

 PDF
PDF ePub
ePub Citation
Citation Print
Print


I. Introduction
In the medical domain, the most common use of an information retrieval system is to retrieve bibliographic information [1]. Previous studies on the information sources used by physicians reported that MEDLINE was by far the most commonly used resource [2,3]. However, sometimes MEDLINE retrieval is unsuccessful, especially for queries issued by inexperienced users [4].
Query expansion is the process of reformulating a seed query to improve retrieval performance [5] and is indispensable for solving ambiguous queries. Many types of query expansion methods have been developed. These methods can be classified into two groups: query expansion using a thesaurus and query expansion using pseudo-relevant feedback. Researchers have traditionally tried to adopt a thesaurus, such as WordNet, or the Unified Medical Language System (UMLS); however, the effectiveness of thesaurus adoption is still debated. Some research showed a meaningful improvement in query expansion, but other studies did not. The more widely accepted query expansion methods are those where user relevance feedback (RF) or pseudo-relevance feedback (PRF) is adopted. Previous studies evaluating the performance of PRF showed average precision improvements of about 14-16% over the unexpanded queries when tested on a small MEDLINE test collection [6,7].
Another issue exists when using the MEDLINE corpus; most information retrieval algorithms are evaluated on the Text Retrieval Conference (TREC) test collections. The characteristics of MEDLINE and TREC documents are very different in terms of co-occurrence, document length, and term distributions. Therefore, the effects of the algorithms, which have been proven effective on the TREC collection, also need to be verified on the MEDLINE collection.
We designed a set of comparative experiments in which various combinations of term ranking and term reweighting algorithms could be evaluated on the OHSUMED data set, a larger collection of MEDLINE documents than the previous collection, which was developed for testing information retrieval algorithms against physicians' information needs. The purpose of this study is to investigate the effects of query expansion algorithms within PRF on MEDLINE retrieval. In this paper, we describe the results of an evaluation that was performed using methods that range from classical to state-of-the-art term ranking algorithms.
This paper is organized as follows. Section 2 describes related works about automatic query expansion. Section 3 explains the baseline information retrieval system and the term-ranking algorithms that were chosen for the experiment, as well as the detailed term reweighting methods considered in the experimental design. Section 4 shows our experimental results. Section 5 discusses the common features of expanded terms found by different term ranking algorithms and the experimental results.
II. Related Work
A variety of approaches to automatic query expansion for improving the performance of MEDLINE retrieval queries have been previously studied. Hersh et al. [8] assessed the retrieval effectiveness of RF by using the Ide method on the OHSUMED test collection; this method gave better precision than that of the original queries at the level of fewer retrieved documents (i.e., 15, but not 100). For a small collection of 2,334 MEDLINE documents, Srinivasan [7] investigated PRF using different expansion strategies, including expansion on the MeSH query field, expansion on the free-text field alone, and expansion on both the MeSH and the free text fields. This author achieved significant improvement on retrieval effectiveness for all three expansion strategies over the original queries independently of the availability of relevant documents for feedback information. Recently, Yu et al. [9] suggested a multi-level RF system for PubMed, which let the user make three levels of relevance judgments on initial retrieved documents and then induced a relevance function from the feedback using the RankSVM. The system accuracy evaluation showed higher accuracy with less feedback than others in their study. States et al. [10] proposed an adaptive literature search tool based on an implicit RF that used information on citations that a user has viewed during search and browsing. In [11], using the OHSUMED test collection, authors studied a PRF technique based on a new variant of the standard Rocchio's feedback formula, which utilized a group-based term reweighting scheme.
Query expansion using the UMLS metathesaurus has produced mixed results. Aronson et al. [12] reported a 4% improvement in average precision over unexpanded queries on a small collection of 3,000 MEDLINE documents by mapping the text of both queries and documents to terms in the UMLS metathesaurus. Yang and Chute [13,14] and Yang [15] investigated a linear least square technique and expert network to map query terms to MeSH terms in the UMLS metathesaurus. The authors reported a 32.2% improvement of average precision on a small collection. Hersh et al. [16] assessed query expansion using synonym, hierarchical, and related term information, as well as term definition from the UMLS metathesaurus. All types of query expansion caused a decline in aggregated retrieval effectiveness on the OHSUMED test collection. Chu et al. [17] suggested a knowledge-based query expansion technique that only appended the original query with terms related to the scenario of the query, such as treatment and diagnosis, by using the UMLS metathesaurus and the UMLS semantic network. This achieved a 33% improvement in the average 11-point precision-recall over unexpanded queries for a subset of forty OHSUMED queries that belonged to five scenarios.
