NCBI). The advantage of these tools is their ability to search for specific gene expression patterns under specific biological conditions. However, searching is only possible after all data have been preanalyzed; therefore, these tools offer very limited search coverage of about 9% (Supplementary Figure 1). The second class, including GEO DataSets (http://www.ncbi.nlm.nih.gov/gds), developed by NCBI, and ArrayExpress, developed by EBI, which retrieve high-throughput functional genomic data based on the free-text metadata of experiments. These tools are divided into two types. The first type enables the user to input free-text keywords in a search system to search experiments related to specific biological conditions. The second type involves controlled vocabulary or ontology-based query systems. Given the vast diversity of biological conditions under which functional genomic datasets are created, queries are systematically guided by standardized terminologies for cell types, diseases, organism parts, etc., and their combinations may greatly improve performance and reduce the ambiguity of retrieval. These tools use a variety of controlled vocabulary or ontologies. Representative of GEO, ArrayExpress uses Medical Subject Headings (MeSH) [4] and Experimental Factor Ontology (EFO) [5]. MeSH allows the construction of terms that are easy to navigate and are useful to the search system because it consists of a hierarchy with 2013 trees (http://www.nlm.nih.gov/mesh/introduction.html). However, MeSH was created for indexing medical literature. Accordingly, MeSH does not include experiment-related terms such as "flow-sorted," "Affymetrix Gene Chip ontology," or "0 hour treatment." Thus, MeSH is not suitable for controlled vocabulary when an experiment search is performed. EBI overcame the limitations of MeSH by creating the EFO to which they applied the ArrayExpress search system. EFO provides a systematic description of many experimental variables; however, this ontology does not have a suitable structure for term navigation when an experiment search is conducted, because each category only has a depth of 2–4 (http://purl.bioontology.org/ontology/EFO) experimental conditions. For example, EBI tools (Atlas, ArrayExpress) provide only four filter conditions.
We aimed to overcome the limitations of previous retrieval tools by developing Gene Expression data Explore (GEE), which uses eVOC and EFO to overcome the limitation of previous controlled-vocabulary-based search systems. eVOC is a controlled vocabulary for unifying gene expression data [6]. eVOC and EFO are representative ontologies for the description of high-throughput functional genomics data. The eVOC and EFO ontologies include essential terms for the efficient retrieval of high-throughput functional genomic datasets. eVOC is an ontology that associates labeled target cDNAs for microarray experiments, or cDNA libraries and their associated transcripts with controlled terms in a set of hierarchical vocabularies and consists of 4 orthogonal controlled vocabularies, including anatomical system, cell type, pathology, and developmental stage. eVOC has a well-defined classification structure for term navigation; however, it only includes 2,260 terms. On the other hand, EFO has about 7,000 terms, but a poor classification structure. Thus, we merged eVOC and EFO by retaining the structure of eVOC to reflect the search system of GEE. GEE provides a specific advanced search system called the experiment design query constructor (EDQC), which provides five categories and 13 filter conditions, including "antibody", and includes 1,516 terms. Previous search systems provide only web applications; however, GEE provides the first mobile application. Thus, users are able to perform an experiment search regardless of time and place. The GEE website is http://www.snubi.org/software/gee, and the GEE app can be downloaded from the Apple App Store.
II. Methods
1. Data Collection and Management
GEE covers all transcriptomic platforms, including RNA-seq and ChIP-seq, as well as different types of microarray technologies. GEE archives 31,245 high-throughput functional genomic datasets with 710,038 samples extracted from GEO and ArrayExpress, i.e., 978 (911 samples; 2,408 platform types) and 30,267 (709,127 samples; 8,127 platform types) experiments from ArrayExpress and GEO, respectively. Additionally, 2,720 highly curated GEO DataSets (GDS) are included (Supplementary Figure 1A). GEE has the largest data scope (standard date: 2012.01.01).
2. eVOC Ontology-Based Annotation of Datasets
We downloaded the OBO file format of the eVOC ontology and the owl format of the EFO ontology from the bioportal website (http://bioportal.bioontology.org) [7]. We extracted terms, synonyms, and associated information. Next, stop words were removed and executed. Stemming and normalization of eVOC terms, EFO terms, and all of the synonyms were performed by application of the Porter stemming algorithm. Then, we merged 2,264 eVOC terms and 5,081 terms from EFO using the bioportal mapping list (Supplementary Table 1), after which we mapped EFO to eVOC because the eVOC structure is well defined. We annotated all the highthroughput functional genomic datasets with ontology terms, which were processed using text mining. We annotated the datasets by using a MySQL full-text search method with four filter conditions. A different query method was applied to each category of terms (Supplementary Figure 2). Our work showed that the use of a full-text search method with 4 filter conditions and different query methods using eVOC and EFO is the best approach among several methods we tried for mapping (Supplementary Figure 3).
