

 PDF
PDF ePub
ePub Citation
Citation Print
Print


I. Introduction
Over the past decades, the data collected in the intensive care units (ICUs) has grown exponentially and been used selectively in data mining studies [1]. However, the large amounts of data are still underutilized for the care of critically ill patients in the ICUs. Moreover, considering the unavailability and lack of human experts for various reasons, busy or novice physicians can overlook important details, while automated discovery tools built on various prediction models could analyze the raw data and extract high-level information for the decision maker enabling better decisions [2]. Likewise the ICU setting is particularly well suited for an implementation of a data-driven system which acquires a large quantity of data to discover relationships for diagnostic, prognostic, and therapeutic factors using well-designed, predictive data mining models.
However, development of a clinically applicable and scientifically accurate critical care prediction tools is not an easy task, considering issues involved with complex data collection and inconsistent analysis methods. For instance, some data are not objectively measured (or recorded) which are then not recorded in a standardized format (e.g., categories of admitting diagnosis, categories of underlying chronic health issues, etc). Additionally, some data require constant updates at a reasonable interval range (e.g., daily physiological values, active treatment including medication and procedures performed, etc). Moreover, challenges that are directly relevant to different data mining methods and scientific validation for the produced results must be rigorously tested so that the predictive model can be applied in a critical care setting. A standard statistical method such as logistic regression has been well received by critical care professionals to predict the risk of mortality or adverse events for patients with critically illnesses or injuries admitted to ICU [3-7]. However, these predictions are not accurate enough for individual patients and no tools exist to reliably predict an individual patient's progress on a critical care condition in a timely manner. Currently, new prediction approaches using machine learning algorithms, such as artificial neural networks (ANNs) and decision trees (DTs), have resulted in a number of prediction models in different critical care settings [8-14]. However, an evaluation of the performance is still under discussion and very few studies have paid attention to reporting on the handling of missing and noise data, treatment of different types of data, and data dimension reduction techniques.
Therefore, it is our goal to develop a critical care mortality prediction model by comparing new computational techniques including ANN, support vector machine (SVM), and DT to a conventional standard technique, the logistic regression model. To derive a well-performed, predictive model that uses various critical care data extracted from a large number of representative samples, University of Kentucky Hospital (UKH)'s ICU data was tested and the resulting models were assessed on their prediction performances.
II. Methods
Three study goals to achieve are: 1) to construct an ICU prediction model given the UKH-ICU study population and explore to what extent the constructed model can confirm previous results obtained from the previous logistic regression (LR)-based APACHE III prediction models; 2) to identify relevant clinical input factors for the ICU prediction models by using Logistic Regression; and 3) to compare prediction performance between DT, ANN, SVM, to LR. In this comparison, the measures of performance were assessed using the area under the receiver operating characteristic (ROC) curve (AUC). The following sections describe study setting and participants, variables included, and data analysis techniques used.
1. Study Setting and Participants
The study data used in this study were retrospectively collected from 23,446 patients (on 38,474 admissions) admitted to the UKH located in Lexington, KT, USA between January 1998 to September 2007. The UKH is a 489-bed, state-operated, teaching academic and tertiary referral hospital. Over the past decades, the UKH has collected patients' ICU data and the trained APACHE nursing staffs has carefully entered the data into the APACHE III Critical Care system [15]. According to the UKH APACHE data collection guideline, the patients under 20 years old, burned patients, several transplant patients except for renal and liver transplants, and patients with an ICU stay of less than four hours are not included in the APACHE system, Therefore, our study data does not include those cases in our analysis. Of the selected data, half of them (n = 19,227, 50%) were randomly selected and designated as training data set to be used for prediction models construction, and the remaining half (n = 19,247, 50%) was used to test the performance of the constructed models (testing data set). Thus, both training and testing data set are mutually exclusive. Approval from University of Kentucky's institutional review board, which meets federal criteria to qualify for exemption certification, was obtained. Therefore, patient identifiable data were removed before the data was available for the study.
