

 PDF
PDF ePub
ePub Citation
Citation Print
Print


I. Introduction
Medical examinations for the diagnosis of coronary heart disease involves many factors, including risk factors, symptoms, and examinations. The inspections carried out result in many clinical data attributes. To translate attribute clinical data into information, it is necessary to interpret the clinical data. Interpretation systems for the diagnosis of coronary heart disease are being developed. The development of information technology has moved the interpretation of clinical data to computer-based systems. An interpretation system of clinical data can serveas a decision support for clinicians in making diagnoses. The use of decision support systems has been shown to improve physician services, from both the doctor and patient perspectives [1].
Systems for the interpretation of clinical data for the diagnosis of coronary heart disease have been developed by utilizing data mining algorithms. The use of data mining algorithms in such systems can be grouped into two approaches, namely, non-black-box and black-box. In the black-box approach the system cannot explain the relationship between the input and output attribute, which can be understood by clinicians. Research interpretation systems for diagnosis using the black-box approach include those using neural networks [2], support vector machine (SVM) [3], K-star [4] and naive Bayesian [3]. The non-black-box approaches in clue those using C4.5 algorithms and fuzzy inference systems [567].
There have been few attempts to develop a system to diagnose the type/level of coronary heart disease, including that by Nahar et al. [8]. Their study assessed the performance of several data mining algorithms for the diagnosis of coronary heart disease. The algorithms included black-box and non-black-box approaches. The non-black-box algorithms considered were J48 (C4.5) and PART. The study converted multiclass classifications to binary classifications. Similar to the research by Nahar et al. [8], Prabowo et al. [9] proposed a system of diagnosis of coronary heart disease that adds randomization before the classification process. The algorithm was tested together with those considered by Nahar et al. [8]. In addition to these studies, Dominic et al. [10] also proposed a system for the diagnosis of coronary heart disease using black-boxand non-black-box data mining algorithms. The non-black-box algorithm used was a decision tree. Subsequent research was conducted by Setiawan et al. [11]. This study compared several methods of feature selection and data mining algorithms with a black-box approach naive Bayesian and non-black-box J48.
In the studies that have been done with non-black-box approaches to implement conversion into binary and multiclass, the average yield performance is still relatively low, especially for the true positive rate (TPR) [8910] and F-measure. Low TPR and F-measure values indicate that the system has a poor ability to interpret the data. This data should be interpreted as indicating one of the four types/levels of coronary heart disease, but instead, it is interpreted as indicting that the patient is healthy. The results of research conducted by Wiharto et al. [3], which tested several types of multiclass SVM algorithms and used the UCI dataset repository [12], showed good performance for the type/level with a large amount of training data.
The problem of data imbalance can be addressed by several approaches. Ramyachitra and Manikandan [13] combined several methods to overcome the problem of data imbalance. These methods included data-based approaches and feature selection. Data-based approaches include those using oversampling, undersampling, and hybrid [14]. One method of oversampling is the synthetic minority oversampling technique (SMOTE), developed by Chawla et al. [14]. A study conducted by Wiharto et al. [4] applied the oversampling method to restore the balance of data in a system to diagnose coronary heart disease. The oversampling method uses a combination of resampling, SMOTE, deletion of data beyond the limit of its attributes, and the removal of duplicated data. Unfortunately, as [4] showed, the process cannot be interpreted by the clinician. The approach of feature selection has also been widely used to address data imbalanced in relation to the diagnosis of coronary heart disease, as was done in the studies by Nahar et al. [8] and Prabowo et al. [9].
Referring to previous studies, this paper proposes a system for clinical data interpretation for type/level diaagnosis of coronary heart disease. The system uses a non-black-box classification algorithm, C4.5. Classification implementation taking a multiclass approach is adopted, and the imbalance of data is also considered. To address the imbalance of data two methods are employed: oversampling SMOTE and the feature selection method of information gain.