3. User Interface Feature
1) SEARCH option in web version of GEE
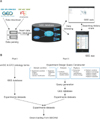
The GEE web interface contains two sections for generating search queries (Figure 1A). Section I offers an ontology-based keyword search function, which enables a user to select multiple ontology terms from an ontology term tree. Section II contains an EDQC, which enables a user to generate a query when designing experiments for high-throughput functional genomic data. The EDQC values were human curated. The EDQC consists of 3 classes, 5 parts, and 14 subparts. The sample condition class is composed of the sample extraction type, used anti-body, gene modification, organism, sex, and population. This class includes information associated with samples. The analysis class is composed of data normalization and data quality controls. This class includes information associated with data analysis. The platform class is composed of protocol manufacture, kinds of arrays, platform technology, platform support, platform coating, and platform hardware. This class included platform information, such as experiments using ChIP-seq or RNA-seq. All selected components are performed independently. Users can generate multiplex combination queries using all kinds of classes and terms. Furthermore, these queries provide correct results according to user-defined logic, and redundant results are removed. More information can be found in Figure 2B.
2) SEARCH option in app version of GEE
The GEE app enables the retrieval of high-throughput functional genomic datasets using eVOC ontology terms. The app provides a user friendly methodology. Initially, the user would have to download and install the GEE app from the Apple App Store. Next, the user uses one click to select the search term from among the eVOC ontology terms. When the user clicks the selected term, the GEE app provides a high-throughput functional genomic list of datasets from which a dataset name could be selected to obtain more information about the specific genomics. As a result, the GEE app displays more detailed information when the user selects the dataset. The app interface is shown in more detail in Figure 1B. The GEE app is currently under review in the Apple App Store.
3) GEE web and app interface construction of GEE
The GEE web version was created by using Hypertext Markup Language 5 (HTML5), cascading style sheets 3 (CSS3) and jQuery. The web version of GEE is available on the web at http://matrix.snubi.org:8080/GEE_index.jsp, and the app version of GEE is available from the Apple App Store.
4. Comparing Search Performance of Other Search Tools to GEE
We used four keywords ("breast cancer," "stem cell," "lung cancer," and "myocardial infarction"), which are the most frequently submitted terms in the PubMed query log [8]. We used our proposed tool to extract 500 GDS datasets randomly from among the GDS datasets. In addition, the same 4 keywords were used to manually extract related datasets from the 500 GDS datasets, after which the intersection dataset was extracted from the human curated datasets. We used GEO, ArrayExpress, and GEE to search this dataset using the 4 keywords obtained from the 500 datasets, after which we again obtained the intersection dataset with human curated datasets. Finally, we calculated the search performance using precision, by recalling the F-measure method (Supplementary Table 2).
5. SOFT and MAGE-TAB Conversion
GEE provides MAGE-TAB [9] and SOFT conversion. This enhances the efficiency of the retrieval process by allowing the use of filter conditions and specific queries. We extracted all attributes from MAGE-TAB. Specification ver. 1.1 has been made available together with SOFT guidelines (http://www.ncbi.nlm.nih.gov/geo/info/soft2.html), and the relation rules were created manually (Supplementary Table 3). The results provided on the GEE website are based on the results obtained by using the conversion rules. Overall, our scheme maps the GEO series (GSE) attributes to investigation description format (IDF), sample and data relationship format (SDRF), and raw and processed data files are mapped to GEO samples (GSM), and array design format (ADF) is mapped to GEO platform (GPL). A detailed description is included as Supplementary Table 4.
III. Results
1. Combined Effect of Using Ontology and EDQC
GEE uses an EDQC and an ontology-based query system to search high-throughput functional genomic data by using a pre-annotated data table. We calculated the mapping coverage in GEE according to the method described in Supplementary Table 2. We tested three conditions, including using only ontology (Supplementary Figure 4A), using only EDQC (Supplementary Figure 4B), and using ontology with EDQC (Supplementary Figure 4C and D). The results were calculated by each data format. Most data formats had more than 95% mapping coverage. Unfortunately, ADF was obtained when using ontology, with GSE in EDQC being the exception. However, all the conditions improved when ontology was combined with EDQC (Supplementary Figure 4C and D). This enabled us to conclude that a combination of ontology and EDQC is effective for searching high-throughput functional genomic data.
2. Comparing the Search Performance of Previous High-Throughput Functional Genomic Data Searching System and GEE
We calculated the precision, recall, and F-measure to compare the searching performance of GEO, ArrayExpress, and GEE. We randomly extracted 500 GDS datasets and used 4 keywords for sample queries. The keywords that were extracted were those most frequently submitted in the PubMed query log [8]. Details of the method are described in the Method section and Supplementary Table 2. The most important aspect of a search system is to search for the correct data in user defined queries and to ensure an abundance of results. These conditions can be satisfied by ensuring harmony between precision and the recall result. GEE produced a high F-measure score. The testing results show that GEE achieved the best score for all performance measurements compared to other tools (Figure 3). In particular, the recall result was perfect. This result shows that GEE searches the correct data in any biological query. Moreover, the F-measure is the most effective for testing, which means that GEE searches more accurately than GEO and ArrayExpress.
