

 PDF
PDF ePub
ePub Citation
Citation Print
Print



INTRODUCTION
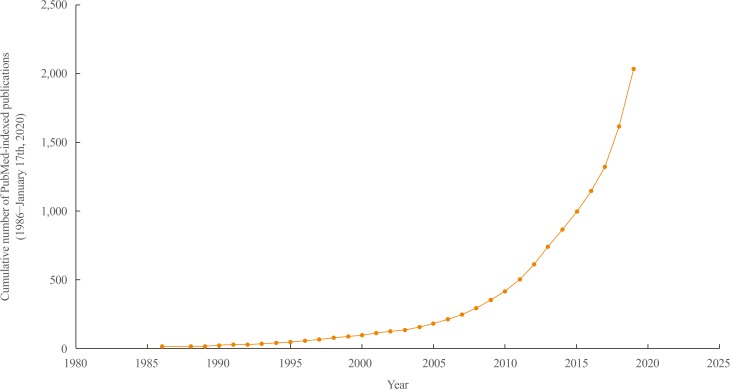
The use of machine learning (ML) applications in various fields of health research are rapidly expanding, and ML has the potential to improve the current health system and clinical practice. In endocrinology and metabolism research, the number of publications on ML has exponentially increased, reaching roughly 2,000 publications by the end of the last decade (PubMed query: Search ((((((“Machine Learning”[Mesh]) OR “Artificial Intelligence”[Mesh]) OR “Deep Learning”[Mesh])) OR (((machine learning [Title/Abstract]) OR artificial intelligence[Title/Abstract]) OR deep learning[Title/Abstract]))) AND ((((((((endocrinology[Title/Abstract]) OR diabetes[Title/Abstract]) OR pituitary[Title/Abstract]) OR thyroid[Title/Abstract]) OR adrenal gland[Title/Abstract]) OR osteoporosis[Title/Abstract])) OR ((((((“Endocrinology”[Mesh]) OR “Diabetes Mellitus”[Mesh]) OR “Pituitary Gland”[Mesh]) OR “Thyroid Gland”[Mesh]) OR “Adrenal Glands” [Mesh]) OR “Osteoporosis”[Mesh])); search date: January 1st, 1986 to January 17th) (Fig. 1). The accumulation of structured or unstructured medical data, the exponential growth of available computing power, and the availability of useful open resources for implementing ML have contributed to the expanding ML applications in health care. In this review, a brief overview of the basic concepts of ML, exemplary studies of ML applications in endocrinology research, and related perspectives will be provided for endocrinologists and clinical practitioners who are becoming interested in the principles of ML.
MACHINE LEARNING: A BRIEF INTRODUCTION
Artificial intelligence, machine learning, and deep learning
The terms “artificial intelligence (AI),” “ML,” and “deep learning” are often used concomitantly and sometimes interchangeably in the medical literature. The U.S. Food and Drug Administration defined AI as “the science and engineering of making intelligent machines, especially intelligent computer programs,” based on the definition proposed by McCarthy [12]. Learning and reasoning are the main functions that intelligence refers to in this context, although intelligence more broadly includes self-awareness, introspection, action, heuristics, and practical knowledge [1]. ML is defined as an “AI technique that can be used to design and train software algorithms to learn from and act on data,” as a subset of AI. Therefore, all ML counts as AI, but not all AI involves ML. Deep learning, also known as deep neural networks, refers to a subset of ML algorithms implemented by stacked multilayer neural networks, mimicking the neural architecture of the human brain. As noted in a summary report from the Third Annual Machine Learning for Health Workshop held in December 2018, traditional technical researchers and communities appear to favor the term “ML” when describing the methodology underlying their work. However, clinicians tend to prefer using “AI” as an umbrella term in the medical literature, and this discrepancy might need to be resolved in order to remove potential terminological barriers and to prevent unnecessary confusion among research communities [3].