2. Study Variables
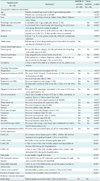
The variable sets used in this study are shown in Table 1. It contains variable names, description and exemplary data values, and selected study variables to build the best prediction model for our study. For the listed 41 variables including outcome (survival status: 1 refers to death, 0 refers to alive) are listed in the first column by five variable categories such as demographic/admission, chronic health, physiology, cardiac, and outcome sections. The Yes mark in APACHE III column of Table 1 refers to the variables for LR-based APACHE III prediction model, while the Study Variables column refers to those variables used to build the mortality prediction for our study. Those study variables were first selected based on Pearson's chi-square test for categorical variables and t-test for continuous variables (p-value < 0.05). The logistic regression (Forwarding) was then performed to finalize the study variables, which resulted in 15 variables checked in Table 1. All the acceptable data value ranges used in the study comply with the Cerner's APACHE III Critical Care system [15].
The distribution of cases used in the study is outlined in Table 2, which includes APACHE III scores, age, gender, ethnic, admission type, and admission origin that remained unchanged during the patient's admission [16]. The variables encompass admission information, physiological variables, and chronic conditions. The ICU death outcomes, such as APACHE III scores and mortality, were also recorded. Physiological variables extracted from the APACHE critical care system were manually entered within the defined physiology data midpoints and acceptable data entry range. Some physiology data such as arterial blood gases (ABG)-related variables (ABG_Intubated, ABG_FiO2, ABG_PaO2, ABG_PaCO2, and ABG_pH) were aggregated into two variables (ABG_PaO2 and AaDO2) in accordance with APACHE methodology to record the worst ABG. Glasgow Coma Score (GCS) variables were combined into a compound score. Remaining data was carefully audited for outliers, erroneous, and missing values. Missing data for the continuous variables were estimated with simple imputations using the median non-missing value. The method used to reduce dimensions (variables) is LR from SPSS PASW statistics (SPSS Inc., Chicago, IL, USA).
3. Measurements and Data Analysis
The primary outcome variable was the vital status (death or alive) at the time of ICU discharge captured in the APACHE III critical care system. APACHE uses only variables and data that are captured within the first 24 hours of ICU admission as accepted as conventional predictor variables. Therefore, the study did not capture changes in physiological status and the relative contributions of age and comorbidities. Given the same variables, the study compared the predictive accuracy of ANN, SVM, and DT derived from UKH's ICU patients' data with the APACHE III scoring system. The probability of ICU outcome prediction, p was derived from the APACHE III equation given in the section 1 of Knaus' paper [4].
The ANN architecture used in the study was a back-propagation network with two-hidden layers, a layer between the input and output layers. Estimated accuracy, an index of the accuracy of the predictions, was measured based on the differences between the predicted values and the actual values in the training data [17]. The number of units such as input, hidden, and output were recorded. The study used the exhaustive prune method. The method starts with "a large network and prunes the weakest units in the hidden and input layers as training proceeds" [17]. This method is usually the slowest for NN, because the network training parameters are chosen to ensure a very thorough search of the space of possible models to find the best one. However, it is known to yield the best results [17]. For the decision tree analysis, the Clementine's C5.0 algorithm (SPSS Clementine is commercial data mining software that allows data process, analysis, and modeling to collaborate in exploring data and building models based on various built-in algorithms) was used. The model "works by splitting the sample based on the field that provides the maximum information gain and each subsample defined by the first split is then split again, until the subsamples cannot be split any further" [17]. Previous studies show that C5.0 models are quite robust in the presence of problems such as missing data and large numbers of input fields [17]. In addition, an easier interpretation and a powerful boosting method to increase accuracy of classification are major strengths of the C5.0 models.
