

 PDF
PDF ePub
ePub Citation
Citation Print
Print


Abstract
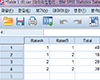
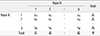
Inter-rater reliability refers to the degree of agreement when a measurement is repeated under identical conditions by different raters. In systematic review, it can be used to evaluate agreement between authors in the process of extracting data. While there have been a variety of methods to measure inter-rater reliability, percent agreement and Cohen's kappa are commonly used in the categorical data. Percent agreement is an amount of actually observed agreement. While the calculation is simple, it has a limitation in that the effect of chance in achieving agreement between raters is not accounted for. Cohen's kappa is a more robust method than percent agreement since it is an adjusted agreement considering the effect of chance. The interpretation of kappa can be misled, because it is sensitive to the distribution of data. Therefore, it is desirable to present both values of percent agreement and kappa in the review. If the value of kappa is too low in spite of high observed agreement, alternative statistics can be pursued.
Figures and Tables




References
1. Edwards P, Clarke M, DiGuiseppi C, Pratap S, Roberts I, Wentz R. Identification of randomized controlled trials in systematic reviews: accuracy and reliability of screening records. Stat Med. 2002; 21:1635–1640.

2. Higgins JP, Deeks JJ. Cochrane handbook for systematic reviews of interventions: chapter 7. Selecting Studies and Collecting Data. New York: John Wiley & Sons Ltd;2008. p. 151–156.
3. Viera AJ, Garrett JM. Understanding interobsever agreement: the kappa statistic. Fam Med. 2005; 37:360–363.
4. Gisev N, Bell JS, Chen TF. Interrater agreement and interrater reliability: key concepts, approaches, and applications. Res Social Adm Pharm. 2013; 9:330–338.
5. Cohen J. A coefficient of agreement for nominal scales. Educ Psychol Meas. 1960; 20:37–46.
6. Landis JR, Koch GG. The measurement of observer agreement for categorical data. Biometrics. 1977; 33:159–174.
7. SPSS statistics base 17.0 user's guide. Chicago: SPSS Inc.;p. 289–293.
8. Feinstein AR, Cicchetti DV. High agreement but low kappa: I. The problems of two paradoxes. J Clin Epidemiol. 1990; 43:543–549.
9. Cicchetti DV, Feinstein AR. High agreement but low kappa: II. Resolving the paradoxes. J Clin Epidemiol. 1990; 43:551–558.
10. Kim MS, Song KJ, Nam CM, Jung I. A study on comparison of generalized kappa statistics in agreement analysis. Korean J Appl Stat. 2012; 25:719–731.
11. Brennan RL, Prediger DJ. Coefficient kappa: some uses, misuses, and alternatives. Educ Psychol Meas. 1981; 41:687–699.
12. Byrt T, Bishop J, Carlin JB. Bias, prevalence and kappa. J Clin Epidemiol. 1993; 46:423–429.
13. Gwet KL. Handbook of inter-rater reliability. 3rd ed. Gaithersburg: Advanced analytics;2012. p. 15–28.
14. McHugh ML. Interrater reliability: the kappa statistic. Biochem Med (Zagreb). 2012; 22:276–282.
15. Stoller O, de Bruin ED, Knols RH, Hunt KJ. Effects of cardiovascular exercise early after stroke: systematic review and meta-analysis. BMC Neurol. 2012; 12:45.
 XML Download
XML Download