

 PDF
PDF Citation
Citation Print
Print



INTRODUCTION
Semantic segmentation is to predict semantically meaningful areas using predefined specific labels for each pixel of an analyzed image. It is a fundamental method for biomedical imaging.123 Various semantic segmentation techniques have been developed over several decades, based on our evolving understanding of the human visual system and various theories on image processing. Recently, several algorithms based on convolutional neural networks (CNNs) have combined with conditional random fields4 and recurrent neural networks.5 The fully convolutional network (FCN)6 and DeepLab,7 have been proposed for enhancing the segmentation of specific areas. The 3-dimensional (3D) U-net including encoder and decoder has shown the superior for the segmentation of 3D volumetric medical images.89 Some researchers have proposed that novel cascaded network (segmentation-by-detection networks and cascaded 3D FCN) is able to increase the inference of segmentation with a region proposal network prior to the segmentation.1011121314 It is important to use high-quality data for deep learning to learn high-performance semantic segmentation. Furthermore, there still exist several challenges in this field: First, it is difficult to acquire a large number of reliable annotated data for semantic segmentation owing to the substantial variety in manual human segmentation. Second, biomedical imaging datasets are typically scarce owing to the cost of high-quality labeled clinical data. In particular, for segmentation of medical images related to rare diseases or complex cardiac structures, accurate annotations are relatively difficult to obtain, owing to the high anatomical variability of the organs/structures. To reduce the cost of manual annotation, the method for active learning was introduced in several studies.151617181920 Many researchers proposed active learning for building more generalizable models using a human-in-the-loop manner.1516171820 Some researchers conducted interactive learning using CNNs into scribble-based segmentation and the spatial coordinate (x, y, w, h) of an object to generalize previous unseen objects20 and developed CNNs to segment for the atrium and ventricle in cardiac imaging.2122
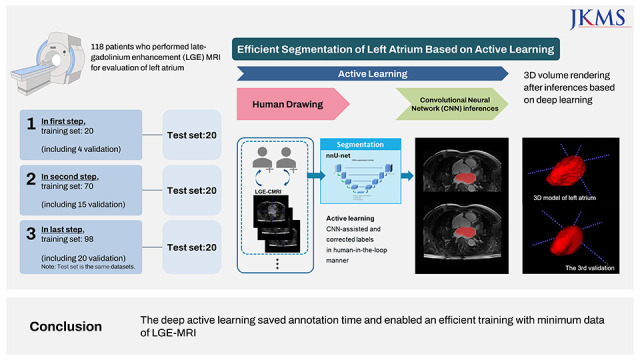
In our study, active learning based on deep learning was proposed to alleviate annotation efforts by gradually extending the late gadolinium enhancement in cardiac magnetic resonance imaging (LGE-CMRI) dataset to automate an effective segmentation for the complex structure of the left atrium with atrial fibrillation.
METHODS
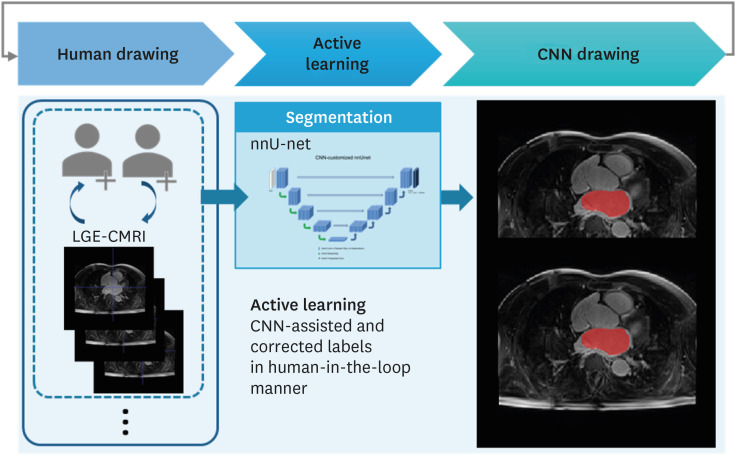
First, total datasets were collected from Picture Archiving and Communication System. The model was trained using a nnU-net,9 a 3D U-net architecture using a limited training dataset; the corresponding gold-standard annotations were delineated manually in this initial step. Second, the segmentation inferences of additional data predicted by the trained model were manually corrected by expert radiologists; these are the CNN-assisted and corrected labels for the second and last step inFig. 1.
