

 PDF
PDF ePub
ePub Citation
Citation Print
Print


The genomic information of primary laboratory animals such as mouse and rat was revealed in the genome project [1,2]. On the basis of those gene constructions in the genome, various gene families were identified for the study of gene function contributing to the scientific needs.
The calcium-activated chloride channel (CaCC) family has been summarized as a group of anion channels that are activated by release of calcium from the endoplasmic reticulum (ER) [3,4]. The CaCC family has at least two types of chloride channels: TMEM16 channels [5-7] and chloride channels calcium-activated (CLCA). Even though this family show a common characteristic of being activated by release of calcium from the ER, there is little genetic and molecular similarity between the two CaCC families [3,4].
Recently, two different CaCCs, xTMEM16A and xANO2, were cloned as Xenopus laevis (X. laevis) CaCCs [8,9]. These two TMEM16 channels, also called anoctamin, have very significant molecular and physiological characteristics. In our research of anoctamin, tissue distribution analysis revealed a ubiquitous expression pattern in various X. laevis tissues including intestines [9].
With a focus on function, calcium-activated chloride channels (CLCAs) have been studied in a number of species including bovine [10], murine [11,12], human [13], and porcine [14]. We reported two CLCAs isolated from one laboratory animal, Ratus norvegicus [15,16]. These rbCLCA1 and rbCLCA2 channels have common characteristics such as primary molecular structure and expression profiles.
As mentioned above, CLCAs from various animal species and tissues have been studied except X. laevis. Moreover, most of the studies were more likely to focus on diseases or functions of humans, and the molecular characterization of the channels tended to be neglected. Here we report a putative CLCA-like membrane protein 6 gene (CMP6) in X. laevis on the basis of its primary molecular structure and tissue distribution profiles.
Materials and Methods
Materials
Chemical reagents were purchased from BioPure (Burlington, Ontario, Canada). pGEM®-T Easy vector was from Promega (Madison, WI, USA). A peltier thermal cycler PTC-200 cycler was purchased from BIO-RAD (Hercules, CA, USA). Female X. laevis (Xenopus I, Ann Arbor, MI, USA) frog was kindly provided by Dr. S.Y. Nah (Konkuk University, Seoul, Korea).
Database search on X. laevis expressed sequence tags (EST) and analysis
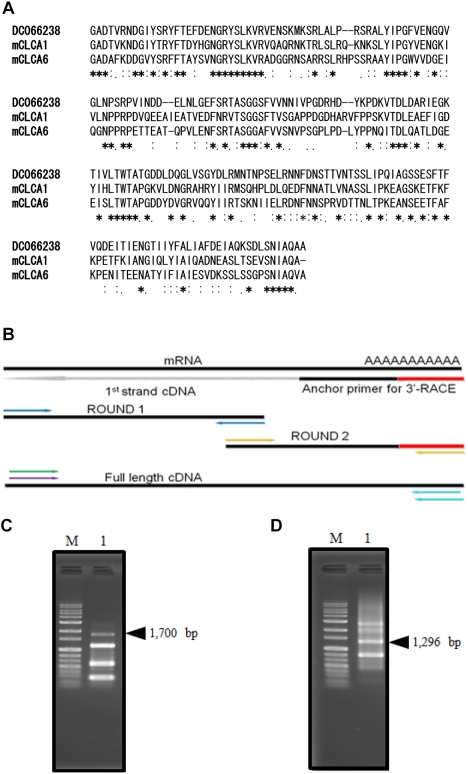
An EST database search was conducted on X. laevis to find out whether there are any partial cDNAs that show high homology with mouse CLCA sequences. First, BLAST server on NCBI was utilized as a search tool to find the X. laevis EST partial cDNA sequence. Highly homologous partial cDNAs were found from EST clones, and among them, a partial cDNA showing 50% nucleotide homology was selected. The amino acid sequence indicated that the sequence was aligned and we compared it to mouse CLCAs (Figure 1A). The amino acid sequence exceeding 45% homology was extracted from a protein database and the intermediate results confirmed that the sequences were significant enough to proceed to the next step. Sequences showing too high or too low homology were not considered candidate sequences and were excluded. Finally, a partial cDNA was selected as a candidate for cloning.
