

 PDF
PDF ePub
ePub Citation
Citation Print
Print



INTRODUCTION
Hanja (the traditionally used logographic Korean character) and Hangul (the more recent phonological Korean character) are the two basic scripts that have been used in Korea for the last five hundred yr. Hanja has complex and irregular nature in writing, spelling and pronunciation, but each character or word that is made by one or more characters has strong and clear morphemic information. Hangul, on the other hand, has regular and logical composition in writing, therefore, clear spelling and pronunciation, but, without strong morphemic information (1). Apart from these linguistic property, Hanja and Hangul have different semantic divergence. Therefore, a morpheme written in Hangul alone could represent several different meanings, i.e., morphemically different context, that is Hangul has low morphemic clarity (LMC). Whereas, in most cases, each Hanja has unique meaning, that is it has high morphemic clarity (HMC). In short, the Hangul script has significantly more homonym than Hanja. For instance, "beautiful jade" written in Hangul could be "미옥; Mee-Ok" have several different meanings. On the other hand, its Hanja homologue, "美玉; Mee-Ok" has, in most cases, unique meaning. In case of Hangul, because the first character "미" (mi) could be multiples of morphemes, for example, "美" (mi, "beautiful"), "米" (mi, "rice"), and "微" (mi, "small"). A similar argument can be applied for the second constituent "옥." (2). In addition to morphemic clarity, semantic transparency is the second significant characteristic in the language processing of the word, whether the word is in Hanja or Hangul. In Hanja words, which make up over 70% of the entire Korean vocabulary, are predominantly compound words composed of two or more constituent morphemes, however, both have variable semantic transparency. If the compound word has high semantic transparency (HT), the meaning of the compound word can be better understood and comprehended (3, 4, 5, 6).
Based on these linguistic differences between Hanja and Hangul, we have attempted to localize the brain regions that are differentially activated according to the logogram and phonogram and evaluated the effect of semantic transparency and the morphemic clarity on the Hanja and Hangul with respect to recognition memory. It is interesting to note that, in respect to language system, Korean language has unique and interesting properties which could provide an excellent opportunity for understanding neural involvement of language processing.
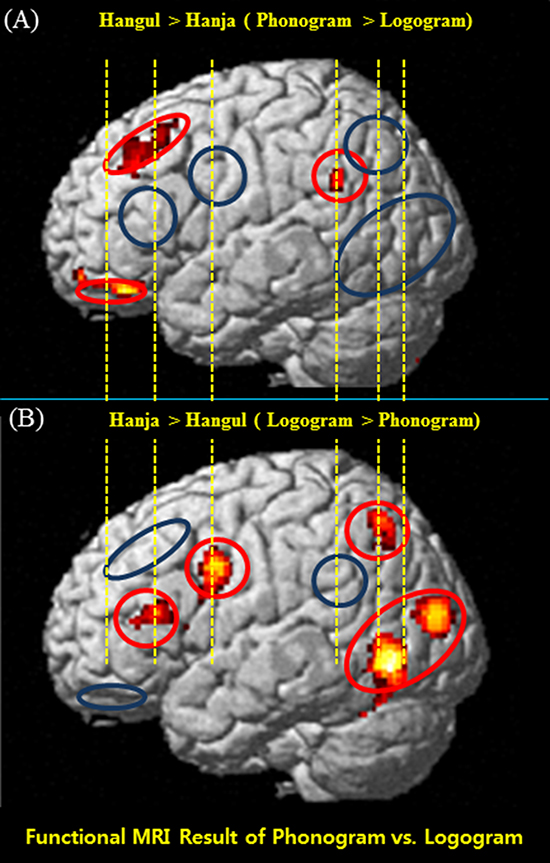
To build a possible neural supporting bases of present study, we have illustrated a conceptual and hypothetical functional diagram of the brain (2, 7, 8, 9) in Fig. 1. When a script is seen by the eyes it activates the primary visual cortex (V1; Brodmann's area [BA]17). This information appears to be forwarded to the extrastriate cortex (ESC; BA18, BA19, and BA37) where the image data is analyzed and processed (10). For example, Hangul letters (grapheme) are forwarded to the angular gyrus (AG; BA39) where they are likely to be converted to sound language (phoneme) (7, 11), then to the Wernicke's area (WA; BA22) where they are again converted into language to be understood and possibly stored (12). Consequently, the information is forwarded to the Broca's area (BA44 and 45). Contrary to the phonological characters, the logographic characters like Hanja are sent to the forebrain area via the left superior parietal cortex (LSPC; BA7), then to Broca's area (BA45) where the input is translated or transformed and forwarded to motor related speech areas, Broca's area (BA44 or 45), for speech preparation and then to the premotor areas (BA 4 or 6) for the induction of mouth movement to allow for word production (13). This dual-route hypothesis appears to be the interesting neural circuitry for the explanation of language processing, and can be adopted, especially, for the Hangul and Hanja study in brain (1). Another major pathway, still very little known, is the ventral pathway shown in the lower part of Fig. 1. The ventral pathway consists of the inferior temporal cortex (BA37, 20, and 21), including the fusiform gyrus which will project to the hippocampus via the inferior longitudinal fasciculus (ILF) and inferior fronto-occipital fasciculus (IFO). Functionally, this pathway is a perception channel which could be involved in appreciation and memory rather than an action discussed above (10, 14) (see lower pathway shown with red line in Fig. 1).