II. Methods
1. Data
This study used the coronary heart disease dataset provided by the University of California Irvine (UCI) repository, which can be accessed online [12]. The dataset has 75 attributes; not all of these are used in the interpretation of clinical data systems for diagnosis. Referring to research conducted Marateb and Goudarzi [15], this study used 20 attributes, as shown in Table 1. The output diagnoses are given as healthy, sick-type/level 1, sick-type/level 2, sick-type/level 3, and sick-type/level 4 [28].
2. Synthetic Minority Over-sampling Technique
SMOTE is an oversampling method that is used to address the problem of data imbalance. SMOTE creates an instance of a class of synthetic minority that operates in the feature space of the data space. By duplicating the minority class examples, SMOTE generates a new synthetic sample by extrapolating from the existing minority sample with a random sample obtained from the value of k nearest neighbors. With the synthetic results on an increased minority sample, the area of decision of the minority class is widened [14].
In this study, the SMOTE process is preceded by resampling with the aim to assess the accuracy of statistical samples by providing a snapshot or by randomly replacing data from a subset of the available data. The resampling process results in data duplication. Meanwhile, SMOTE results in an attribute whose value is not within the range of attribute values. To overcome this, resampling and SMOTE are carried out after the removal of duplicated data and deletion of data that exceeds the attribute-value limit.
3. Feature Selection
Dimensionality reduction (DR) is the process of reducing the dimension of the data, with the possibility of a slight reduction in information. DR comprises two steps, selection (feature selection) and transformation (feature extraction) [16]. In this study, DR is used for feature selection with the method of information gain (IG). The process of feature selection with IG is done by reference to the IG, which is a measure of the effectiveness of an attribute in classifying the data. The IG value is obtained by the following calculations (1)–(2) [17]:
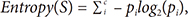
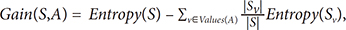
where
c : the number of grade classification
pi : the number of samples in class i
A : attribute
V : a possible value for attribute A
Values(A) : the set of possible values for attribute A
|Sv| : the number of samples for the value v
|S| : the total number of data samples
Entropy(Sv) : entropy for samples that have value v
Attribute selection is carried out using the following procedure:
Step-0 : IG is calculated for all attributes, based on Equation (2)
Step-1 : All features are sorted by IG in order from the highest IG value to the lowest
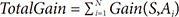
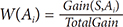
Step-4 : Repetitions are performed to add attribute weights,
Wn = 0.0; FOR i = 1 to N Wn = Wn + W(Ai) IF Wn ≥ Threshold THEN go to Step-5 ENDIF i = i + 1 ENDFOR
Step-5 : Attribute number i is selected, which attribute to 1, 2 .... i.
4. Method Proposed
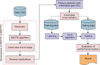
The model-based clinical data interpretation system C4.5 algorithm for the diagnosis of coronary heart disease is shown in Figure 1. The system consists of oversampling using SMOTE development (mSMOTE), a feature selection algorithm using IG, multiclass classification, and performance evaluation. The multiclass classification algorithm used is C4.5 which is a development of the decision tree algorithm ID3 [18]. The algorithm has the same working principle, but the calculation of information gain is differently. In ID3, the learning process is done with reference to the calculation of the gain. The calculation of the gain in ID3 is same as the calculation of the gain in the feature selection process with the IG as shown in Equations (1)–(2). In the C4.5 algorithm, the learning process uses the ID3 normalized gain, as written in Equations (5)–(6):
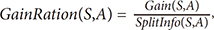
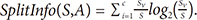
5. Performace Evaluation of the Proposed System
The method used to assess or validate the accuracy of the model of the proposed system is k-fold cross validation. The method simply divides the data into k subsets, with k = 2,3,4, ..., 10. Then, these k subsetsare divided into two, k – 1 subsets as training data, and a subset of data for testing.The performance of the system is assessed with reference to the confusion matrix table for multiclass, as shown in Table 2. Based on the table calculation system performance parameter value, the calculation is performed by counting TP, TN, FP, and FN results for each type/level. As an example we show the calculation of the values of TN, TP, FP, FN on healthy output, the calculation shown in Equations (7)–(10):
The same concept can be used in calculation for each type/level, so the values will be TP, TN, FP, FN for each type/level. Furthermore, the values of sensitivity, specificity, PPV, NPV, AUC, accuracy and F-measure are calculated, as shown in Equations (11)–(17):
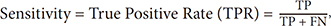
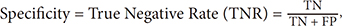
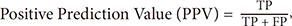
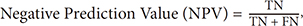
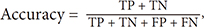
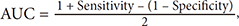
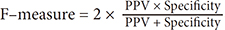
In this research, three models of interpretation systems for the diagnosis of coronary heart disease were considered. The first interpretation system uses C4.5 algorithm. The second combines both mSMOTE and C4.5 algorithms. The third is a system that combines mSMOTE and feature selection with IG and the C4.5 algorithm.
