

 PDF
PDF ePub
ePub Citation
Citation Print
Print


INTRODUCTION
In a cohort study, it is essential to balance the following up of the selected exposed group and nonexposed group. The major source of bias that occurs during the measurement of outcome may occur from inadequate means of obtaining information regarding exposures and/or disease outcome. In other words, if there is a difference in the completeness of case-ascertainment between the two groups depending on the exposure, for instance, a surveillance bias in which disease ascertainment may be better in the monitored group than in the general population- an ascertainment bias-, the incidence or other outcome variables that result from the study-the relative risk or odds ratio-become incredible (1, 2).
Various data sources are used in detecting the occurrence of target disease. They can be categorized into either active or passive follow-ups. Passive follow-up is to achieve data collected and maintained by organizations outside the study for other purposes, and the examples would be cancer registry, death certificate data, health insurance data, etc. Active follow-up requires direct contact with the cohort participants by mailings, phone calls, interviews, etc. Collecting certain types of information using standardized case report forms from hospital records that were not originally purposed for ascertaining outcomes could also be considered as active follow-ups. However, no one data source or combinations of multiple data sources render a full detection of the cases, due to the cases that are missed in each data sources. Thus, various methods have been developed to supplement in estimating the accurate incidence of disease, one being capture-recapture method. Originally developed for counting fisheries and wildlife animals, capture-recapture method has later been employed in many epidemiologic researches to estimate the unobserved cases and evaluate the completeness of data from various incomplete data sources. Yet, application of the capture-recapture method requires several assumptions that can be elusive in real life epidemiologic studies that may be overcome by the use some mathematical models, and an example would be the log-linear model (3).
The purpose of this study was first, to estimate the completeness of cancer cases in Korea Radiation Effect and Epidemiology Cohort (KREEC) during the follow-up period of 2004 to 2007, using cancer registry data, death certificate data and medical records obtained actively from hospitals, and secondly to evaluate whether there is a difference between the completeness of case ascertainment between the exposed group and the nonexposed group during the period.
MATERIALS AND METHODS
Study population
KREEC study has been initiated in 1992 to scientifically evaluate the health effects of radiation emitted from the nuclear power plants in Yeong Gwang, Korea, on the residents who res ide near the plants. Exposed group was composed of workers at the power plants and residents living within 5 km radius, and the nonexposed group was set at two different levels - intermediate-distance group of residents living 5-30 km away from the power plants, and far-distance group of residents living more than 30 km away from the power plants. Upon selecting members based on strict criteria, the follow-ups had been conducted by three different methods since 1993 (Fig. 1). Cancer registry data, death certificate data and medical records from the participating hospitals were used to detect cancer cases defined as C00-D09 of International Classification of Diseases-10 (ICD-10). Active check-ups of medical records were performed in those who have been identified suspicious of having cancer - all cases having C00-D09 codes, and randomly selected cases with other codes from the National Medical Claims Data. Medical doctors have reviewed the structured abstracts to evaluate the cancer cases, constructed from medical records by trained interviewers, including diagnosis of date, diagnostic measures and interpretation of the results, stage of cancer, treatment, etc.
Case definition
A cancer case was defined as having a cancer diagnosis through biopsy, cytology, CT/MRI, and other imaging procedures in medical records data. The date of cancer diagnosis was regarded as the incident date. Cancer code and date were also identified either from Korea Central Cancer Registry (KCCR) or death certificate data, whichever the cancer diagnosis date was earlier. The analysis of the study was conducted using data from year 2004-2007, since the cancer cases before year 2004 is thought to be complete for both the exposed and nonexposed groups, and some of the cases might include prevalent cancer cases. Finally, the subjects in included were 11,367 near residents (supposedly exposed group) and 24,809 intermediate and far residents (supposedly nonexposed group).
Statistical analysis
To compare the estimated number of cancer cases in different models, two-source capture-recapture analysis was conducted, in which cancer registry data vs death certificate data, death certificate data vs medical records data, and medical records data vs cancer registry data are used. Assuming the dependence of each data sources, maximum likelihood estimator (MLE) was used for each of the comparing two sources to estimate the complete number of cases and its confidence interval, and indirectly evaluate the dependency between the sources (4).