Because of increasing interest in automatic query expansion, which is based on the top retrieved documents, various approaches to select the best terms for query expansion have been suggested [18]. In previous studies [19-22], various types of comparisons of selected term ranking algorithms were made using the TREC test collections. When Rocchio's formula was used for reweighting expanded queries, the term ranking methods evaluated had no significant effect on the result [21]. However, performance improvement tended to be dependent on the test collection selected. Improvement was also dependent on the number of additional terms and the number of top retrieved feedback documents chosen for the experiment.
This study differs from previous work in three primary aspects. First, PRF is evaluated on the relatively large collection of 348,566 MEDLINE documents and 101 clinical queries from the OHSUMED. Because smaller sets of test documents and queries produce higher performance improvements, this study is valuable for verifying the effects of different algorithms of PRF on the larger test set of MEDLINE documents. Second, a comparison of different term ranking algorithms is performed. The spectrum of tests includes state-of-the-art term ranking algorithms, such as local context analysis (LCA) [23], as well as classic algorithms, including the Rocchio and Robertson selection value (RSV). Third, to identify the effect of the scores or ranks of expansion terms on the retrieval performance, term ranking algorithms are evaluated using varying term reweighting frameworks.
III. Methods
To compare several term ranking algorithms based on PRF, we developed a test-bed information retrieval system in which retrieved documents were sorted by the degree of relevance to queries. Based on the assumption that the top R documents initially retrieved are relevant, the automatic query expansion selects the top-ranked E terms from the pseudo-relevant documents. In this study, we evaluated the retrieval effectiveness of term ranking methods ranging from the classics to the state-of-the-art on the OHSUMED test collection. Because the importance of the terms in the expanded query is usually recalculated before submitting the query to the system for a second-pass retrieval, we evaluated the effectiveness of the combination of term ranking algorithms and term reweighting formulas in our experimental design.
1. OHSUMED Test Collection
We used OHSUMED [8] as a test collection. This collection is a subset of the MEDLINE database, which is itself a bibliographic database of important, peer-reviewed medical literature maintained by the National Library of Medicine (NLM). OHSUMED contains 348,566 MEDLINE references from 1987 to 1991 and 106 topics (queries) that were generated by actual physicians in the course of patient care. The references contain human-assigned subject headings from the Medical Subject Headings (MeSH), as well as titles and abstracts. Each query consists of an information need of physicians and a brief description of a patient. Relevance judgments corresponding to each query are provided using the scale of 'definitely relevant,' 'possibly relevant,' and 'not relevant.'
In our experiments, we limited the relevant documents to documents judged as definitely relevant; thus, only the 101 queries with at least one definitely relevant document were used. Each document is represented by combining the title, abstract, and MeSH fields. A query is generated from only the information needed field in the OHSUMED query because this query is the most similar to user queries issued in information retrieval systems.
2. Test-Bed Information Retrieval System
In the test-bed information retrieval system that we developed, text processing was performed through tokenizing, through removing stopwords using SMART [24] stopwords, and by applying Lovins' stemmer [25]. After the stemming process, each stemmed word was used as an index term for the inverted file. Once the inverted file was created with all of the indexed terms from the test collection, the query terms were matched against the indexing terms in a document to retrieve relevant documents. For our baseline retrieval model, we implemented the well-known Okapi BM25 weighting scheme [26]. In the Okapi BM25 formula, the initial top-ranked documents are retrieved by computing the similarity measure between a query q and a document d, as follows:
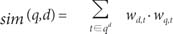
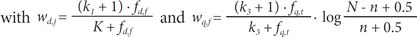
where t is a term of query q, n is the number of documents containing the term t across a document collection that contains N documents, and fd,t is the frequency of the term t in document d. K is k1((1-b) + b×dl/avdl). The parameters k1, b, and k3 are set by default to 1.2, 0.75, and 1,000, respectively. The parameters dl and avdl are the document length and the average document length, respectively, measured in some suitable unit (in this study, we used the byte length).