Machine learning algorithms and performance metrics
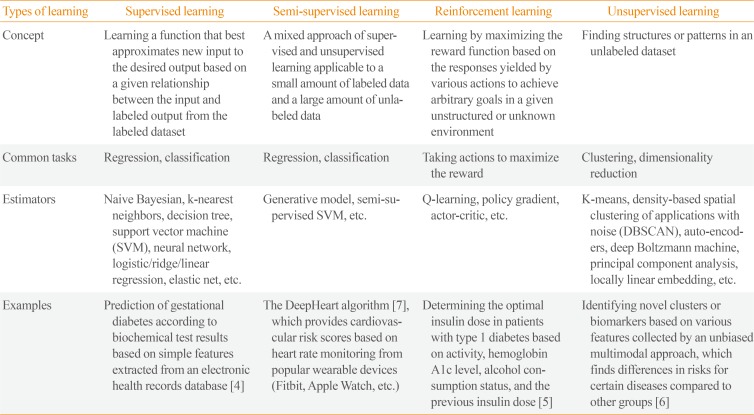
ML algorithms can be classified into four main categories: supervised, semi-supervised, unsupervised, and reinforcement learning (Table 1) [4567]. Supervised learning requires a labeled dataset with output mapped to input to train a function. The goal of supervised learning is to derive a function that infers the most desired output for new input from the previously labeled dataset. Unsupervised learning explores structures or patterns in unlabeled datasets to achieve clustering or dimensionality reduction. Semi-supervised learning is a blend of those two approaches that is suitable for datasets with a small amount of labeled data and extensive unlabeled data. Reinforcement learning is suitable for finding optimal actions in an unstructured and complex environment by maximizing the cumulative rewards from actions taken in that environment. Unlike supervised learning, which is based on prior knowledge of input-output mapping at the start, a reinforcement learning function evolves sequentially by collecting information on every action-response relationship during the task. Although some guidance on selecting an estimator can be obtained from a so-called “cheat-sheet” for initial ML estimators (scikit-learn; https://scikit-learn.org/stable/tutorial/machine_learning_map/index.html), a one-size-fits-all approach may not be applicable in most cases. Estimators are often chosen through an iterative process that takes into account the quantity, structure, and extendibility of the dataset, the characteristics of the research hypothesis or problems, the performance of trained functions, and researchers' experiences and intuition (Fig. 2). Choosing the performance metrics that best suit the research purpose is another task that needs to be carefully accomplished after establishing an ML model (Supplemental Table S1) [891011].
MACHINE LEARNING APPLICATIONS IN ENDOCRINOLOGY AND METABOLISM
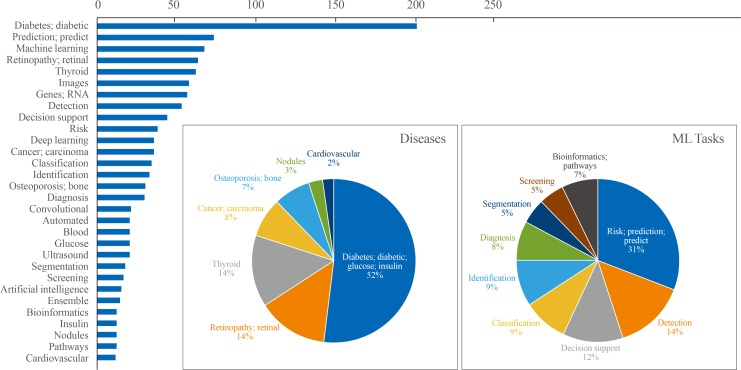
Results of the text analysis on the titles of literature were presented as Fig. 3. The titles of 611 studies (English language, human study, not a review or meta-analysis) published within the last 5 years were parsed to count the frequency of words that appeared. Among a total of 2,115 words, the top 30 words with high frequency were analyzed. Among diseases, ‘diabetes’ or ‘diabetic’ appeared most frequently among the top 30 words (52%), followed by retinopathy (14%), thyroid (14%), carcinoma (8%), and osteoporosis (7%). Regarding ML tasks, ‘risk prediction’ or ‘predict’ accounted for 31%, and the composite of ‘detection,’ ‘classification,’ ‘identification,’ and ‘diagnosis’ reached up to 40%, followed by ‘segmentation’ (5%) or ‘bioinformatics’ (7%). In this section, studies were summarized to present some exemplary cases in utilizing ML applications in the endocrinology and metabolism field. Seventeen studies were arbitrarily chosen on the basis of (1) the balance between disease fields (diabetes, thyroid, pituitary, and bone and mineral disorders), (2) inclusion of at least one study which illustrates the various types of ML applications (supervised, unsupervised, and reinforcement learning), and (3) the publication date within last 3 years. The research topics were categorized into screening and diagnosis, risk prediction, and translational research based on frequently appeared ML tasks from text analysis (Fig. 3), with subcategories that were not mutually exclusive in some cases. It should be noted that the selected studies might not be sufficient to reflect an entire trend of ML applications in the endocrinology field, but it can provide practical examples for understanding the utility of ML algorithms applied to various fields of endocrine researches. The details of the reviewed studies are summarized in Table 2 [456121314151617181920212223242526].
