

 PDF
PDF ePub
ePub Citation
Citation Print
Print


Abstract
Objective:
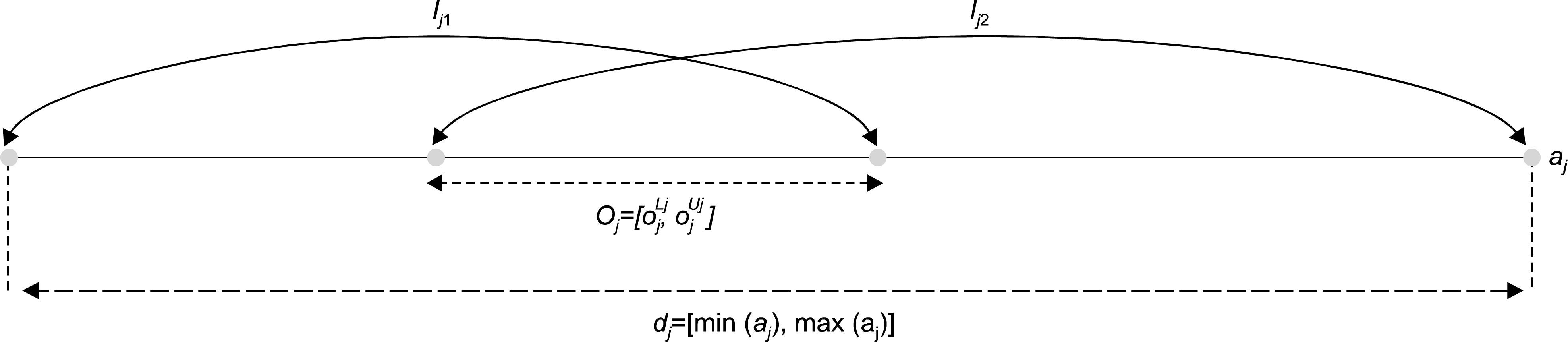
In processing high dimensional clinical data, choosing the optimal subset of features is important, not only for reduce the computational complexity but also to improve the value of the model constructed from the given data. This study proposes an efficient feature selection method with a variable threshold. Methods: In the proposed method, the spatial distribution of labeled data, which has non-redundant attribute values in the overlapping regions, was used to evaluate the degree of intra-class separation, and the weighted average of the redundant attribute values were used to select the cut-off value of each feature.
REFERENCES
1. Jeven P, Ewens B. Assessment of a breathless patient. Nursing. 2001; 15(16):48–55.
2. Blum AL, Langley P. Selection of relevant features and examples in machine learning. Artificial Intelligence. 1997; 97(2):245–271.