Fig. 1
Active learning based on deep learning to automatically segment left atrium in LGE-CMRI.
CNN = convolutional neural network, LGE-CMRI = late gadolinium enhancement in cardiac magnetic resonance imaging.
Datasets
Total datasets were de-identified for preserving patient privacy. All processes were conducted with relevant regulations and guidelines.
LGE-CMRI was collected using a 3.0-T MRI unit (MAGNETOM Skyra; Siemens Healthineers, Erlangen, Germany), with a phased array 18-channel body matrix coil and a 12-channel spine matrix coil, at KUAH. All datasets were acquired during the first 15 minutes following the intravenous injection of 0.2 mmol gadoterate meglumine (Dotarem; Guerbet, Paris, France) per kilogram of body weight, using a 3D inversion recovery gradient-echo pulse sequence with an electrocardiography-gated pulse and respiratory navigation. A Look-Locker sequence using different inversion times was used to determine the optimal nulling time for a normal myocardium in LGE-CMRI. The typical parameters of LGE-CMRI were as follows: voxel size was 1.5 × 1.5 × 1.5 mm; repetition time ms/echo time ms was 487.2/1.3; inversion time was 300–330 ms; flip angle was 15°; bandwidth was 491 Hz/pixel; parallel acquisition technique factor = 2.
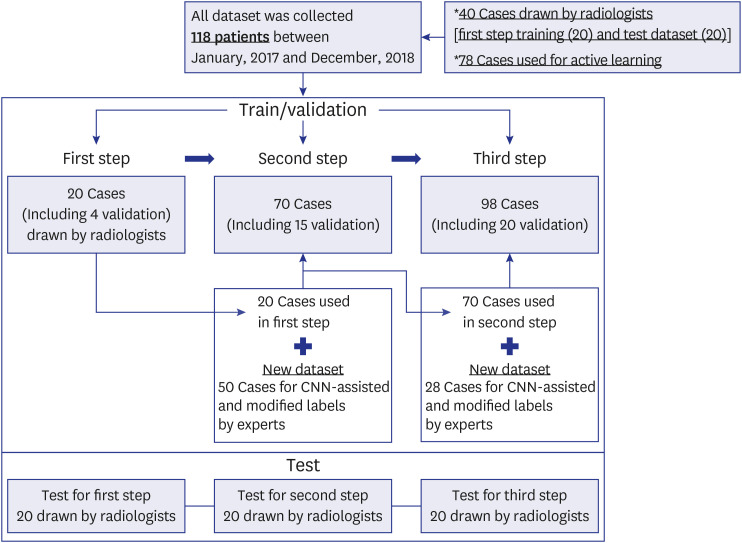
It has been used commonly for patients scheduled for catheter ablation of AF in clinical practice. So, it is difficult to enroll healthy individuals who underwent 3D LGE-MRI as a control group. The dataset consisted of 118 cases of patients including atrial fibrillation to evaluate the left atrium with excellent spatial resolution; they were used to train in the framework, as shown inFig. 2. the ground-truth segmentation of 40 LGE-CMRI cases that for the first step in active learning was performed by two expert cardiac radiologists (S.H.H., with the experience during 12 years, H.C. with experience during 5 years in cardiac imaging), with the AVIEW platforms, version 1.0.3 (Coreline Software©, Seoul, Korea;https://www.corelinesoft.com). All datasets were split into the training, tuning, and test sets (7:1:2). The entailed labeling voxels on every LGE-CMRI slice included non-background (i.e., left atrium) and background, using the AVIEW software (Coreline Software©). In the second and last, 78 cases were utilized to train using active learning, as shown inFig. 1. All of the input datasets were resampled to 208 × 208 pixels (XY spatial size), including 80 slices along the Z direction, with the median voxel spacing of their corresponding dataset at the batch time. The 250 batches were used per epoch. We used third-order spline interpolation for LGE-CMRI and nearest-neighbor interpolation for the respective segmentation mask. Simple z-score normalization was conducted to each LGE-CMRI for intensity normalization. For efficiently training, we performed aggressive data augmentation.