The screening of Xenopus EST database in the NCBI was conducted to query the target sequence. To search for partial cDNAs as candidates for cloning, a partial cDNA (DC066238) was screened. DC066238 cDNA was utilized to generate gene specific primers including C218 for completion of the whole cDNA sequence (Table 1).
RNA preparation
Total RNAs were extracted from X. laevis tissues with easy-BLUE (iNtRON Biotechnology, Seongnam, Korea) according to the user's manual with some modifications. To avoid genomic DNA contamination, the extracted total RNA samples were digested with RNase free DNase I (Invitrogen, San Diego, CA, USA) prior to use.
First strand cDNA synthesis and rapid amplification of cDNA ends (RACE)
Reverse transcription reactions were performed with 10 µg of total RNA using gene specific primers (10 pmol/µL) and dNTPs. To anneal the RNA and the primers, RNA was heat denatured at 65℃ for 5 min as a conditioning of the RNA-primer mixture. The reaction mixture was as follows: nuclease-free water, 100 mM DTT, RNase inhibitor, and Superscript III RTase, The mixture was incubated at 50℃ for 30 min and at 55℃ for 30 min, and RNA was destroyed by a final concentration of 0.5 M sodium hydroxide. After ethanol precipitation with one-tenth volume of sodium acetate, the reaction product was resuspended in 20 µL of nuclease-free water for 3'-RACE. 5' kination of the cDNA and linker-attachment for the 5'-RACE were performed for effective construction. After all the steps, Purification was done using Sephacryl® S-400 to remove the excessive oligoprimers.
The 5'- and 3'-RACE methods were employed with gene specific primers and an oligo-d(T). These two rounds of RACE reactions were repeated for the amplification of full-length cDNA as shown in Figure 1B. Table 1 represents primer sets used on completion of the two rounds of RACE and construction of a subcloning plasmid. To avoid any match errors of the PCR and RACE reaction, KOD-Plus Taq polymerase (Toyobo, Osaka, Japan) was used through amplification of cDNA. Reaction conditions were as follows: 94℃ for 2 min, 30 cycles of 94℃ for 30 sec, 60℃ for 30 sec, and 68℃ for 1-3 min for the first PCR; for the second PCR, 94℃ for 2 min, 30 cycles of 94℃ for 30 sec, 60℃ for 30 sec, and 68℃ for 1-3 min.
Full-length cDNA construction
After the two rounds of RACE, Round 1 and Round 2 sub-clones were connected by a recombinant PCR method. Two amplified cDNAs of the 5' and 3' terminuses were used as the overlapping templates together with each piece of DNA to complete a full-length cDNA. C407, C409, and C408 primers were designed from the 5'- and 3'-UTRs. These primer sets for the final step of the recombinant PCR were used for the amplification of full-length cDNA. All these primers are summarized in Table 1. To clone the full-length cDNA, a recombinant PCR product was inserted into a pGEM®-T Easy subcloning vector (Promega). The CMP6 cDNA was confirmed by sequence analysis. For sequence analysis, each cDNA obtained from RACE was tailed with poly-A, ligated with the above vector, and transformed with E. coli DH5α strain. Sequence determination was performed using an ABI PRISM system, and homology alignment and analysis were conducted on an NCBI-BLAST server.