The SVM is a classification and regression technique that "maximizes the predictive accuracy of a model without over fitting the training data" [17]. Our data set is very large volume with large number of predictor variables; therefore the SVM was chosen to bring as an option for developing optimal prediction model for the ICU mortality. The high-dimensional variables are separated into categories and then a separator found between each category is transformed for further analysis. "Following this, characteristics of new data can be used to predict the group to which a new record should belong" [17]. To evaluate performance of the different prediction models, the study reported AUC. The AUC was used to measure for "how well the model can discriminate between positives and negatives" based on specificity and sensitivity values [1]. In other words, the AUC was used to assess the ability of the system to distinguish between individual patients who lived and those who died [18].
III. Results
1. Overall Description of UKH Critical Care Data
A total record of 38,474 ICU encounters was obtained from 23,446 patients (average number of visits per a patient, 1.64 visits) admitted to UKH-ICU between January 1998 and September 2007. The demographic and clinical features are presented in Table 2. The average age of the patients was 55.46 (standard deviation was ±15.97) and 59.88 percentage (n = 23,040) of the patients was male. Predicted APACHE III scores of the study participants, calculated within a day of ICU admission, was 50.98 (±28.80). Actual ICU length of stay (LOS) was 4.84 (±9.31) days, which was obtained from ICU discharge information. Non-operative encounters (n = 24,868, 64.95%) were the most dominant in the study. The most frequently recorded chronic health item in the study group was diabetes (n = 6,884, 17.89%) followed by immuno-suppressed diseases (n = 5,250, 13.65%). Most commonly suspected diagnosis at admission included post-operative diagnosis of coronary artery bypass grafting (n = 1,860, 4.83%), congestive heart failure (n = 1,597, 4.15%) and acute myocardial infarction (n = 1,485, 3.83%). Complete information about characteristics of the study participants and variable selected for each model can be found in Tables 1, 2.
2. Variables Selected
Forty variables (V = 41) including one outcome variable was the full set of the study dimensions obtained from APACHE III critical care system. A fifteen variable set (V = 15) was chosen using the logistic regression (forwarding) in Table 3. A complete list of study variables in each variable set along with p-value is listed in Table 3. The included variables are: a calculated field of age weight plus chronic (PhyResvPts), admission category, disease group, chronic health item, elective surgery, mean arterial pressure (MAP), respiratory rate (RR), GCS, GCS on medication, white blood cell (WBC), albumin, bilirubin, ABG, aid-base abnormalities (ABA), and death status. The study found that most cardiac-related variables (e.g., CABGIG, CABGGraft, etc.) were not included in the reduced variable set. In addition, some patient demographic and admission information such as gender, race, admission service and readmission were excluded in the reduced variable set (V = 15).
3. Overall Performances
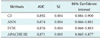
All four models, APACHE III, C5.0, ANN, and SVM models, were constructed to predict the ICU outcome. The accuracy of these four methods for outcome prediction was measured to assess prediction performance in Table 4. Among four models, the best performing model is C5.0 (AUC, 0.892), followed by SVM (AUC, 0.876), APACHE III (AUC, 0.871), and ANN (AUC, 0.874). As resulted in our predicted models using only 15 chosen variables, two machine models, DT and SVM, performed slightly better than that of the conventional APACHE III prediction model in our data set (V = 15). Among the machine learning models built, our study revealed that the DT slightly outperformed that of LR, SVM, and ANNs. This study result indicates that all four models performed within the level of a medically acceptable prediction range, which is over 80% of the AUC. Typically, model developers require an AUC of the ROC curve to be 0.70 [19-21].
Figure 1 visually shows the performances of the four models built. It is apparent that one of non-traditional methods, the decision trees using C5.0 algorithms, yielded larger ROC areas than that of a standard statistical method, LR. In addition, the results of ANN and SVM were as good as that of LR. Again, this assures that all of our four models built show very good discriminatory values with AUC ranging between 0.80 and 0.90, achieving good to excellent calibration assessments.