The deep learning architecture used for active learning
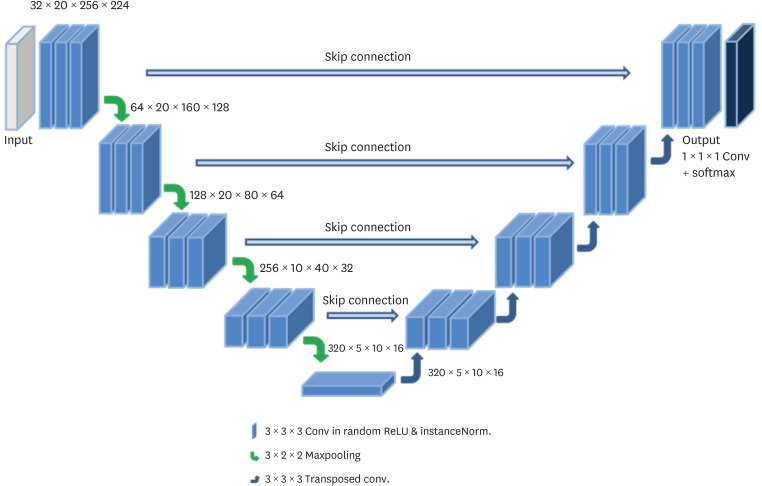
We incorporated 3D U-net of nnU-net9 to segment the left atrium; this resulted in an exceptional accuracy in the segmentation of the regions of interest in medical datasets. The 3D U-net9 was shown inFig. 3. This includes an encoder and a decoder framework including the transposed convolution operations. The left network lowers the dimensionality while opposite network (right side) upscales the original dimensionality. The encoder part includes a conventional CNN, which successfully aggregates semantic information as spatial information is reduced. For segmentation, both semantic information and spatial information are important to train and infer main objects on medical datasets; for recovering the loss of spatial information, decoder network recombines it with the layer of the left side for skip connection. The two networks (encoder and decoder) consist of the convolution layers (or transposed) and up- or down-scaling layers (pooling layer). The down-scaling is performed by max-pooling (3 × 3 × 3). A distinctive inference of the 3D U-net is to extract it through the connection the left and the right. The combination of both enhances the inference of specific areas by combining fine anatomical detail from the down-scaling path with the broader contextual features from the up-scaling path. In the present study, an epoch consisted of 250 batches. In this network, the leaky ReLU activation functions were replaced with random ReLUs and loss functions were used including dice, boundary loss functions, and binary cross-entropy (BCE). We used the Adam optimization approach for stochastic gradient descent, with an initial learning rate of 3 × 10−4 and l2 weight decay of 3 × 10−5.
Fig. 3
The 3D U-net architecture for segmentation the left atrium in cardiac imaging.
3D = 3-dimensional.
The dice similarity coefficient (DSC) were calculated for errors, as shown in Eq. 1. The loss function, defined as dice loss (DL) in Eq. 2 and BCE in Eq. 3. The ground truth and CNN segmentation for volume parameters are defined byVgs andVseg, respectively.
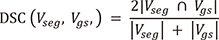
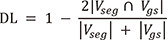
where p and s define the inferred probability and the desired output, respectively.
Active learning
In the first, for initial training, the left atrium volume images of 20 cases manually labeled for gold-standards by two expert cardiac radiologists were trained. After first step, the gold-standards for new data (50 cases) were manually modified after inferencing using first step model. In the second step, 20 cases used in the first were trained along with new 50 cases corrected in a human-in-the-loop manner after inferencing the left atrium segmentation using the first model inFig. 2. After second step, the inferences of new 28 cases using second step model were manually modified for the last step. Finally, in the last step, 98 cases (70 cases from first and second and 28 new cases) were used to train. In first, second, and last step, the inferences of the aforementioned steps were used to evaluate the accuracy of inference using hold-out 20 cases. Manually modified segmentation based on CNNs was conducted by two experts per second and in the last step using the AVIEW platforms, version 1.0.3 (Coreline Software©). To reduce the bias of manually modified segmentation, two experts proceeded through the convergence process.