III. Results
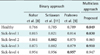
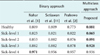
The test system based clinical data interpretation algorithm C4.5 for the diagnosis of coronary heart disease can be presented in terms of several aspects. First, we report the system performance for each type/level for the models using C4.5, mSMOTE+C4.5 and mSMOTE+IG+C4.5, as shown in Table 3. The system performance is validated by using 10-fold cross-validation. Second, in addition to the performance for each type/level, we measured the average performance, as shown in Table 3. The average performance is the average value of all type/level for the model and the same performance parameters.
Third, we report the results of testing the significance of differences (p-value) of the C4.5 system model. Testing was carried out using a t-test with a confidence level of 95%, and the results are shown in Table 4. Fourth, we present a knowledge base which is modeled in a decision tree, which describes the relationship of attributes with coronary heart disease, as shown in Figure 2. The knowledge base shown in Figure 2 was obtained by a system with an mSMOTE combination model, with feature selection, IG and C4.5. The use of feature selection reduces the IG from 19 attributes to 16 attributes of coronary heart disease.
IV. Discussion
In this section we will discuss the results in terms of three considerations. First, we will discuss the effect of oversampling and the feature selection process on the performance of the C4.5 algorithm. Second, we will discuss the analysis of the resulting decision tree models. Finally, we will compare our method with some previous research that used data mining algorithms with a non-black-box approach.
Oversampling with the mSMOTE method was used in a previous study, which combined it with a black-box classification algorithm, namely K-star [4]. The results showed a significant improvement. The combination of classification algorithms with a non-black-box approach, namely, C4.5 with mSMOTE produced the results shown in Table 3. Based on the results of the significance test (p-value) with a 95% confidence level, as shown in Table 4, there was a significant difference among the model systems using mSMOTE+C4.5 compared with that using only C4.5. The results also show that the use mSMOTE provides significant improvement (p < 0.05). This was also proved by Choi [19].
Furthermore, in addition to using mSMOTE to address the problem of data imbalance, this study also reduced the dimension of feature selection data. The performance with the addition of feature selection was improved for almost every type/level except type/level 4. In type/level 4, there is no improvement for any of the performance parameters. This caused necessary variable amount in order to be able to distinguish the type/level 4 with each other, so that if reduced will result in a drop in performance. Model systems with a combination of mSMOTE feature selection and C4.5 also able to provide significant improvements to the system model using the C4.5 algorithm, as shown in Table 4. As compared to the model using mSMOTE+C4.5, there was an improvement with low significance. This is seen clearly by considering the p-value in Table 4. The average performance of the system model with reference to the AUC value increased by 2.8%. It increased from 81.4% to 84.2% in comparison with the system that makes no use of feature selection, which 59.5% to 84.2% or 24.7% of the system models without mSMOTE. The AUC value was in the range of 80%–90% [20], which can be considered good.