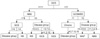
As resulted in our study, the decision tree outperformed among the study models. In order for us to closely review the branches of the resulted decision tree, the following Figure 2 illustrates a shorten version of the tree result. In this decision tree, split rules are explained with power of splitter, which explores further analysis on individual value ranges selected for each variable to branch-out to the next level of the decision performed. In our study result, the first level decision branch in this tree is GCS predictor which separates score more or equal to 11 followed by ABG less than or equal to 9. However, it may contain potential to visually depict critical care decisions, which can further be used to develop critical care practice guideline.
IV. Discussion
The primary goal of the study was to construct an ICU outcome prediction model from 38,474 admissions only using the data captured within the first 24 hours at UKH-ICU. The three models were developed using the ICU data extracted from the UK APACHE III Critical Care system and included patient demographic, admission information, physiology, and chronic health conditions as predictor variables (input) and an ICU discharge status as a response (target) variable.
The most interesting outcome of this study was that the DT model outperformed those of LR and ANN-based models. For several reasons, in the past studies, decision tree algorithms are not the favored choice of data miners. For example, the following criticisms show limitation on the use of DTs: classes must be mutually exclusive, final decision tree dependent upon order of attribute selection, errors in the training set can result in overly complex decision trees, and having missing values for an attribute make it unclear which branch to take when that attribute is tested. Nonetheless, the past studies have reported controversial findings on the C5 algorithm. For example, Delen et al. [22]'s result (C5.0 was the best predictor with the highest accuracy of 93.6% in predicting breast cancer survivability) supports our finding of the best prediction resulted from C5.0 methods in all three-performance measurement outcome. Unlike the study of Delen et al. [22], Ramon et al. [1] reported that the AUCs of decision tree based algorithms (decision tree learning, 65%; first order random forests, 81%) yielded smaller areas compared to those of naive Bayesian networks (AUC, 85%) and tree-augmented naive Bayesian networks (AUC, 82%) in their preliminary study on a small data set containing 1,548 mechanically ventilated ICU patients [1]. This result does not comply with our finding of the superiority of decision tree based models. Although the study was not intended for comparing multiple machine learning algorithms, Crawford et al. [23] concluded that a decision tree used in their study provided a clinically acceptable mining result in predicting susceptibility of prostate carcinoma patients at low risk for lymph node spread.
Considering the noticeable lack of information about the use of decision tree algorithm for predicting health outcomes, this study contributes to our understanding of the performance of the decision tree-based algorithm such as C5.0 in comparison to those of the neural and logistic models. Furthermore, the major limitation for the use of ANNs is the lack of logic between input and output nodes, which are not explicit because of hidden layers. Some studies suggest that decision trees can be applied to uncover the hidden layers in order to explain the hidden clinical implication in the ANN's black box area. Therefore, a more elaborate comparison using a different decision tree algorithms (CART, CHAID, ID3, etc.) and ANN algorithms should be conducted to provide reliable and generalizable research findings. Previously studied data mining algorithms in predicting hospital or ICU outcomes have mostly used ANN methods whose performance was not compared to those of decision trees [24,25].
To identify the best predictor variables for the model, the study performed an LR-based dimension reduction approach. The study confirmed that the reduced study variables in machine learning algorithms slightly better than those with conventional APACHE III variables. As confirmed by four AUC performance measures, the predictors included in three machine learning-based models performed slightly better with the statistically chosen variables than that of the APACHE III variables. The unanimous variables in both variable sets are disease group, chronic health item, MAP, RR, GCS, WBC, Albumin, Bilirubin, ABG, and ABA. These variables are mostly drawn from physiology lab values except for disease and chronic health items. This finding reassures the importance of physiology lab to predict ICU mortality as proven in APACHE prediction modeling. Within the critical care context, the UK hospital's protocol of the Adult Trauma Alert Activation Criteria recommends critical variables such as MAP, RR, GCS, and ABG to be used as mandatory criteria to provide rapid and efficient mobilization of personnel and resources essential for resuscitation, evaluation, diagnosis and treatment of the multiply injured patient. In this protocol, systolic BP less than 90 and GCS less than 8 are indicative of issuing an adult trauma patient. Although this protocol is not specifically intended for an overall mortality of ICU, the decision paths, critical variables, and cut-off values can be validated in our further study. Likewise, the previous findings suggest that the overall performance was improved as variables were reduced [26-28]. Therefore, this result led us for further justification of our findings against the previous studies which concluded a simple model with lesser variables was much more effective and likely to be accepted and used by clinicians working in critical care setting [29].