Experimental setups
To segment the left atrium for a 3D volume, each axial section of the volume was presented sequentially to the model. The model was built in Python 3.6, using the deep learning framework PyTorch. The training, tuning, and test were performed using PyTorch with a TensorFlow 1.15.0 backend and Titan RTX GPU (24 GB, NVIDIA Corporation, Santa Clara, CA, USA). In the first, the process for learning saturated approximately after 120 epochs, owing to the small datasets for 20 cases. The second and last steps required 120–200 epochs, owing to the comparatively larger number (70 cases and 98 cases) of datasets. The difference for overall DSCs between the validation and test of the last model was 1.12. In addition, the total 98 datasets, except 20 cases in the first step and 20 cases for test, were labeled by two expert radiologists. These datasets were used for comparison with other models.
RESULTS
Performance evaluation for active learning with 3D U-net
To verify the performance of active learning on LGE-CMRI data, our methods was evaluated through three steps. DSC between the results of inference and ground truth were compared for 20 cases except for the 98 segmented cases, which were used in each step for active learning.
The results are presented inFig. 4. In the 1st validation after the 1st training, 3D volume rendering MRI (Fig. 4D) shows left atrial chamber, aorta (arrow) and pulmonary artery (arrowhead) selected by the trained AI. In the 2nd validation after the 2nd training, 3D volume rendering MRI (Fig. 4E) shows left atrial chamber and a part of aorta (arrow) selected by the trained AI. Lastly, in the 3rd validation after the 3rd training, 3D volume rendering MRI (Fig. 4F) shows only left atrial chamber correctly selected by the trained AI. Active learning yielded the best segmentation sensitivity and a low false positive in the last step for the limited dataset. As the step goes up, the accuracy of segmentation on LGE-CMRI gets better. Especially, the erroneous areas outside of the left atrium were alleviated.
Fig. 4
Active learning and validation process in the segmentation of the LA of LGE-CMRI: ground truths (red) as a reference covering entire left atrial chambers on LGE-CMRI: (A) raw axial, (B) labeled raw axial for LA, and (C) volume rendering for LA; and validation: (D) first step, (E) second step, and (F) third step; white arrows or arrowhead are false positives.
LGE-CMRI = late gadolinium enhancement in cardiac magnetic resonance imaging, LA = left atrium, 3D = 3-dimensional.
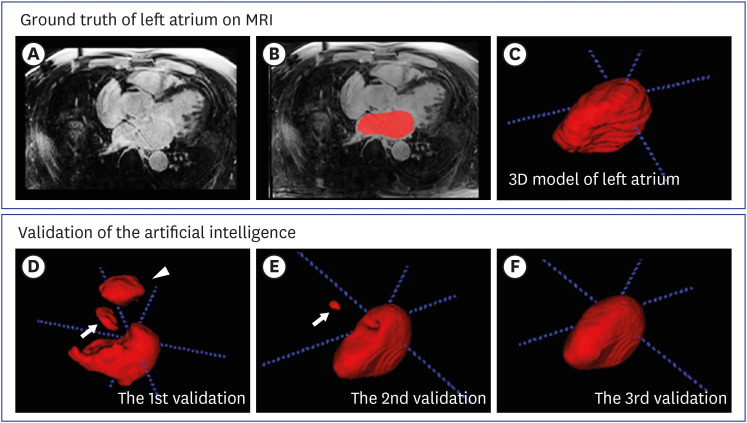
Table 1 lists the DSCs for the left atrium in each step and the difference between the DSC values in each step. The DSC values for the left atrium on LGE-CMRI for the first, second, and last steps were 0.85 ± 0.06, 0.89 ± 0.02, and 0.90 ± 0.02, respectively. The mean DSCs for the cardiac left atrium gradually amplified through each step. In addition, the inferences in the last step were found better when compared with other steps (first and second step) using our dataset, as shown inTable 1. Statistical significance was set at a two-sidedP < 0.05.