Screening and diagnosis
Improvement of screening strategies
The development of efficient screening tools for endocrine disorders may have clinical impacts, both in terms of improved prognoses of individual patients through disease detection at an earlier stage and the cost-effective allocation of public health resources by focusing on individuals with a high risk of disease and avoiding unnecessary testing in low-risk groups. Researchers have sought to determine whether ML algorithms are able to provide a better way of screening for various endocrine diseases. Artzi et al. [4] provided an excellent example of applying the principles of ML to find useful screening tools for gestational diabetes based on a sizeable electronic health record (EHR) database. EHR data of 588,622 pregnancies from 368,351 women collected at the nationwide level in Israel between 2010 and 2017 were used to train an ML model to predict the risk of gestational diabetes. Among 2,355 candidate features, the researchers developed a simple model consisting of only nine self-reportable questions (without previous laboratory results in some cases) based on a gradient boosting model, which showed fair discriminatory performance (area under the receiver operating characteristic curve, 0.80 vs. 0.68 for the conventional glucose challenge test at 24 to 28 weeks of gestation) even at an earlier time point relative to the initiation of pregnancy. Medical image data have the potential to provide features suitable for the opportunistic screening of endocrine disorders. Valentinitsch et al. [12] trained an ML model to identify individuals with prevalent vertebral fractures based on non-fractured vertebral regions in computed tomography scans taken for various purposes. By combining global and local density and texture parameters, the ML model outperformed volumetric bone mineral density (BMD) alone in discriminating the presence of vertebral fractures, suggesting the potential of a semi-automated pipeline for the opportunistic screening of individuals with a high risk of fracture. Kong et al. [13] developed an ML model to detect facial features from photos of patients with acromegaly, and their model may have the potential to help the detection of acromegaly at an earlier stage.
Facilitating the diagnostic workflow
Tackling the gray area of diagnostic uncertainty with new modalities has always been an important task for clinicians. Asymptomatic hyperparathyroidism can be challenging to identify without a high index of suspicion because it involves subtle biochemical changes and its phenotype overlaps with those of primary osteoporosis and other rare mineral disorders, including familial hypocalciuric hypercalcemia [27]. Somnay et al. [25] trained an ML model to identify patients with primary hyperparathyroidism among patients who underwent neck surgery, including thyroidectomy or parathyroidectomy, although relatively low performance was shown for mild disease. Several studies have shown that ML could support the decision process of whether to perform an invasive biopsy on a thyroid nodule based on ultrasonography, with good classification performance similar to that of radiology experts; therefore, ML classifications might potentially provide guidance to operators during data acquisition and measurement [1428]. A well-validated, accurate, non-invasive ML model may have the potential to replace standard invasive diagnostic modalities for certain diseases. For instance, the global burden of nonalcoholic fatty liver disease (NAFLD) is rapidly growing, but invasive liver biopsy remains the gold standard for diagnosing NAFLD and nonalcoholic steatohepatitis. Perakakis et al. [15] developed a support vector machine-based model to classify NAFLD based on features obtained from the lipidomic, glycomic, and liver fatty acid analysis of serum samples. For the presence of liver fibrosis, a parsimonious exploratory model with 10 lipid species showed high accuracy (up to 98%), suggesting the possibility of a targeted lipidomic approach as an alternative non-invasive diagnostic tool, although the model needs to be further validated in other ethnicities and individuals with a milder spectrum of liver diseases [29].
Finding novel disease clusters and associations
Although unsupervised learning has been utilized less often than supervised learning for diagnosis and screening, it may be helpful to find novel clusters and associations within a given dataset. Kruse et al. [16] applied unsupervised hierarchical agglomerative clustering to find groups with high and low risks of fracture in women from a national Danish patient database based on BMD, medication reimbursement, anthropometric characteristics, and comorbidities. Among the nine clusters that were identified, four clusters classified as corresponding to a high risk of fracture showed heterogeneous compliance to antiresorptive treatments, even with a similar distribution of BMD. The age of 60 years was the earliest time point that allowed a clear discrimination between high and average fracture risk. Altogether, that study provided novel insights regarding characteristics related to compliance with bone medications and the optimal age to recommend dual-energy X-ray absorptiometry screening.