Once an ordered set of documents that match a given query the best is retrieved in the first run, the query is then automatically expanded using the top-ranked R documents (i.e., pseudo-relevant documents) in a PRF run. Finally, the reranked documents retrieved by the expanded query in the second run are shown to the user.
3. Term Ranking Algorithms
The process of PRF consists of two steps: query expansion (the addition of new terms selected from pseudo-relevant documents) and term reweighting (the modification of term weights) [27]. In the query expansion step, the term ranking algorithm is used to select the most useful terms from pseudo-relevant documents. Given a term occurring in pseudo-relevant documents, the term ranking algorithm returns a score reflecting the degree to which the term is meaningful.
To investigate the effect of the term ranking algorithm on retrieval effectiveness, we evaluated a wide range of algorithms classified as vector space models, probabilistic feedback models, or statistical models. Specifically, we performed a series of comparative analyses on eleven term ranking algorithms: total frequency (total freq), inverse document frequency (IDF), r_lohi [20], Rocchio, F4MODIFIED [18,28], expected mutual information measure (EMIM) [20], Robertson selection value (RSV) [29], Knullback-Leibler divergence (KLD) [21], CHI-squared (CHI2) [21], Doszkocs' variant of CHI-squared (CHI1) [21], and local context analysis (LCA) [23]. Table 1 describes the term scoring formulas of term t in which algorithms are grouped according to the categories of their underlying common features.
Once terms are sorted by one of the term ranking algorithms described above, either a fixed number of terms or terms above a certain threshold value are used as expansion terms. From the sorted list of terms, we selected the E highest-ranked new terms that were above a threshold of zero and added them to the original query.
4. Experimental Design
The process of PRF includes a term reweighting stage, as mentioned previously. During term reweighting, terms in the expanded query can be reweighted with or without consideration of the results of the term ranking algorithm used. Traditional methods, such as the standard Rocchio feedback formula [30] and the Robertson/Sparck-Jones weight method [26], reweight terms according to both the uniqueness of terms in the pseudo-relevance documents and the probability of terms occurring in the pseudo-relevant documents.
In this study, we evaluated the retrieval effectiveness of term ranking algorithms with different formulas for term reweighting in order to compare the algorithms fairly, considering the scores and the ranks of the terms they produced.
For reweighting terms in the expanded query, we applied five different methods, including three popular approaches and two variants. In the following definitions, the formulas for calculating the new weight w'q,t of a query term t are described, in which wq,t is the weight of the term t in the unexpanded query, and the tuning parameters are set to a default value (i.e., α = β = 1).
1) Standard Rocchio formula
A positive feedback strategy for a Rocchio formula with modified feedback [30] was applied, as follows:
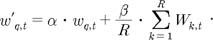
where wk,t is the weight of the term t in a pseudo-relevant document k (which equals the wd,t component of the Okapi BM25 formula).
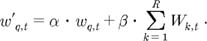
3) Variant 1
As a variant of the standard Rocchio formula, the formula to employ the sorted result of term ranking algorithms in reweighting terms was suggested by Carpineto et al. [32] because the Rocchio considers the usefulness of a term with respect to the entire collection rather than its importance with respect to the user query. For the OHSUMED test collection, we applied the Rocchio formula, as follows:
The max_norm_scoret is the normalized value assigned to term t by dividing the score of term t by the maximum score of the term ranking algorithm used. We called this a max_norm term reweighting.
4) Variant 2
The max_norm term reweighting does not accurately reflect the importance of the relative ranking orders of terms sorted by the term ranking algorithm. To understand the importance of their orders and to provide comparisons to the max_norm term reweighting, a formula to emphasize how well terms were ordered by the term ranking method used was devised by the authors, as follows:
The rank_norm_scoret is the evenly decreasing, normalized value assigned to term t according to the rank position of term t in the sorted term list and calculated by 1 - (rankt - 1) / |term_list|, where rankt is the rank position of term t and |term_list| is the number of terms in the expanded query. We call this a rank_norm term reweighting.
