

 PDF
PDF ePub
ePub Citation
Citation Print
Print


Abstract
Recently, next generation sequencing (NGS) has received attention as the ultimate genotyping method to overcome the limitations of capillary electrophoresis (CE)-based short tandem repeat (STR) analysis, such as the limited number of STR loci that can be measured simultaneously using fluorescent-labeled primers and the maximum size of STR amplicons. In this study, we analyzed 15 autosomal STR markers via the NGS method and evaluated their effectiveness in STR analysis. Using male and female standard DNA as single-sources and their 1:1 mixture, we sequentially generated sample amplicons by the multiplex polymerase chain reaction (PCR) method, constructed DNA libraries by ligation of adapters with a multiplex identifier (MID), and sequenced DNA using the Roche GS Junior Platform. Sequencing data for each sample were analyzed via alignment with pre-built reference sequences. Most STR alleles could be determined by applying a coverage threshold of 20% for the two single-sources and 10% for the 1:1 mixture. The structure of the STR in each allele was accurately determined by examining the sequences of the target STR region. The mixture ratio of the mixed sample was estimated by analyzing the coverage ratios between assigned alleles at each locus and the reference/variant ratios from the observed sequence variations. In conclusion, the experimental method used in this study allowed the successful generation of NGS data. In addition, the NGS data analysis protocol enables accurate STR allele call and repeat structure determination at each locus. Therefore, this approach using the NGS system will be helpful to interpret and analysis the STR profiles from singe-source and even mixed samples in forensic investigation.
REFERENCES
1. Thompson R, Zoppis S, McCord B. An overview of DNA typing methods for human identification: past, present, and future. Methods Mol Biol. 2012; 830:3–16.

2. Kayser M, de Knijff P. Improving human forensics through advances in genetics, genomics and molecular biology. Nat Rev Genet. 2011; 12:179–92.
3. Berglund EC, Kiialainen A, Syva ¨nen AC. Next-generation sequencing technologies and applications for human genetic history and forensics. Investig Genet. 2011; 2:23.
4. Metzker ML. Sequencing technologies - the next generation. Nat Rev Genet. 2010; 11:31–46.
5. Cho IS, Blaser MJ. The human microbiome: at the interface of health and disease. Nat Rev Genet. 2012; 13:260–70.
6. Bamshad MJ, Ng SB, Bigham AW, et al. Exome sequencing as a tool for Mendelian disease gene discovery. Nat Rev Genet. 2012; 12:745–55.
7. Ozsolak F, Milos PM. RNA sequencing: advances, challenges and opportunities. Nat Rev Genet. 2011; 12:87–98.
8. Meyerson M, Gabriel S, Getz G. Advances in understanding cancer genomes through second-generation sequencing. Nat Rev Genet. 2010; 11:685–96.
9. Laird PW. Principles and challenges of genomewide DNA methylation analysis. Nat Rev Genet. 2010; 11:191–203.
10. Van Neste C, Van Nieuwerburgh F, Van Hoofstat D, et al. Forensic STR analysis using massive parallel sequencing. Forensic Sci Int Genet. 2012; 6:810–8.
11. Rockenbauer E, Hansen S, Mikkelsen M, et al. Characterization of mutations and sequence variants in the D21S11 locus by next generation sequencing. Forensic Sci Int Genet. 2014; 8:68–72.
12. Fordyce SL, A′vila-Arcos MC, Rockenbauer E, et al. High-throughput sequencing of core STR loci for forensic genetic investigations using the Roche Genome Sequencer FLX platform. Biotechniques. 2011; 51:127–33.
13. Dalsgaard S, Rockenbauer E, Buchard A, et al. Non-uniform phenotyping of D12S391 resolved by second generation sequencing. Forensic Sci Int Genet. 2014; 8:195–9.
14. Scheible M, Loreille O, Just R, et al. Short tandem repeat sequencing on the 454 platforms. Forensic Sci Int Genet Suppl Ser. 2011; 3:357–8.
15. Bornman DM, Hester ME, Schuetter JM, et al. Short-read, high-throughput sequencing technology for STR genotyping. Biotechniques. 2012; 0:1–6.
16. Langmead B, Salzberg SL. Fast gapped-read alignment with Bowtie 2. Nat Methods. 2012; 9:357–9.
17. Li H, Handsaker B, Wysoker A, et al. The Sequence Alignment/Map format and SAMtools. Bioinformatics. 2009; 25:2078–9.
18. Quinlan AR, Hall IM. BEDTools: a flexible suite of utilities for comparing genomic features. Bioinformatics. 2010; 26:841–2.
19. Robinson JT, Thorvaldsdo ′ttir H, Winckler W, et al. Integrative genomics viewer. Nat Biotechnol. 2011; 29:24–6.
20. Van Neste C, Vandewoestyne M, Van Criekinge W, et al. My-Forensic-Loci-queries (MyFLq) framework for analysis of forensic STR data generated by massive parallel sequencing. Forensic Sci Int Genet. 2014; 9:1–8.