The unobserved 'H' in Fig. 1 can be estimated using log-linear models in three-source model. In order to use the log-linear model, several assumptions should be met, including the independence between the data sources. To resolve the independence, interaction terms were added in the models for examining and adjusting dependency (3).
Finally, estimated number of cases was compared to the observed cases to evaluate the completeness of case-ascertainment during the follow-up in KREEC study, as the completeness is defined as the proportion of the number of cases detected to the number of estimated cases during the follow-up.
RESULTS
Cancer cases ascertained by each data sources
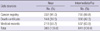
Table 1 shows detected cancer cases in three different data sources. A total of 332 cancer cases were detected in cancer registry data, 144 cases in death certificate data, and 218 cases were confirmed through medical records in near residents. In intermediate/far residents, 755 cases, 356 cases and 537 cases were detected respectively for each data sources. Considering the cases that were found in multiple sources, a total of 365 cases of 11,367 near residents (3.2%), and a total of 841 cases out of 24,809 intermediate/far residents (3.4%) were identified through cancer registry, death certificate and medical records data.
Fig. 2 shows more specified number of cases detected in three different data sources for each area. The numbers of cases are missing for values that are detected in none of the data sources for both near residents and intermediate/far residents.
Comparison of number of cancer cases from each data sources
The incident rates identified in each data sources are shown in Table 2. Chi-square test for heterogeneity among three sources was not significant (P > 0.05) between near residents and intermediate/far residents demonstrating no statistically significant difference between exposed group and the nonexposed group in the cohort.
Estimation of cancer cases using two-source method
Table 3 is a result of calculated estimation of cancer cases from two-source data sources. Results from data that are matched to cancer registry (cancer registry vs death certificate and medical record vs cancer registry) rendered little difference between the observed number and the estimated number of cancer cases, whereas values from death certificate vs medical records data produced the estimated numbers of cases ranging from 1.0 to 1.6 times the number of observed cases. The data from the three different combinations of data sources were not significantly different between near residents and intermediate/far residents.
Model fitting using log-linear models
Table 4 illustrates the results of statistical significance of each data sources in three-source log-linear models. Adding interaction term decreased the scaled deviance. However the final model that was found to be most fitted was the one that included no interaction terms. This model demonstrates that there was no dependence between any of the data sources. According to the model selected in Table 4, the estimated numbers of cancer cases were 376.6 in near residents and 865.8 in intermediate/far residents as shown in Table 5.
Completeness of case ascertainment in exposed and nonexposed groups
Finally the completeness of case-ascertainment was considered between the exposed group (near residents) and the nonexposed group (intermediate/far residents). The completeness of case-ascertainment was calculated as the percentage of observed number of cases out of estimated number of cases in each group in Table 6. The completeness of cancer registry data was approximately 88% in cancer registry data, 60% in medical records data, and 40% in death certificate data. However, the completeness of each data sources between the two groups had shown no statistical difference (P = 0.72) in a chi-square test. Likewise, the completeness calculated in all three sources combined rendered 96.9% in exposed group and 97.1% in nonexposed group with no statistically significant difference (P = 0.84). In conclusion, there was no statistical difference in the completeness of cancer case-ascertainment between the exposed and the nonexposed groups during the follow-up of the cohort study.
DISCUSSION
Completeness of incidence in cancer registries can be achieved using various available methods, such as death certificate cases (DNC) method, mortality/incidence ratio, historical comparison, Bullard method, etc (5, 6). In this study, we have used capture-recapture method to estimate the completeness of cancer case ascertainment and to finally evaluate whether the completeness differed between exposed and nonexposed groups in the Korea Radiation Effect and Epidemiology Cohort, and showed that the completeness of the three data sources were not statistically different between near resident (exposed group) and intermediate/far resident (nonexposed group) (Table 6). Despite some of its limitations, capture-recapture method in estimating the completeness in diseases has been widely used in the field of epidemiology (3, 7-10). The advantages and disadvantages in using capture-recapture method to estimate cancer cases in cohorts, using three sources-cancer registry, death certificate, and medical records in Korea-is well explained in a study performed in the Seoul Male Cohort Study (11).