5) Probabilistic term reweighting
In the probabilistic feedback model, we applied a modified Robertson/Sparck-Jones weight [26], which downgrades the weight of the expansion terms to 1/3, as follows:
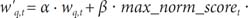
In this model, the IDF component (i.e., log((N - n + 0.5)/(n + 0.5))) of the Okapi BM25 formula is replaced with the new weight.
The performance of paired combinations of the term ranking algorithms and the term reweighting methods described above was evaluated for both a different number of pseudo-relevant documents (R parameter) and a different number of expansion terms (E parameter). We varied the values for the R parameter from 5 to 50 with a step-size of 5. For the E parameter, we varied the value from 5 to 80, also with a step-size of 5, to see how the retrieval effectiveness varied for different parameter values.
5. Evaluation Measurements
To evaluate our experimental results, we primarily used the mean average precision (MAP) as the evaluation metric for retrieval effectiveness. MAP is the mean value of the average precisions computed to multiple queries where the average precision of each query is calculated by the average of the precision values over all of the retrieved relevant documents. MAP serves as a good measure of the overall ranking accuracy, and MAP favors systems that retrieve relevant documents early in the ranking [27]. In addition, we reported the precision of the top few retrieved documents, which reflects the user's perspective.
In all of the experiments, the measures were evaluated for the 100 top-ranked retrieved documents. The significance test was performed across multiple experiments using a paired t-test, which is one of the recommended methods for evaluating retrieval experiments [33].
IV. Results
In this paper, we primarily report the experimental results for two fixed parameter values. The experimental results for the standard values of the R and E parameters (R = 10 and E = 25) and the maximum performance values of R = 50 and E = 15, where the best MAP was found for the OHSUMED test collection, were chosen for detailed analysis. In our system, the unexpanded baseline MAP was 0.2163. This baseline was used as the reference for calculating performance improvement.
1. Performance at the Default Parameters
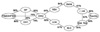
Using the standard parameter settings (R = 10, E = 25), the performance of selected term ranking algorithms over different reweighting methods was measured. The MAP and the percentage of improvement over the unexpanded queries are shown in Table 2. The significant differences in terms of the paired t-test are indicated by p < 0.01 and p < 0.05. As shown, using default parameter settings did not noticeably improve any of the term ranking methods for the OHSUMED test collection. However, it was interesting that only the CHI1, CHI2, and F4MODIFIED term ranking algorithms, which favor infrequent terms, showed a statistically significant improvement when using Rocchio term reweighting. We analyzed the overlapping ratio of expansion terms between pair-wise term ranking algorithms. Figure 1 shows the top 15 overlapping ratios, where term ranking algorithms were linked according to the ratio of overlapping terms. As can be seen in the figure, although CHI1, CHI2, F4MODIFIED, and IDF found similar terms using their term ranking algorithms, IDF did not show a significant improvement. It appears that a few unique terms, expanded by a specific term ranking algorithm, may have a significant improving effect. In addition, because the performance of term ranking algorithms was differentiated by the term reweighting algorithms applied, both term ranking and reweighting methods should be taken into account when evaluating the performance of the PRF algorithms. With the default parameter setting, it is likely that, in conjunction with Rocchio term reweighting, the term ranking algorithms that favor infrequent terms can perform better in comparison to the other term ranking algorithms.
The max_norm and rank_norm term reweighting can explain the MAP differences in both the scores and the ranks of terms produced by different term ranking algorithms, as well as in the distinct terms selected by these algorithms. By comparing the max_norm and the rank_norm term reweighting methods from Table 2, we can see that rank-based normalizations are generally better than score-based ranking algorithms. It appears that the ranked order of terms is more important than the actual scores of the terms. Therefore, we performed a t-test comparison between pair-wise term ranking algorithms using rank_norm term reweighting. The p-values are given in Table 3; only p-values lower than 0.01 and 0.05 are reported. As shown, the RSV and the LCA performed best with the rank_norm reweighting method, significantly outperforming total_freq, r_lohi and KLD. This indicates that RSV and LCA performed better than the other algorithms at ranking the most useful terms near the top of the list using the default parameter settings. Although none of the term ranking methods resulted in a statistically significant improvement when applied in conjunction with the rank_norm term reweighting (Table 2), it may be valuable to note that most of the term ranking methods performed better for the rank_norm term reweighting than for the Rocchio term reweighting.