21. Gymrek M, Golan D, Rosset S, et al. lobSTR: a short tandem repeat profiler for personal genomes. Genome Res. 2012; 22:1154–62.
Fig. 1.
Schematic view of STR reference sequences. Long flanking sequences ranged between 500 bp and 550 bp in STR reference sequences were designed for complete alignment of sample sequences that generated with any primer combinations.
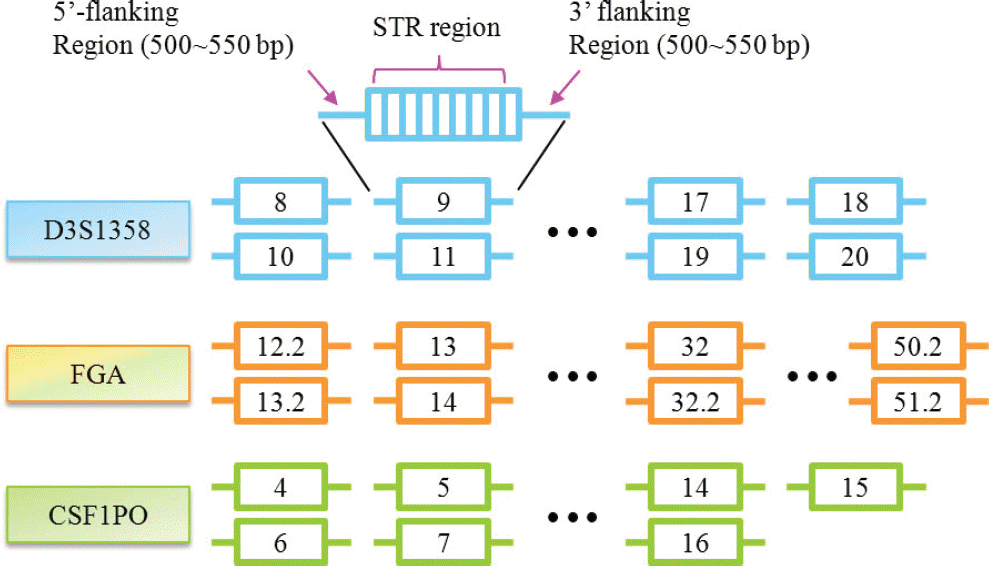
Fig. 2.
Quality check of constructed libraries on High Sensitivity chip using 2100 Bioanalyzer. Fragments less than 100 bp including adaptor dimers were successfully removed. a: Standard male DNA 2800M; b: Standard female DNA 9947A; c: 1:1 mixture
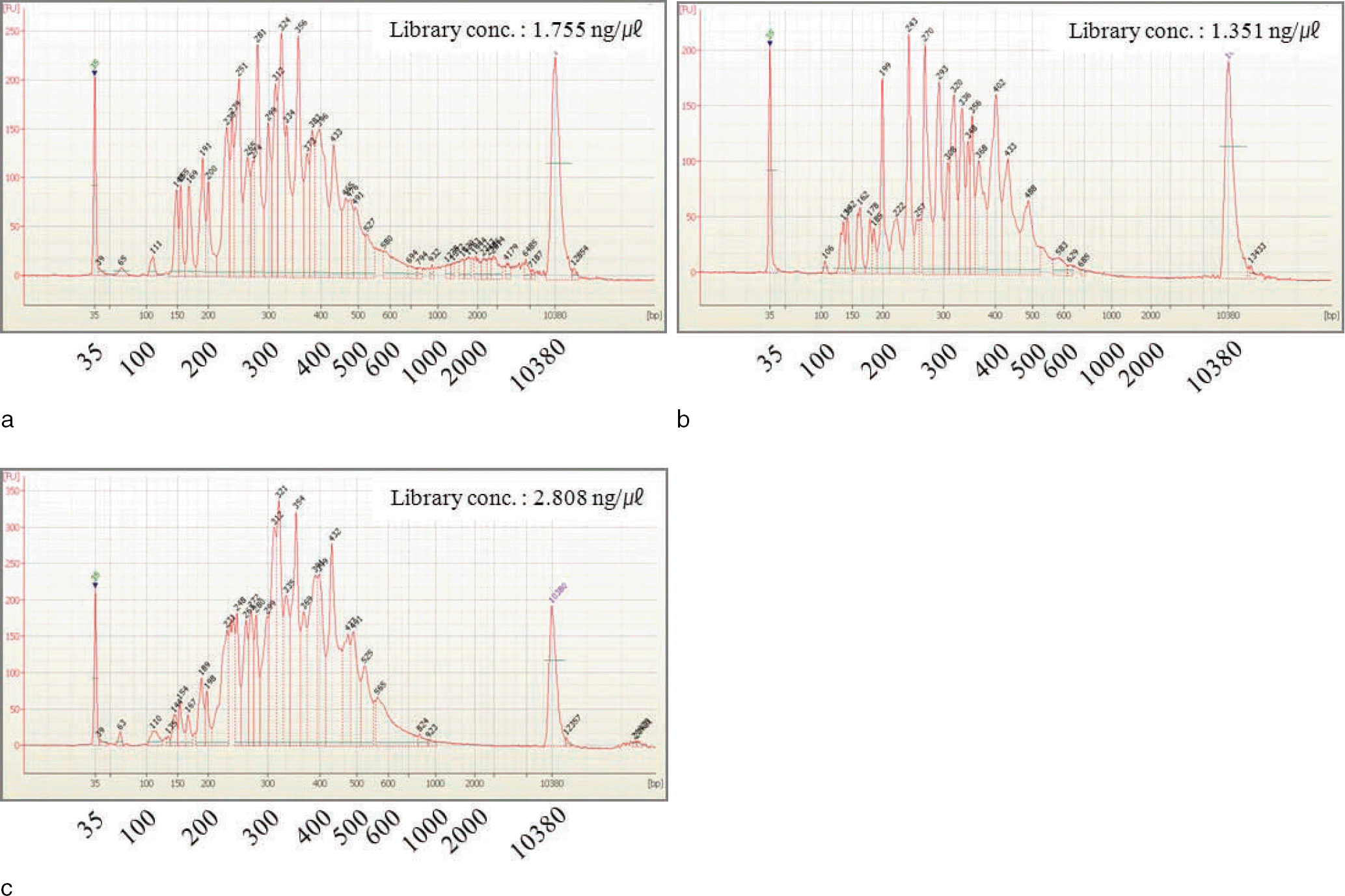
Fig. 3.