Tissue distribution analysis by RT-PCR
To perform RT-PCR, first cDNA was synthesized from RNA as described in Materials and Methods. Two rounds of PCR were carried out for the 45 repeats to determine the specific products of CMP6. These procedures were carried out in a Peltier thermal cycler PTC-200. For semi-quantification of PCR, nine tissue RNAs (brain, heart, lung, liver, small intestine, colon, kidney, spleen, and oocytes) were employed. In this RT-PCR, i-StarTaq™ polymerase (iNtRON Biotechnology) was used for the stable and fine amplification from nine X. laevis tissue-derived cDNAs with gene specific primers on a Peltier thermal cycler PTC 200. The PCR reaction was performed as follows: pre-denaturation step at 94℃ for 1 min, 20 repeats of denaturation step at 94℃ for 15 sec, annealing at 55℃ for 20 sec, extension at 72℃ for 20℃sec, and for second PCR, 94 for 1 min, 25 repeats of 94℃ for 15 sec, 57℃ for 20 sec, 72℃ for 1 min. Excess primers were removed by Sephacryl® S-400 column chromatography after the first PCR.
Quantitative real-time PCR
To provide a CMP6 quantification result, real-time PCR was performed to confirm whether any difference between RT-PCR and real-time PCR existed. In order to maintain consistency, nine PCR products from reverse-transcription PCR derived from nine same cDNAs were used in the next experiment. A CHROMO4™ (BIO-RAD) real-time PCR system was employed for analysis. DyNAmo™ ColorFlash® SYBR Green qPCR kit (Finnzymes Oy, Espoo, Finland) was utilized with the following steps: pre-denaturation at 95℃ for 7 min, 35 repeats of the denaturation step at 95℃ for 10 sec, at 60℃ for 20 sec, at 72℃ for 20 sec, a final elongation step at 72℃ for 7 min, and establishment of a melting curve from 65 to 90℃. Expression levels were calculated using GeneXpression Macro CHROMO4™ from an Opticon4 program provided by the supplier.
Results
Selection of the target cDNA sequence
The selected partial cDNA, DC066238, has a 630 bp nucleotide sequence. One ORF codes for a 210 amino acid sequence. This cDNA was screened by comparison of its homology to mouse CLCA1 and CLCA6 which showed over a 48% amino acid similarity (Figure 1A). As a first step in gene cloning, DC066238 was utilized for primer design to clone the CMP6 as described in Materials and Methods.
CMP6 gene cloning
To complete the full-length CMP6 cDNA, each cDNA, a 1,700 bp linker-C218 (5'-RACE) and a 1,296 bp C401-adapter (3'-RACE) were amplified as described in Materials and Methods (Figure 1B, C, D). It was confirmed that CMP6 had no base changes or missed sequences over the whole region (data not shown). As a result, we have successfully isolated full-length X. laevis CMP6 cDNA including a 2,940 bp sequence with one ORF of 940 amino acids. We did this using several repeats of the 3'- and 5'-RACE method and the specific primers as described in Materials and Methods. The completed CMP6 cDNA contained a short 5'- and a 3'-UTR with a poly (A)n tail and a poly-adenylation signal. We registered this cDNA as a CMP6 gene on the DDBJ database (GenBank Accession No. AB591378).
Analysis of primary structure
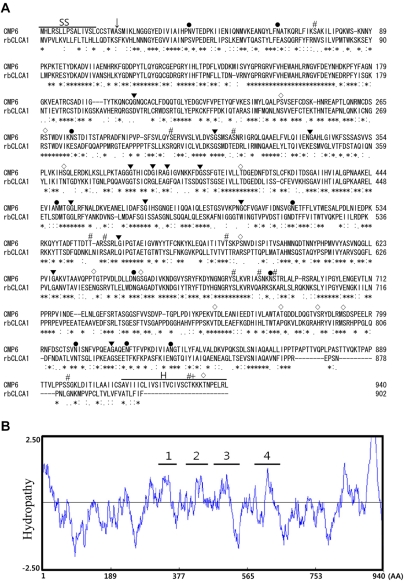
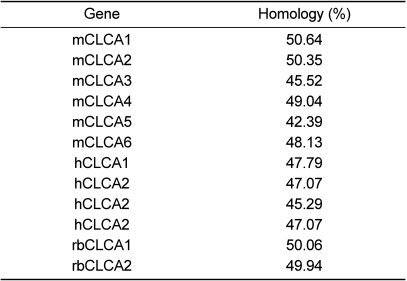
The sequence analysis of the CMP6 gene revealed short 5'- and 3'-UTRs and a single large ORF. The CMP6 protein, including 940 amino acids, was aligned by CLUSTAL W software. The rat CLCAs and CMP6 were compared whether or not it had significant homology or was considered as a CLCA gene family member. The ORF of X. laevis CMP6 showed identity exceeding 50% overall to those of rbCLCA1 (Figure 2A and Table 2). According to this alignment, the overall significant homology that was exhibited led us to regard it as a new Xenopus CLCA-like member (Table 2).