Table 1
DSCs and the measurements of Bland-Altman analysis for the first, second, and last step for test dataset (20 cases) using 3D U-net with active learning inFig. 2

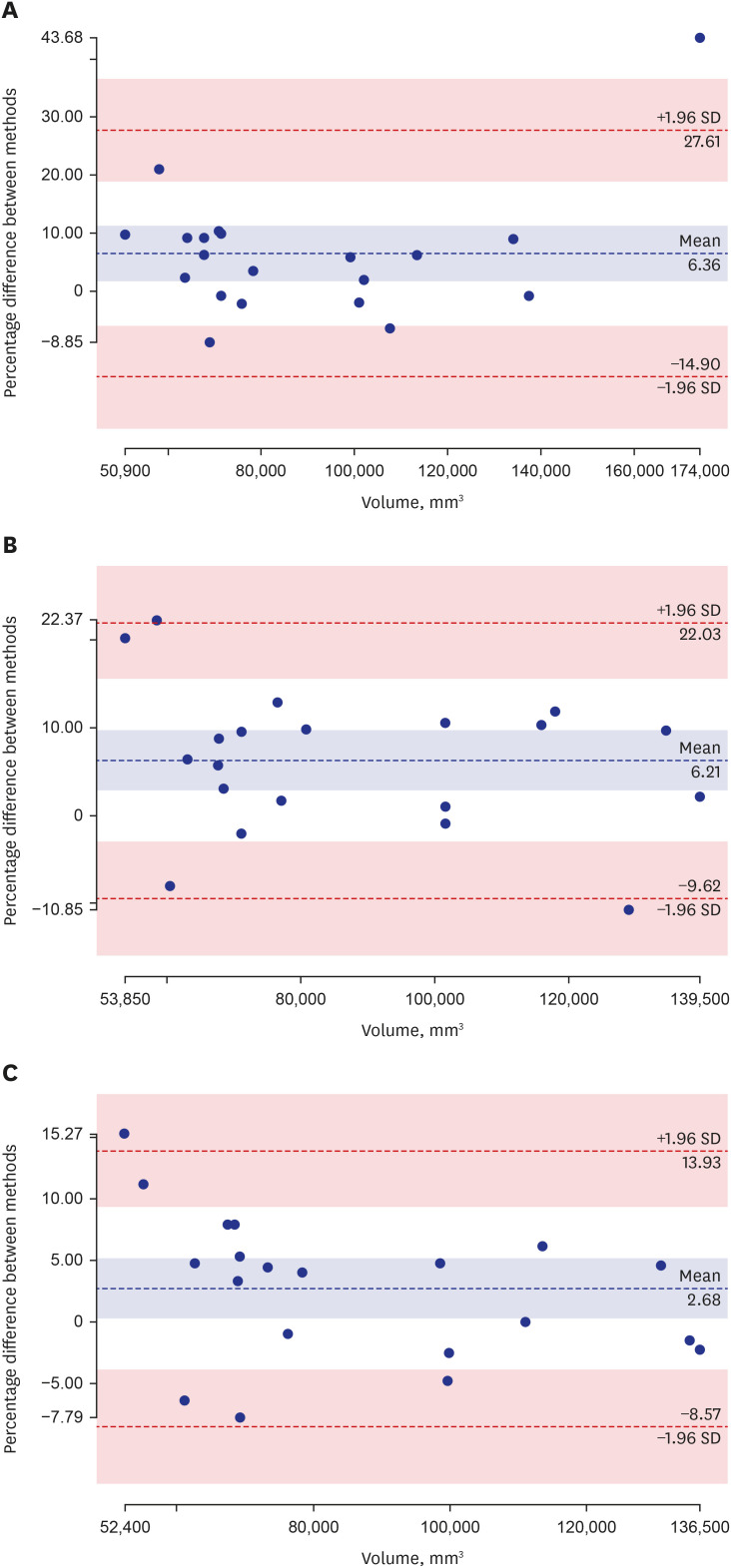
The reproducibility of the left atrial volume was analyzed using the Bland-Altman analysis. The biases (95% confidence interval) in the Bland-Altman analysis for the first, second, and last steps were 6.36% (−14.90–27.61), 6.21% (−9.62–22.03), and 2.68% (−8.57–13.93), respectively.Fig. 5 shows the plots for Bland-Altman analysis on volumes. InTable 2, compared with the first step (only manual segmentation to train), the duration of manually modified segmentation after the inference using deep learning decreased by about 3 minutes 1 seconds ± 13 seconds for 50 cases in the second step and by 3 minutes 1.44 seconds ± 16 seconds for 28 cases in the last step.