3. Example Query Using GEE
As shown in Figure 1A, the result of using the web version of GEE is that only the elements that are the most critical are shown and provide a good overview of the datasets in GEO or ArrayExpress with a hyperlink to each dataset. A search example using the web version of GEE is shown in Figure 1A. We demonstrated the performance of the web version of GEE by retrieving a particular sample query using the EDQC. The first sample query was executed by using "ChIP-seq," "embryonic stem cell," and "homo sapiens," containing more than 20 samples in the keywords from one dataset. "ChIP-seq" and "homo sapiens" contained more than 20 keyword samples from the EDQC in Section II and "embryonic stem cell" from the ontology term tree in Section I (Figure 1A). GEO, ArrayExpress, and GEE each produced 6 datasets as results (GSE36114, GSE32970 ... etc., 984 samples, 5 platform), 0 result datasets, and 18 experiment datasets as results (GSE30226, GSE30227 ... etc., 536 samples, 0 platforms) in response to the query.
The second sample query was based on the use of "anaplastic astrocytoma," and "eye neoplasm" as keywords. Both keywords are from the ontology tree in Section I (Figure 1A). GEO, ArrayExpress, and GEE each produced 0 datasets and 63 datasets (GSE7330 ... etc., 921 samples, 0 platform). However, ArrayExpress did not support sample count filtering, and the sample data link was broken. GEE provides a description of each dataset and its download link. Therefore, the user can download data when the dataset permission is opened.
The app version of GEE consists of two parts. Part I provides easy retrieval of high-throughput functional genomic data using an eVOC ontology tree with just one touch. When the user selects a term, the GEE app provides a list of related datasets, and term information appears when the user selects the dataset. Part II displays a summary of the information and a detailed description of the selected datasets. The resulting sample is presented in Figure 1B.
IV. Discussion
GEE has four main benefits, which will be discussed in detail in this section. First GEE enables specific queries to be made using eVOC and EFO vocabularies and the EDQC system. Moreover, it is possible to retrieve suitable high-throughput functional genomic datasets consisting of free text from diverse biological conditions. Biologists often design and execute new experiments because they are unable to easily find suitable experiment datasets. Therefore, many duplicate datasets are generated and saved in GEO and ArrayExpress. We expect all of these problems to be resolved through the EDQC of GEE because the EDQC will be able to provide suitable queries when users design experiments.
Second, GEE had the largest dataset scope, currently based on August 1, 2012. GEE archives 31,245 high-throughput functional genomic datasets (710,038 samples) from GEO and ArrayExpress. This huge data scope, including wholegenome epigenetic datasets, provides a wealth of resulting datasets upon retrieval. Beside GEE, there are several tools with which to retrieve datasets, such as the Microarray Retriever [10], GEOmetadb [11], M2DB [12], and Oncomine [13]. However, they do not provide whole-genome epigenetic datasets, such as RNA-seq and ChIP-seq. Therefore, there is no need for the user to simultaneously access both repositories when GEE is used. In addition, GEE provides a searching result for each platform together with sample information. This function provides elaborate information of high-throughput functional genomic datasets.
Third, GEE provides two optimized user systems: a web application of GEE (http://www.snubi.org/software/gee) and a mobile app of GEE. Every high-throughput functional genomic data retrieval system simply consists of web-based applications. However, GEE also provides a mobile app, which is convenient, rapid, and portable for the user. The GEE app is the first mobile application to search high-throughput functional genomic datasets. Assuming that users have smartphones, they will be provided with suitable high-throughput functional genomic datasets after just one click of the mobile app of GEE; thus, the mobile app allows the user flexibility.
Fourth, GEE is available with specific filter conditions and retrieval using MAGE-TAB and SOFT, the high-throughput functional genomic dataset formats of AR and GEO, respectively, with attributes such as platform technology, and a sample treatment protocol based on the MAGE-TAB and SOFT converter. These attributes allow the user to specify conditions for specific queries, and these queries contribute to the retrieval of accurate datasets in large high-throughput functional genomic datasets. As mentioned previously, GEE is the only tool that enables the retrieval of whole-genome epigenetic datasets and has a mobile app. GEE is also the only application that offers an elaborate searching system that uses the EDQC and ontology trees. We expect GEE (http://www.snubi.org/software/gee) to promote the evolution of retrieving high-throughput functional genomic datasets.
In the coming years, the number of whole-genome epigenetic and microarray datasets is expected to increase explosively. Therefore, the problems associated with the retrieval of large high-throughput functional genomic datasets are becoming increasingly important. GEE can play a key role in solving this problem.



 XML Download
XML Download