3. Kohavi R, John GH. Wrappers for feature subset selection. Artificial Intelligence. 1997; 92(2):273–324.
4. Dash M, Liu H, Yao J. Dimensionality reduction of unsupervised data. ICTAI, 9th Int Conf. Tools with Artificial Intelligence (ICTAI ‘97). 1997; 532–539.
5. Steppe JM, Bauer KW, Rogers SK. Integrated feature and architecture selection. IEEE Trans. Neural Networks. 1996; 7(4):1007–1014.
6. De RK, Pal NR, Pal SK. Feature analysis: neural network and fuzzy set theoretic approaches. Pattern Recognition. 1997; 30(10):1579–1590.
7. Li RP, Mukaidono M, Turksen IB. A fuzzy neural network for pattern classification and feature selection. Fuzzy Sets and Systems. 2002; 130(1):101–108.
8. Yang J, Honavar V. Feature subset selection using a genetic algorithm. IEEE Intelligent Systems. 1998; 13(2):44–49.
9. Vafaie H, Jong D. Feature space transformation using genetic algorithm. IEEE Trans. Intelligent Systems. 1998; 13(2):57–65.
10. Tseng LY, Yang SB. Genetic algorithms for clustering, feature selection and classification. Proc IEEE Int Conf Neural Networks. 1997; 3:1612–1615.
11. Elalami ME. A filter model for feature subset selection based on genetic algorithm. Knowledge-Based Systems. 2009; 22(5):356–362.
12. Quinlan JR. C4.5: programs for machine learning. San Mateo: Morgan Kaufmann;1993. p. 109–279.
13. Cover TM, Hart PE. Nearest neighbor pattern classification. IEEE Trans. Information Theory. 1967; 13(1):21–27.
14. Fisher RA. The use of multiple measurements in taxonomic problems. Annals of Eugenics. 1936; 7:179–188.
15. Friedman JH. Regularized discriminant analysis. J American Statistical Association. 1989; 84(405):165–175.
16. Cortes C, Vapnik V. Support-vector networks. Machine Learning. 1995; 20(3):273–297.
| αj | 1.0 | 1.1 | 1.2 | 1.3 | 1.4 | 1.5 | 1.8 | 1.7 | 1.8 |
|---|---|---|---|---|---|---|---|---|---|
| t1j | 1 | 2 | 1 | 1 | 2 | 2 | 0 | 0 | 0 |
| t2j | 0 | 1 | 0 | 2 | 1 | 0 | 1 | 2 | 1 |
| h1j | 1/20 | 0 | 1/20 | 0 | 0 | 2/20 | 0 | 0 | 0 |
| h2j | 0 | 0 | 0 | 00 | 0 | 0 | 1/20 | 2/20 | 1/20 |
Table 1.
Dataset’s feature
| Feature* | Unit | Min | Max | Mean±SD |
|---|---|---|---|---|
| WBC | ×103/µl | 0.11 | 75.9 | 11.0196±6.3942 |
| PLT | ×103/µl | 23 | 1,105 | 270.6856±120.0240 |
| Cl– | mmol/L | 72 | 134 | 104.2455±6.9351 |
| AST | U/L | 5 | 3,321 | 73.5195±227.1527 |
| ALT | U/L | 3 | 2,481 | 46.4416±143.2200 |
| PCO2 | mmHg | 8.3 | 98.5 | 39.8760±13.5689 |
| PO2 | mmHg | 35.9 | 354 | 80.1507±22.0636 |
| O2SAT | % | 59 | 99.9 | 96.1350±3.1972 |
| LDH | U/L | 152 | 8,178 | 688.5834±509.8108 |
| Ca2+ | mEq/L | 1.25 | 3.2 | 2.2451±0.1706 |
| Mg2+ | mg/dl | 0.3 | 4.1 | 2.2054±0.3770 |
Table 2.
Classification accuracy and selected features when the threshold (α =0.1)
Table 3.
Classification accuracy and selected features when the threshold (α =0.2)
Table 4.
Classification accuracy and selected features when the threshold (α =0.6)
| Selected feature | Cut-off | Fitness | Num. rules in admission | Num. rules in discharge | Num. total | Accuracy (%) |
|---|---|---|---|---|---|---|
| WBC | 9.0914 | 0.8114 | 8 | 0 | 8 | 74.8503 |
| LDH | 550.0329 | 0.7320 | ||||
| PO2 | 80.4923 | 0.6751 |
Table 5.
Classification accuracy and selected features when the threshold (α =0.7)
| Selected feature | Cut-off | Fitness | Num. rules in admission | Num. rules in discharge | Num. total | Accuracy (%) |
|---|---|---|---|---|---|---|
| WBC | 9.0914 | 0.8114 | 4 | 0 | 4 | 74.8503 |
| LDH | 550.0329 | 0.7320 |
Table 6.
Classification accuracy and selected features when the threshold (α =0.8)
| Selected feature | Cut-off | Fitness | Num. rules in admission | Num. rules in discharge | Num. total | Accuracy (%) |
|---|---|---|---|---|---|---|
| WBC | 9.0914 | 0.8114 | 2 | 0 | 2 | 74.8503 |
Table 7.
Results of 10-fold cross validation when the threshold (α =0.5)
Table 8.
Comparison results between the proposed method and the conventional methods (10-fold cross validation)
| Method | Avg. train (%) | Avg. test (%) | |
|---|---|---|---|
| Decision tree* | C4.5 | 78.0433 | 70.9408 |
| Statistical classifiers† | kNN (k=1) | 68.4959 | 68.7065 |
| kNN (k=2) | 73.6860 | 73.3492 | |
| kNN (k=3) | 70.1428 | 69.3012 | |
| LDA | 74.6507 | 74.5545 | |
| QDA | 48.5199 | 45.9362 | |
| SVMs‡ | Polynomial | 25.1497 | 25.1470 |
| Sigmoid | 74.8503 | 74.8530 | |
| RBF | 100 | 74.8530 | |
| Proposed method | α =0.5 | 74.4680 | 74.5545 |
 XML Download
XML Download