Fig. 5
The plots for Bland-Altman analysis on volumes between the results of all steps and ground truth including (A) in the first, (B) in the second, and (C) the last in active learning.
SD = standard deviation.

Comparison for active learning between 3D and 2D U-net
The proposed method (3D U-net for active learning) was compared the results with a 2D U-net9 with active learning.Table 3 shows that the DSCs for the 3D and 2D U-net were 0.90 and 0.87, respectively. Statistical significance was set at a two-sidedP < 0.05.
Table 3
The comparison for DSCs and the measurement for Bland-Altman analysis in the last step model the 2D and 3D U-net with active learning with test dataset (20 case)

The Bland-Altman plot biases for the 3D and 2D U-net were 2.68% (−18.89–23.70) and 2.41% (−8.57–13.93), respectively.
Comparison for active learning between 2D and 3D U-net
Next, customized 3D U-net9 for active learning was compared with basic 3D U-net23 (with and without active learning). The basic 3D and 3D U-net without active learning were trained using all datasets, including the 98 cases.Table 4 shows that the DSCs for the basic 3D U-net, 3D U-net without active learning, and this with active learning were 0.78 ± 0.06, 0.89 ± 0.02, and 0.90 ± 0.02, respectively. Statistical significance was set at a two-sidedP < 0.05.
Table 4
The comparison of DSCs and the measurement of Bland-Altman analysis for the basic 3D U-net without active learning, the 3D U-net without active learning, and 3D U-net with active learning for the test dataset (20 cases)

| Model | DSC | Bland-Altman plot analysis | Precision | Recall |
|---|---|---|---|---|
| 3D U-net (basic UNET,23 without active learning) | 0.78 ± 0.06 | −12.54% (−50.56–25.47) | 0.74 ± 0.08 | 0.84 ± 0.11 |
| 3D U-net (without active learning) | 0.89 ± 0.02 | 6.13% (−6.11–18.38) | 0.86 ± 0.03 | 0.91 ± 0.04 |
| 3D U-net9 (the model in last step) | 0.90 ± 0.02 | 2.68% (−8.57–13.93) | 0.88 ± 0.03 | 0.91 ± 0.03 |
DSC for basic 3D U-net25 (MONAI platform—non-active learning), 3D nnU-net without active learning, and 3D nnU-net with active learning; pairedt-test (P < 0.05) for the 3D U-net with active learning and the basic 3D U-net; pairedt-test (P = 0.043) for the 3D U-net with active learning and this without active learning.
DSC = dice similarity coefficient, 3D = 3-dimensional.
The Bland-Altman analysis biases for the basic 3D U-net,23 3D U-net for active learning, and this without active learning were −12.54% (−50.56–25.47), 6.13% (−8.57–13.93), and 2.68% (−18.89–23.70), respectively.
DISCUSSION
In our study, active learning based on customized nnU-net16 for the left atrium segmentation with limited datasets of LGE-CMRI was introduced. All cases used in each step for active learning was randomly extracted, according to the heuristic parameters for 118 cases. Our methods can effectively infer the left atrium segmentation for a limited clinical dataset through three steps. In addition, the proposed architecture is likely to decrease the effort and cost required for generating new ground truth for training and efficiently reduce the labeling time by using the CNN-corrected label curation.
