

 PDF
PDF Citation
Citation Print
Print



I. Introduction
II. Methods
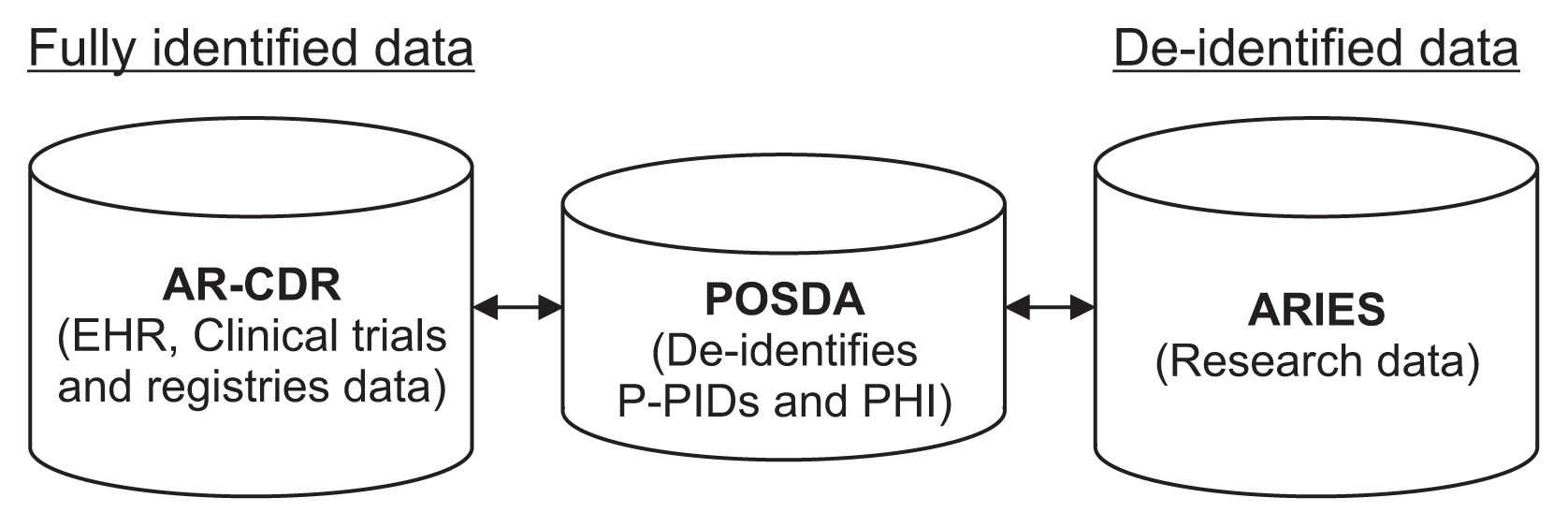
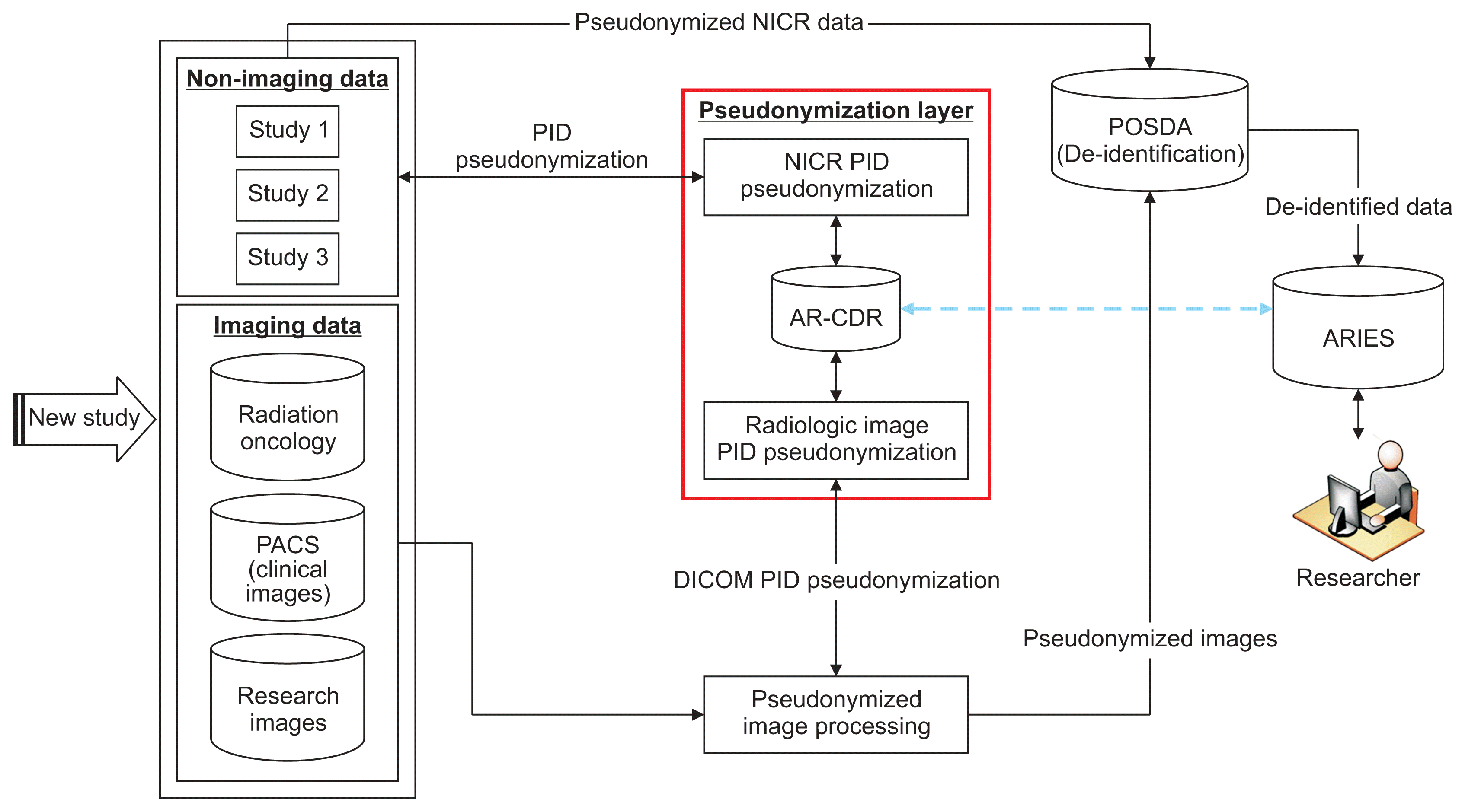
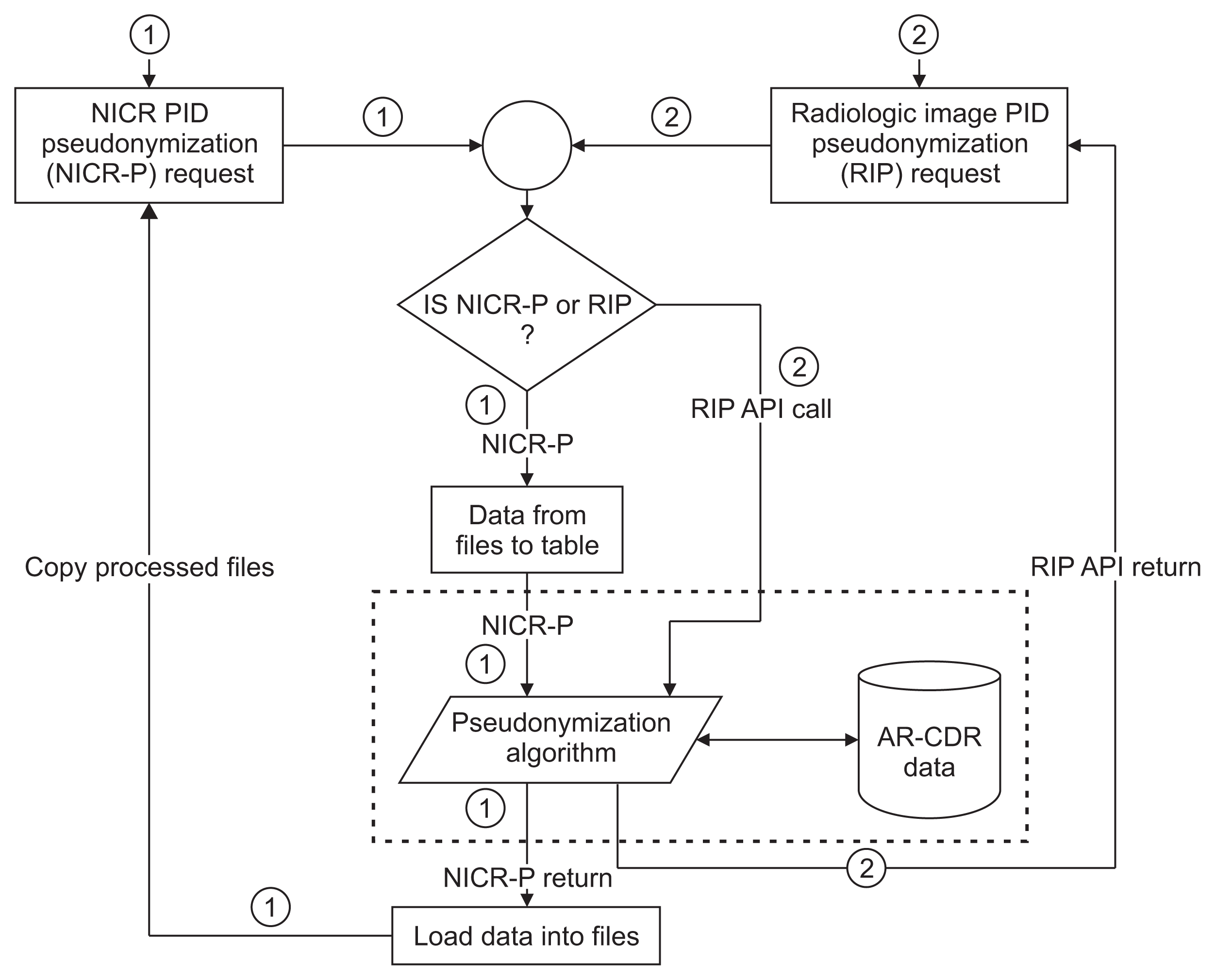
(1) NICR-P process: In this process, as outlined by Path ① in Figure 3, principal investigators (PIs) provide a list of PIDs via secure data transfer, which is stored on the AR-CDR file server. O-CAPP’s nightly automated process scans the dataset for each study and generates associated P-PIDs. The NICR-P process requires the following data elements to perform pseudonymization: STUDY_ID, STUDY_NAME, MRN, and ALTERNATE_ID. O-CAPP reads data from the source files and loads the source data into a pre-process staging table. P-PIDs are then generated and stored in the post-process staging table. The PIDs and associated P-PIDs are copied from the staging table to source files in respective study directories.
(2) RIP process: In this process, radiologic images are pseudonymized by O-CAPP via a secured API call. Each API request initiates the pseudonymization algorithm by submitting the PIDs available within the image’s DICOM header. Upon completion of pseudonymization, the generated P-PIDs are returned in response to the API call, which will replace PIDs in the respective DICOM header. The process of extracting a PID from a DICOM header, initiating an API request by submitting the PID, and replacing the PID with the returned P-PID in the DICOM header is done by the “pseudonymized image processing” component. All the API requests and responses for pseudonymization are securely stored in the AR-CDR’s audit table. The table holds both PIDs received and P-PIDs returned. The full RIP process is represented by Path ② in Figure 3.