2. Performance at the Maximum Performance Parameters
The maximum performance values of the R and E parameters were fixed at R = 50 and E = 15 because these parameter values gave the best performance improvement for the OHSUMED test collection. Table 4 shows the comparative results for the parameters, and Table 5 gives the t-test comparisons between pair-wise term ranking algorithms for the results of the rank_norm term reweighting.
A comparison of Tables 2 and 4 indicates that the LCA term ranking shows the best performance, regardless of the term reweighting algorithm applied. The performance improvement, about 12%, was achieved by LCA when the expanded query was re-weighted by rank_norm. Furthermore, for rank_norm term reweighting, LCA significantly outperformed all of the other methods (Table 5). This suggests that LCA can select more useful terms when the pseudo-relevant documents provided are large enough to infer co-occurrence of terms. Throughout our experiments, LCA consistently performed the best at automatic query expansion from the set of OHSUMED retrieved documents.
With regard to the effect of term reweighting algorithms, the performance change of precision in top retrieved documents and the performance of MAP are shown in Figure 2. As shown in the figure, when comparing the traditional term reweighting methods, such as Rocchio, Ide, and probabilistic, the methods based on the results of term ranking algorithms, such as max_norm and rank_norm, showed better improvements with fewer retrieved documents.
V. Discussion
Ranking and reweighting of terms are the main processes of PRF. The basic features to be considered for PRF algorithms are the frequency heuristic and the probabilistic and statistical analysis of the terms. Because the general characteristics of medical documents are different from the characteristics of other collections, we have attempted to evaluate the retrieval performance of ranking and reweighting method pairs for the OHSUMED collection, which is a subset of the MEDLINE documents.
In our search for the best PRF algorithm for the medical area, we examined the core effects of term ranking algorithms used for selecting expansion terms. Table 2 shows two interesting results. The first result shown is the improved performance of the CH1, CH2, and F4MODIFIED term ranking algorithms for Rocchio term reweighting using the default parameter settings. These algorithms favor infrequent terms in the collection for expansion. In addition, it is likely that a few unique terms, expanded by a specific term ranking algorithm, may significantly improve the performance. However, the effect was not consistent with all of the other reweighting algorithms, such as Ide, probabilistic, max_norm, and rank_norm.
The second interesting result is the performance of LCA using the maximum performance parameter settings (R = 50, E = 15). LCA showed consistent improvement across all of the reweighting algorithms, except for the Ide (Table 4). The LCA performance result was statistically significant compared to all other ranking algorithms. This result suggests that LCA can select more useful terms when enough pseudo-relevant documents are provided to infer co-occurrence of terms in the whole collection. Moreover, the effect was magnified as the number of included documents increased.
On average, OHSUMED contains approximately 22 documents found to be definitely relevant for each of the 101 queries. Accordingly, a large number of non-relevant documents can be included as the number of pseudo-relevant documents increases. However, despite a large number of non-relevant documents, LCA showed a notable improvement in our experiments. Our results with LCA show that term co-occurrence played a more important role compared to other features, in a medical context. Thus, the co-occurrence feature should be seriously considered in the design of clinical query systems.
The limitations of our study are that we used the outdated OHSUMED test collection because of non-availability of modern test collections for evaluating retrieval algorithms against real clinical queries and that our findings might not be generalizable to real data collections because of our adhoc experiments of only one test collection. Although further experiments should be performed in the future, out findings are important in understanding the behaviors of various term ranking and reweighting algorithms on a subset of MEDLINE documents and clinical queries.
New comparative experiments on term ranking algorithms were performed in the context of a subset of MEDLINE documents. Among the various term ranking algorithms, LCA significantly outperformed all of the other methods in our experiments when the top 15 terms obtained from 50 retrieved documents were expanded with a modified weight by a rank_norm reweighting method. With medical documents, LCA, which uses co-occurrence with all query terms, significantly outperformed various term ranking methods based on both frequency and distribution analyses. To maximize the performance improvement even further, the weight of the terms in the expanded query should be appropriately adjusted. Furthermore, the results of the experiments demonstrate that the term rank-based reweighting method contributed to a remarkable improvement in mean average precision.






 XML Download
XML Download