The major contribution of the current study was the use of a large number of samples (n = 38,474), which represents almost every ICU patient admitted to UKH-ICU over the past decade. The use of small data sets has been identified as a major limitation in previous studies [17,30,31]. Considering the fact that the UKH is a largest and most comprehensive academic hospital within the state of Kentucky, the study findings are representative of public health observation in critical care services. In addition, secondary use of health data can greatly enhance critical care research, which can possibly suggest new ways of analyzing mined ICU data such as the results of decision tree paths.
The current study has several limitations, which have to be improved for prospective studies in ICU prediction modeling, if designed for a different research direction. First, the study only used the first day of ICU data, which did not capture intermediate progression on various treatment and physiology data changes. This limits the impact of clinical decision-making, since captured data is usually not updated during the patients' ICU stay [2]. The use of intermediate information rather than static data can suggest a more meaningful clinical implication in critical care. In their Silva et al. [2] and Harrison and Kennedy [29], electrocardiogram data and adverse events captured over the course of ICU treatments were used to build an ICU prediction model [29]. Therefore, in our next study, ICU data from the time of presentation (time dimension to be added for prediction modeling) will be performed which will also consider in predicting other ICU outcomes such as length of stay, days of ventilation, etc.
Second, considering the benefits of using data mining techniques, the data mining approach in clinical medicine should carefully be designed based on the capability and applicability of the medical domain knowledge throughout every process of the data-mining task. Although the study did not intend to focus on a certain disease category such as acute coronary syndrome or sepsis, it is apparent that the next step of UKH ICU data mining will consider in dealing with the specific disease related approaches. In this regard, we plan to develop further prediction models with the top 10 popular disease groups identified in our data set. In addition, the use of domain expert prediction compared to machine learning predictions will give us a better validation of the produced results.
Third, although our study used a large number of representative samples from a large teaching hospital, the data were collected from only one center. The original source of APACHE III Critical Care series have collectively captured critical care data from more than one institution nationwide, we hope to expand our study to develop a prediction model at a multiple centers. As recommended, the "determination of the applicability and usefulness of any predictive model requires independent and external validation in a population that is intrinsically different from the development sample" [31]. Again, we believe that further research is required to assess the clinical applicability of the developed model with hybrid and multiple modeling approaches in a larger pool of critical care patients at a multiple institutions.
In this study, we developed a well-calibrated ICU prediction model that outperformed the prevalent statistical model, APACHE III, using new machine learning algorithms such as C5.0, SVM, and ANN. The study used systematically collected critical care data from over a decade at a large academic teaching hospital. It confirms that machine-learning techniques generally improve the performance or accuracy of the outcome prediction. It is also clear that alternative machine learning, such as decision trees, which have not been investigated in many clinical settings, should be studied further to validate our study's finding. Moreover, further studies should give their attention to a multicenter-driven, hybrid machine learning-tested, special disease-focused and human expert-validated experimental design so that the overall quality, generalizability, and reproducibility can be improved in the study of machine learning in the critical care setting. In addition, the intensive care setting is well suited to implement a prediction tool that is being built on a wealth of critical care data populated every second. It will see more compelling demands if UKH and other major medical centers are ready to use automatically collected real time ICU data that requires a clinical decision support system to predict clinically reliable patient outcome. Therefore, more attention should be given to utilize the critical care data available, which can be of further assistance to busy clinicians who can then effectively monitor data patterns for optimal care. Conclusively, the study believes that the new machine learning algorithms can be integrated into the development of standard critical care systems so that critical care decisions can be improved to ultimately save critically-ill patients.



 XML Download
XML Download