It has been reported that the general CLCAs have four or five transmembrane (TM) domains [17]. Although there are limitations when the actual protein conformation analysis is absent, computational analysis using an appropriate program makes it possible to analyze and predict the conformation of certain protein structures. The hydropathy analysis of CMP6 (Kyte-Doolittle method) indicates that there exist at least four predicted TM domains as shown in Figure 2B. According to hydropathy analysis, we were able to propose that CMP6 is a highly homologous CLCA family member.
To determine the unique characteristics of the CLCA family, the predicted consensus sites were searched for on a GENETYX program. We found the major characteristics of the CLCA family such as the sites of N-linked glycosylation, N-myristoylation, phosphorylation by PKC, casein kinase II and cAMP-dependent protein kinase (Figure 2A). Also, there was a predicted signal sequence and a hydrophobic carboxyl terminus that was regarded as a typical membrane protein including CLCA.
Quantitative analysis of CMP6
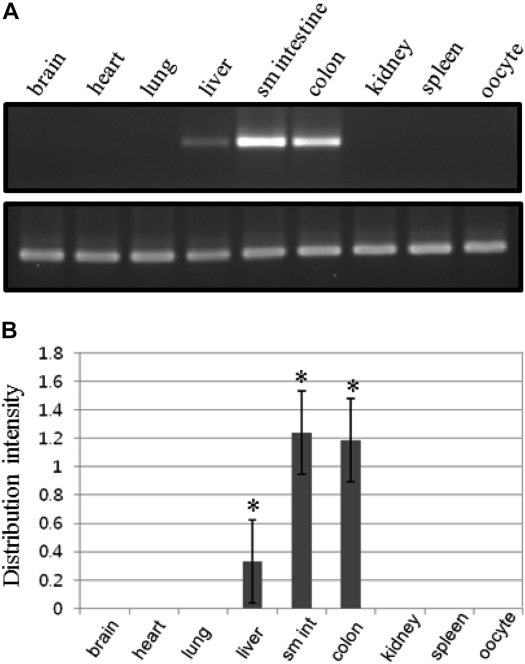
In tissue distribution analysis, the amplified PCR products were detected in some tissues. In particular, we could detect CMP6 gene products, which were expressed predominantly in small intestine, colon and liver (Figure 3). The gene-specific products of CMP6, and β-actin as an internal control, were shown to be 252 and 159 bp (Figure 3A). The intensity of each product was calculated using the E-Capt program for normalization. Relative ratios of CMP6 expression levels in each tissue were calculated compared to the housekeeping gene β-actin (Figure 3B). Each RT-PCR was conducted at least three times to insure the reliability of the numerical values. As shown in Figures 3A and 3B, expression levels were different with small intestine>colon>liver. However, triple repeats of experiments showed that the probability of liver expression is very low (no more than one out of four times; data not shown). In summary, the expression of CMP6 is distinct and specified within the gastrointestinal tract. This suggests that CMP6 expression patterns are limited to secretory functions.