Nonetheless, whatever the method, the estimated completeness do not reach 100%, as seen in the results of this study, but if the follow-up period is long enough the completeness should eventually approximate 100%. Thus, the data before year 2004 in the cohort were excluded, since case-ascertainment during the period was thought to be complete and was no longer subject to evaluation. Subjects who were suspicious of having cancer - those having C or D codes in medical claims data - and some randomly selected individuals with other codes during 2004 and 2007 were reviewed for medical records. In reality, not all members of a cohort study can be actively followed-up, which is the most accurate method in validating a case, due to immense cost and effort required, most cohort studies adopt passive surveillance system to supplement the completeness of follow-up (12). Likewise, this study has also used cancer registry and death certificate data to identify those who could have been missed as cases due to various reasons.
Consequently, completeness of case-ascertainment is critical in the evaluation of the results and the completeness must be guaranteed to be identical in both exposed and nonexposed groups. Hence, before analyzing relative risks or odds ratios, it is mandatory to first consider the validity of completeness in the ascertainment of cases in the following-up of a cohort study. Several studies in Korea have evaluated the completeness of case ascertainment using capture-recapture method, but they were limited to the analysis of completeness of the entire study population (11, 13-15). Likewise, in various cohort studies in Korea, which have used nested case-control study for analysis, researchers have disregarded or have omitted to mention to evaluate the validity of completeness of case-ascertainment in exposed and nonexposed groups before selecting case and control groups, therefore prone to selection bias (7, 16, 17).
In this study the completeness of each data source has ranged from as low as approximately 38.2% to as high as 88.2% (Table 6). Completeness of cancer registry data was highest in both near residents and intermediate/far residents. Compared to the previous study using three-source capture-recapture method performed with the registry data of 1993-1995, the completeness of cancer registry is higher in this study (87%-88% vs 67%), perhaps due to the actual improvement of detection and/or reporting rate (11). Low completeness of 38.2%-41.1% estimated with death certificate may owe to the use of only 4 yr of the data, from 2004 through 2007. The completeness of three-source method-applied estimate of 99.5% is similar to the number of 94.6%, the estimated number of nationwide cancer incidence by the Ajiki method calculated for the years 2003-2005 (18).
The missed cases, i.e. the "H" from Fig. 1 are speculated to be cancer cases that are not detected by the three sources used in the study due to several reasons. One reason being that these cases are actually patients who are at "before diagnosis status" because they have not visited the hospital yet, or have died due to reasons other than cancer. Another possible scenario would be cancer cases that are diagnosed elsewhere, hospitals that are not registered for the Central Cancer Registry system, or at hospitals abroad.
The result of this study has suggested that there was no statistically significant difference between the exposed and nonexposed groups in the ascertainment of cancer. An important consideration in using the capture-recapture method in epidemiologic data is that most often data sources are not independent. These positive dependencies which may underestimate true number of missed cases were compensated through log-linear models with three data sources. Furthermore, the three data sources are nationwide databases based on the resident registration number, so that migration out of the area does not mean loss from follow-up. Nonetheless, although the numbers for individual group (exposed and nonexposed) were thought to be estimated without bias, careful interpretation is needed in comparing the two estimated values. That is even if there is no heterogeneity between the two groups, there still remains a chance that within the groups the probability of being caught might differ. With regard to biologic considerations, exposed or nonexposed groups can over-report or under-report their conditions. However, since the purpose of this study aimed at examining the catchability between the two groups, this is not much of a consideration.
In evaluating the association between the exposure and the outcome in a prospective study, the fundamental assumption to be qualified is that there should not be a difference in ascertaining the cases between the exposure groups. The result of our study showed that the completeness of data sources derived from observed number of cases over estimated number of cases by capture-recapture method were 96.9% in the exposed group (near residents) and 97.1% in the nonexposed group (intermediate/far residents), which were not significantly different. This result also adds credibility to the outcomes of the KREEC study, as well as confirming the incident cases in the two groups.







 XML Download
XML Download