Interpretation of clinical data using a combination of mSMOTE, feature selection, and C4.5, can be a valuable tool for clinicians. The C4.5 algorithm results in a decision tree structure as shown in Figure 2. A decision tree also can be written in an IF-THEN format. Another example of the output type/level 3 is
IF thal > 3 and years ≤ 32.43 and ca ≤ 0 and tpeakbps ≤ 159.07 and restecg > 1 THEN num = 3.
Using the model, a clinician can perform an analysis of the decision tree generated and determine whether it is in accordance with the knowledge and experience of the clinician. With a decision tree, if there is no match, then we modify the resulting decision tree algorithm C4.5. Interpretation of these data enables the clinician to understand the workings of the system for the diagnosis coronary heart disease. Clinicians can not only know the results, but can also intervene in the structure of the resulting decision tree.
Next we compare the proposed system to some previous research, which used non-black-box data mining algorithms, namely J48 and 10-fold cross-validation. The first study was conducted by Nahar et al. [8], on the implementation of algorithms using the J48 binary classification approach. The resulting performance for the TPR and F-measure parameters for type/level healthy was better than that of the proposed system, both with and without feature selection, as shown in Tables 5 and 6. This is due to the mSMOTE process, in the elimination of duplicated data in the subprocesses, which results in a decreased amount of data on the type/level of healthy compared to the amount of data on the type/level of healthy research Nahar et al. [8]. Decreasing the amount of data results in a lower TPR value, and a low TPR results in a low F-measure. Regarding the TPR and F-measure for the type/levels 1-4, the proposed system showed much better performance than the method of Nahar et al. [8]. Such improvement is due to additional amounts of data in the type/level 1–4 mSMOTE result. The overall significance test based on the results in Table 7 with a confidence level of 95% indicates that the proposed system achieves better performance than the previous method. Both with and without feature selection, it provides a significant performance improvement (p < 0.05).
The next comparison is with research conducted by Prabowo et al. [9] which was not much different from the research of Nahar et al. [8], as shown in Tables 5 and 6. The combination of randomization and feature selection with computer feature selection (CFS) and the J48 algorithm did not provide a significant improvement in the study, so the proposed system achieves better results, as shown in Table 5. This is evidenced by the significance test results shown in Table 7, where the p-value is <0.05. In the research of Prabowo et al. [9], in addition to using feature selection CFS, motivated feature selection (MFS) was also used. In comparison with the combination of randomization, MFS, and J48 feature selection, the TPR and F-measure performance for all type/levels of the proposed system is relatively lower. Unfortunately, the method proposed by Prabowo et al. [9] uses the conversion of multiclass classification to binary. In [9], the classification process is done for each type/level, so there are five models of the diagnosis system. Tables 5 and 6 show the resulting system performance of all five models of diagnosis system. This is different from the multiclass approach. In this approach there is only one model of diagnosis system, with output there are 5 types/levels. In a binary classification approach, to obtain a single diagnosis system model with an output of five type/levels, The classifications must be compiled again into a single system. With a compiled system model, the performance may decline in comparison to that obtained using a model system for each diagnosis for each type/level.
Finally, the accuracy performance of our system is compared with the performance of systems proposed in previous studies. The accuracy performance of our diagnosis system is compared with diagnosis systems without feature selection. The proposed diagnosis system shows better performance with low significance (p > 0.05) in comparison to the systems developed by Nahar et al. [8], Prabowo et al. [9], and Setiawan et al. [11], as shown in Tables 7 and 8. Using feature selection, the performance of the proposed system is better, with low significance (p > 0.05) in comparison with previously proposed systems, as shown in Tables 7 and 9.
The accuracy performance is very similar, but previous studies showed low TPR values and high TNR values. In contrast, the proposed system has an accuracy that is very similar, but the TPR value is much better, and the TNR is also good. The proposed system achieves good performance in interpreting patient data to produce high rates of true positive and true negative results.







 XML Download
XML Download