Estimation of mixture ratio based on reference/variant ratios from observed sequence variations in D13S317 locus. The sequence variation of adenine (A) to thymine (T) was detected in 3´ flanking region of D13S317 locus. Mixture ratio was estimated to 46% (A) : 53% (T). a: Standard male DNA 2800M; b: Standard female DNA 9947A; c: 1:1 mixture; d: Mixture ratio
Table 1.
Adjusted Final Concentrations of Primer Sets for Multiplex PCR system∗
Table 2.
Read Counts of 15 STR Loci in Each Sample
| STR locus | Amplicon size range (bp) | 2800M | 9947A | 1:1 mixture | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| All∗ | Entire STR† | Entire STR/ All (%) | All | Entire STR | Entire STR/ All (%) | All | Entire STR | Entire STR/ All (%) | ||
| D3S1358 | 115-147 | 9470 | 8743 | 92.3 | 6341 | 6012 | 94.8 | 14261 | 13306 | 93.3 |
| D5S818 | 119-155 | 9485 | 8705 | 91.8 | 5523 | 5011 | 90.7 | 9347 | 8531 | 91.3 |
| D7S820 | 215-247 | 3676 | 3476 | 94.6 | 1868 | 1780 | 95.3 | 4815 | 4603 | 95.6 |
| D8S1179 | 203-247 | 4458 | 4017 | 90.1 | 1967 | 1805 | 91.8 | 3368 | 3054 | 90.7 |
| D13S317 | 169-201 | 4897 | 4631 | 94.6 | 4060 | 3868 | 95.3 | 12839 | 12140 | 94.6 |
| D16S439 | 264-304 | 967 | 877 | 90.7 | 708 | 655 | 92.5 | 2497 | 2361 | 94.6 |
| D18S51 | 209-366 | 739 | 332 | 44.9 | 1284 | 546 | 42.5 | 1117 | 481 | 43.1 |
| D21S11 | 203-259 | 3045 | 2313 | 76.0 | 2996 | 2525 | 84.3 | 4873 | 3871 | 79.4 |
| CSF1PO | 321-357 | 291 | 244 | 83.8 | 596 | 522 | 87.6 | 862 | 742 | 86.1 |
| FGA | 322-444 | 956 | 460 | 48.1 | 666 | 255 | 38.3 | 3137 | 1440 | 45.9 |
| Penta D | 376-441 | 142 | 31 | 21.8 | 267 | 56 | 21.0 | 403 | 75 | 18.6 |
| Penta E | 379-474 | 193 | 84 | 43.5 | 356 | 116 | 32.6 | 563 | 309 | 54.9 |
| TH01 | 156-195 | 5503 | 4620 | 84.0 | 3324 | 2811 | 84.6 | 6712 | 5518 | 82.2 |
| TPOX | 262-290 | 269 | 230 | 85.5 | 215 | 183 | 85.1 | 679 | 576 | 84.8 |
| vWA | 123-171 | 3153 | 2782 | 88.2 | 1014 | 919 | 90.6 | 8565 | 7649 | 89.3 |
| AMEL | 106, 112 | 3416 | 3247 | 95.1 | 1773 | 1741 | 98.2 | 2334 | 2247 | 96.3 |
| Total | 50550 | 44792 | 88.6 | 32958 | 28805 | 87.4 | 76372 | 66903 | 87.6 |
Table 3.
Determination of D3S1358 Alleles based on Percentage of Allele Coverage in 2 Single-sources and 1:1 Mixture
Table 4.
STR Genotyping Results in 2 Single-sources and 1:1 Mixture examined by CE and NGS Analyses
Table 5.
Repeat Structures of 15 STRs in Two Standard Samples from NGS Data
 XML Download
XML Download