Risk prediction
Clinical outcomes
Accurately predicting clinical outcomes enables an individualized approach to treatment strategy and monitoring. The Weight, Age, hyperTension, Creatinine, High-density lipoprotein cholesterol, Diabetes control, and Myocardial infarction (WATCH-DM) score was developed to predict heart failure risk among patients with type 2 diabetes using ML algorithms based on the Action to Control Cardiovascular Risk in Diabetes (ACCORD) trial dataset, and showed good predictive performance with an external validation set (the Antihypertensive and Lipid-Lowering Treatment to Prevent Heart Attack Trial [ALLHAT]) [17]. Su et al. [18] found that a simple model including only age and BMD selected by classification and regression tree analysis performed similarly to Fracture Risk Assessment Tool (FRAX) categories as a reference tool for predicting incident hip fracture in a large cohort of community-dwelling older men.
Treatment responses
ML principles can be used to find specific subgroups with a heterogeneous response to treatment. Basu et al. [19] re-analyzed the ACCORD trial data to find subgroups with different treatment effects in response to intensive glucose control compared to standard therapy. Although intensive glucose control was associated with increased mortality in the ACCORD trial published in 2008, their post hoc analysis identified that a subgroup of patients experienced a survival benefit from intensive treatment, and the proportion of patients in the subgroup that made the main contribution to increased mortality in the trial was relatively small. This study provides an example of the utility of ML in dissecting treatment responses, with the potential for a more tailored approach both for interpreting results from previous trials and for applying therapeutic strategies according to individual status. For the prediction of treatment response in patients with acromegaly, anthropometric and biochemical data with imaging features were combined in an ML model that achieved better prognostication than the reference prediction tool [20]. Good ML models may have the potential to provide guidance for dose adjustment, particularly in patients with chronic conditions requiring the indefinite replacement of certain hormones, as in patients who receive thyroid hormone replacement after total thyroidectomy or in type 1 diabetes patients who receive insulin replacement. Zaborek et al. [21] built a supervised ML model to guide levothyroxine dose adjustment, which showed a fair improvement of predictive accuracy compared to the current standard of weight-based dosing. A reinforcement training algorithm has been applied to guide the optimal dosing of long-acting insulin in patients with type 1 diabetes [5]. Although the results are preliminary, these studies illustrate the ongoing efforts made by endocrinology researchers to improve patient care by achieving better predictions of the disease course and response to treatment.
Translational research
ML algorithms have become a crucial methodology in translational research with the rise of the multi-omics approach, which produces abundant datasets with numerous features to be accounted for. Liu et al. [22] used an ML algorithm to find key microbiota species and metabolites highly related to exercise responsiveness in humans. Human exercise responders and non-responders had different patterns of exercise-induced alterations in the gut microbiota, and fecal microbial transplantation from responders to mice conferred the benefits of exercise on insulin sensitivity. A random forest algorithm was used to select 19 features (14 species and 15 metabolites) showing a major difference between the exercise-responsive and nonresponsive groups among thousands of microbiota species and metabolites, and these features have the potential to be utilized as biomarkers for personalized responses to exercise. Another study aimed to discover proteomics-based biomarkers for 11 health outcomes, including percentage body fat, lean mass, current smoking, and risk of incident cardiovascular outcomes [23]. By combining large, well-established, community-based cohort databases and samples, the authors took a comprehensive approach to find highly predictive proteins and related models using elegant ML-based techniques, although the actual applicability of these findings needs to be validated in long-term studies in different populations. Unsupervised learning was also applied to find significant associations and interactions among multimodal datasets, providing novel insights for potential metabolite biomarkers of diabetes and sarcopenia [6].
CONCLUSIONS
High-quality ML-based endocrinology research, like research in other medical fields, requires a clear, testable hypothesis based on unmet clinical needs, combined with access to a dataset that provides sufficient information to solve the problem. As Kim et al. [30] clearly addressed in a previous issue of this journal, the ability to access a large volume of medical data itself does not necessarily enable (or mandate) an ML-based approach due to the inherently unrefined, heterogeneous nature of most current medical datasets. Well-designed, timely study designs based on clinical expertise, an emphasis on using a standardized approach to control data quality (beyond a focus on data quantity alone and methodological complexity), collaboration and open communication between clinical domain experts and ML engineers, developing interpretable ML models in contrast to the black-box nature of some algorithms, and creating a supportive environment with input from government, profit or non-profit sectors, study participants, and patients are the core prerequisites for the promising changes that are expected in clinical practice in the field of endocrinology and metabolism through the convergence of artificial and human intelligence [31]. The role of endocrinologists as domain experts will remain crucial for achieving these prerequisites by examining the true clinical impact of flourishing ML-based research products in prospective studies and by ensuring the scientific rigor needed to the benefits of this convergence for patients who suffer from endocrine diseases.


 XML Download
XML Download