We used a 3D U-net in nnU-net,9 without a cascade network, for active learning on LGE-CMRI. The 3D U-net has demonstrated excellent segmentation inference in the medical datasets, thereby becoming one of the most excellent approaches toward semantic segmentation.12 Furthermore, some combined this with detection networks using a cascading manner.1011121314 Tang et al.12 developed cascade network using the VGG-16 model with combination for detection and segmentation network. And Roth et al.13 presented this method, a second-stage FCN that can focus more on the boundary regions of objects.
For verification of the performance of active learning with a limited clinical dataset, the results of each step were compared. InTable 1, the DSC values for the left atrium in the last step were the best (0.90), and the false positive of segmentation reduced per step inFig. 4. The bias (limit of agreement, 95%) in the Bland-Altman plot was 2.68% (−8.57–13.93) in the last step inFig. 5 andTable 1. The average DSCs for the left atrium gradually were better after each step. And, the results of the proposed method were compared with 2D U-net (the last step for active learning).9 The results of the 3D U-net (the last step for active learning) on LGE-CMRI outperformed the 2D U-net (the last step for active learning). The margin of error (2.41% [−18.89–23.70]) in the Bland-Altman analysis plot for the 2D U-net was higher than that for the 3D U-net (2.68% [−8.57–13.93]), while the DSC value (0.87) for the 2D U-net was lower than that for the 3D U-net (0.90). The segmentation of complex structures like the left atrium on LGE-CMRI is important to train datasets with 3D volume and to utilize the active learning framework in a limited clinical dataset. InTable 2, after incorporating active learning, the overall segmentation time was significantly decreased. More than half the time required for manual splitting has been decreased.
Previously, active learning or self-supervised learning was proposed in medical imaging and other fields for effective segmentation and reduction of the annotation effort.16 Especially, Kim et al.16 presented active learning using cascaded network and applied that approach to kidney computed tomography data. Their method demonstrated impressive performance on abdominal computed tomography images. In the active learning, an annotation suggestion approach can direct manually annotated efforts to the most effective areas.24 The method to segment the myelin sheath from histological images, wherein they used the Monte Carlo dropout approach for assessing the model’s uncertainty and for selecting the scans that would be annotated in the next iteration was developed.13 A dual network (AtriaNet) was used with a full manual labeling dataset for the segmentation of the left atrium on LGE-CMRI.25 AtriaNet was trained without active learning using datasets.24 However, the annotation of gold-standard takes longer to train than our method due to the time required to label all datasets (110 cases).25 In addition, we used deep learning (3D U-net) based active learning with LGE-CMRI datasets. The model of the 3D U-net without active learning was compared with ours for verification of the active learning; the performance of active learning was better than others, as described inTable 4.
Although the segmentation of the left atrium without active learning shows good performances on LGE-CMRI, we can further reduce the time and cost of annotation and improve the segmentation of the complex structure of the left atrium with atrial fibrillation using a limited clinical dataset.
The active learning was used to acquire new gold-standard annotations, segmentation before manual correction, and iteratively training the network using a small amount of dataset instead of manually suggesting annotation to segment specific area in medical environments. Our proposed approach enables effectively and rapidly to segment of complex cardiac anatomy with limited datasets. Because human-produced annotations, owing to intra-human and inter-human variabilities, are not always consistent in the labeling process, the active learning framework is a useful alternative for initiating deep learning with labeling, which is extremely laborious in clinical fields.
However, our study has several limitations. The accuracy for segmentation is required to improve using a large number of training datasets including atrial fibrillation patients scheduled for catheter ablation of AF in clinical practice and use superior networks for resolving ambiguities.522 This will be focus of critical task to interpret the outputs of our deep learning in the future work.
In addition, comparing with other segmentation networks, as well as further validation using more datasets or multi-center datasets should be conducted, for verifying the stability and efficiency of our methods for active learning. Lastly, we will develop the model for automatically segmenting left atrium including the pulmonary vein in LGE-CMRI after this research.
In conclusion, our present results demonstrate that deep learning based on active learning can reduce annotation efforts and can be used to segment the left atrium by efficient training on limited 3D LGE-CMRI in clinical environments.
 XML Download
XML Download