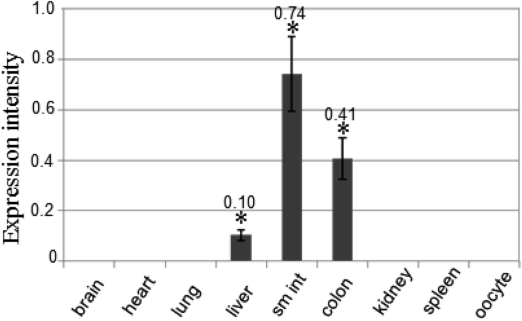
In order to validate data from semi-quantification RT-PCR analysis, quantitative real-time PCR analysis was conducted as described in Materials and Methods. The exponential graph of nine tissues was obtained as the amplification time for expression intensity (data not shown). Figure 4 shows a bar graph that was converted from the exponential graph using numerical values for each product. Expression levels were: small intestine>colon>liver. It also showed that heart was amplified a little (data not shown). The real-time PCR data are completely consistent with the RT-PCR data (Figure 4).
Discussion
Since there were no reports about the CLCA gene family of X. laevis, we studied X. laevis CLCA gene family members. After two rounds of RACE, linker-C218 constructs were first cloned from X. laevis spleen. However, we could not isolate the exact match of the C218 sequence in spleen tissue. Moreover, there were subtle changes in amino acid sequences. Paradoxically, this kind of difficulty in an experiment suggests the possibility of the existence of a new CLCA gene. Hence, we are now screening for more CLCA members in X. laevis.
In this study, a 2,940 bp cDNA of CMP6 was successfully cloned from X. laevis (Figure 1). As mentioned above, it has been reported that two bovine CLCAs, and five or more murine and human homologs were isolated, but not from X. laevis. Also, two rat brain CLCAs showed lengths around 2,800 bp [15,16]. As regards animal CLCAs, it is meaningful to identify CLCA genes in unstudied animal species. Under homology-based conditions, we can propose that CMP6 may be a functional CLCA. This cDNA was similar to the rat CLCA sequences showing 56% homology for the nucleotide sequence, and a 50% homology for the amino acid sequence [15,16]. There was a low 21% similarity in the restricted partial region of xANO2 [9]. CMP6 shows the most homology (over 50%) to mice CLCA1 and rbCLCA1 (Table 2). Although mouse CLCA1 (mCLCA1) has the highest homology to CMP6, at least if similarities are limited to percentages, rbCLCA1 showed the most homology spanning the overall primary structure (data not shown).
The primary structure of CMP6 revealed four major potential TM domains and, in hydropathy analysis using an analysis window of 17 residues, several minor regions (Figure 2B). As has been proposed for hCLCA1 or hCLCA2, many CLCA family members have four or five TM domains [4]. This analysis is consistent with typical CLCA membrane proteins. On the contrary, two X. laevis anoctamins, xTMEM16A and xANO2, have eight distinct TM domains compared to four TM domains for the CLCA family. These results support the low amino acid sequence homology between CLCAs and anoctamins.
Loewen et al. divided the CLCA gene family into two groups. The first group includes hCLCA1, mCLCA3, and pCLCA1. The second group contains two subgroups - one that contains mCLCA1, mCLCA2, and mCLCA4, and a second that contains hCLCA3, bCLCA1, and bCLCA2 [17]. Evans SR et al. reported two mouse CLCA genes with mCLCA6 expressed primarily in intestine, stomach and in liver a little, whereas mCLCA5 is widely expressed with particularly strong expression in eye and spleen [12]. CMP6 was expressed specifically in intestine (and in liver a little) in contrast to rat CLCAs which were predominantly expressed in brain [15,16].
Moreover, there were similar molecular characteristics regarding the far carboxyl terminus (C-terminus) of the primary structures between CMP6, and mCLCA6 and mCLCA4. This was in contrast to other CLCAs that had no similarity with the C-terminus of CMP6. The C-terminus of CMP6 was most similar to that of mCLCA6 whereas mCLCA4 was less similar (data not shown). Even though we have no evidence for a relation between function and similarities at the C-terminus, we can assume that CMP6 is key in the gastrointestinal tract, especially mucus production. This type of CLCA-like protein might be involved in the regulation of chloride conductance in epithelium with secretory functions. For a more defined study in the future, further work will be needed using heterologous expression analyses.

 XML Download
XML Download