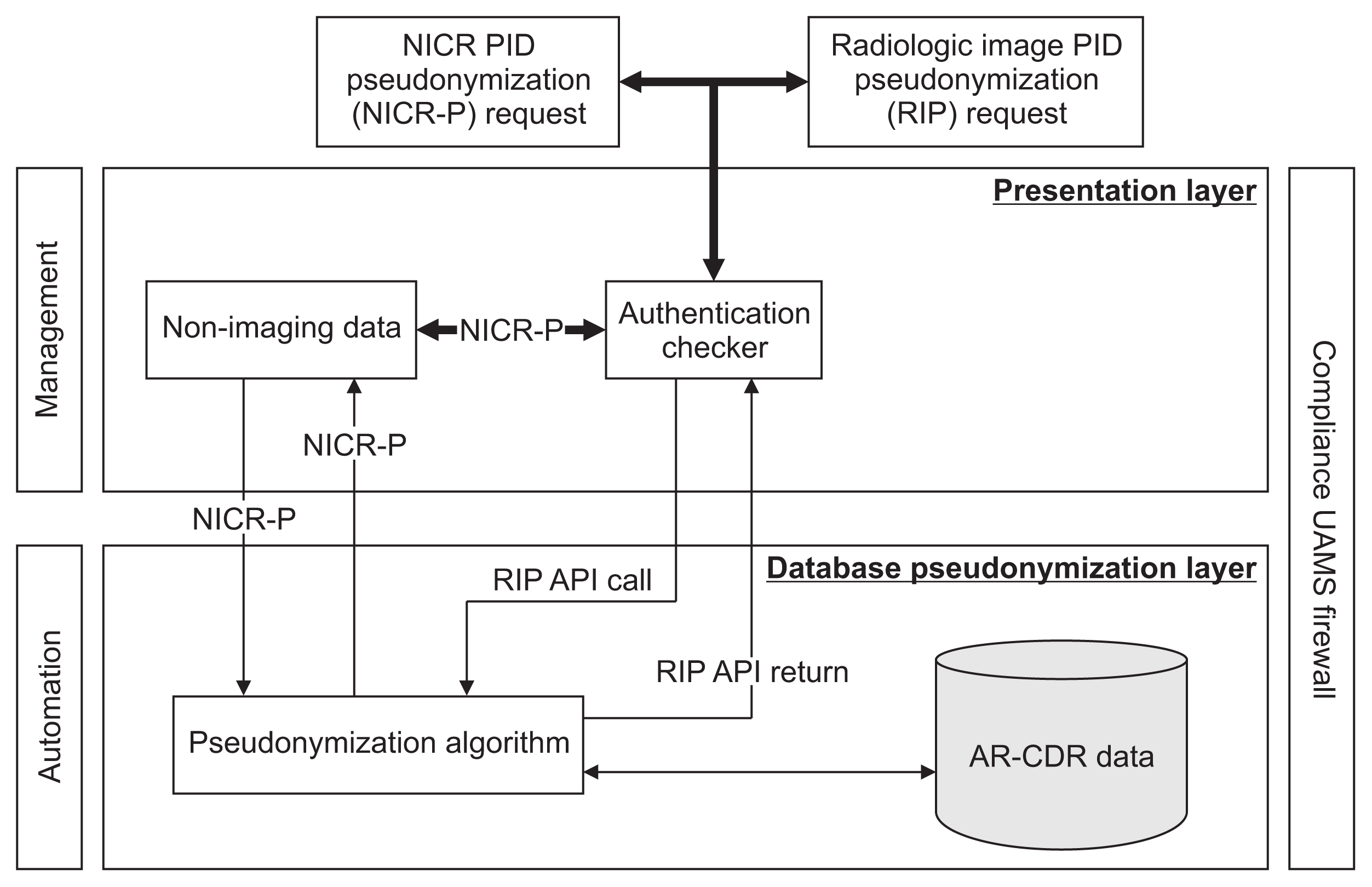
1. O-CAPP Framework Setup at UAMS
2. O-CAPP’s Pseudonymization Algorithm
(1) Case 1: In cases in which there is no record of the participant in either of the AR-CDR patient tables, the algorithm assumes it is a new participant. A record for this participant is inserted into the PATIENT and PATIENT_ID_MAP tables. A UID is generated for this participant, and a study-specific P-PID is generated and returned to the PL.
(2) Case 2: In cases in which a record of the participant is located in both AR-CDR patient tables, but there is no study-specific identifier, a P-PID for the study is generated and stored in the PATIENT_ID_MAP table and returned to the PL.
(3) Case 3: In cases in which a record already exists for the participant in both AR-CDR patient tables for the specific study, the existing P-PID for the participant is returned to the PL.
 XML Download
XML Download