MATERIALS AND METHODS
Experiment 1: Comparison of fMRI based cortical activation study of Hangul and Hanja word readings
Subjects
Twelve native Koreans with high competency (HC) in Hanja (mean age=28 yr; 6 males, 6 females; right-handed) participated in the fMRI study. Written consent was obtained from all participants and the protocol was approved by the institutional review board (IRB) of the Gachon Medical Center. The inclusion criteria for HC was Hanja certification above grade 2 tested by the Korean Association for the Promotion of Hanja Education (KAPHE) and writing or reading Hanja for a minimum of 2 yr in daily life.
fMRI paradigm
A total of 150 of two-letter Hanja stimuli based on KAPHE guidelines equivalent to level 5 middle school education in Korea was used. A total of 150 of the two-letter words most frequently used Hangul script items was also chosen to match the Hanja items. The experiment was conducted using fMRI consisting of a beam projector with an 8-inch screen presented via Stream DX. Among the 150 items, 30 words were used for each block for both, Hanja and Hangul. One session consisted of 5 blocks. Each session began with the display of 30 sec of baseline stimulation which consisted of a fixed cross at the center, followed by a 30 sec period of activation of each block consisting of either Hanja or Hangul. Participants were instructed to read Hanja or Hangul to themselves without actual vocalization (internal reading). Within each activation block, 30 words were displayed with each word being presented for 1 sec. The order of sessions was randomized to eliminate systemic bias (Fig. 2).
fMRI procedure and image data analysis
A 3T whole body Siemens scanner was used for image acquisition with an interleaved T2*-weighted echo-planar imaging (EPI) gradient echo sequence (TR/TE/α=3,000 ms/28 ms/90°, slice thickness=3 mm, in-plane resolution=3×3 mm, 39 slices, field of view [FOV]=192 mm, and matrix size=64×64). Ninety images were acquired in each session (e.g., 30 sec Hanja, 30 sec baseline, and 30 sec Hangul). Two sessions were completed for each participant. Each subject's anatomical image was also acquired using a high resolution (1×1×1 mm), T1 weighted, and 3D gradient echo pulse sequence with magnetization prepared rapid gradient echo (MPRAGE; TR/TE/TI=1,770/2.93/900 ms). The total duration of the experiment for each subject was approximately 30 min. Data was then analyzed using statistical parametric mapping (SPM8; Wellcome Department of Cognitive Neurology, London, UK) running under the Matlab 2008a (MathWorks, Sherbon, MA, USA). Functional volumes were realigned, co-registered to anatomical images, and normalized to the Montreal Neurological Institute (MNI) template using a transformation matrix acquired from the T1 anatomical image normalization based on the SPM T1 template. Finally, spatial smoothing was performed with an 8 mm full width at half maximum (FWHM) Gaussian kernel. The resulting time series was filtered with a cut off time window of 128 sec to remove low frequency drifts in the blood-oxygen level dependent (BOLD) signal. In the first level of analysis, the parameters of Hanja and Hangul word reading were obtained by contrasting each task with the baseline stimulation. With the parameter acquired in the first level of analysis, two and one sample t-tests were performed in the second level of analysis. The significance level threshold was set at P<0.001 or 0.005 (uncorrected) according to the contrast with cluster size (KE) larger than 50 voxels. The locations of peak t-values were reported using automated anatomical labeling (AAL) anatomy (SPM toolbox).
Experiment 2: Study of Morphemic Clarity and Semantic Transparency of Hangul and Hanja Names on Recognition Memory
Subjects
Twelve native Koreans with HC in Hanja (mean age=27 yr; n=7 males; n=5 females; right-handed) participated in the fMRI study. The inclusion criteria for HC were those with Hanja certification above grade 2 as tested by KAPHE, and writing or reading Hanja for a minimum of 2 yr in daily life.
Task and fMRI paradigm
Forty Hanja and Hangul names that are popular in Korea were selected from the database of KAPHE. We considered the name of a person as a non-word stimulus, which allowed us to control each participant's prior experience with the stimuli, thereby minimizing potential differences in word similarity (e.g., word frequency) and pre-existing semantic associations (15). According to their morphemic clarity and semantic transparency, 4 types of stimuli (High transparent - High morphemic clarity (HT-HMC; e.g., 美玉), Low transparent - Low morphemic clarity (LT-HMC; e.g., 貞玉), High transparent - Low morphemic clarity (HT-LMC; e.g., 현자), and Low transparent - Low morphemic clarity (LT-LMC; e.g., 동은) were presented during the fMRI experiment (Table 1). The experiment was conducted in an fMRI setting which consisted of a beam projector with an 8-inch screen presented via Stream DX. One session consisted of 20 blocks (5 sets), each of block was comprised of three phases (Fig. 3): reading (2 sec), rehearsal (4 sec) and button response (2 sec). During the reading phase, subjects read 80 names (40 Hanja names and 40 Hangul names) in random order. During the rehearsal phase, subjects were asked to think of the meaning of the presented name. During the button press phase, if the meaning of the name was transparent, they were asked to press the right button with their thumb; if the meaning of the name was not transparent, they pressed the left button with their thumb (Fig. 3). Subjects were not informed that the experiment was a recognition memory test. In each session, 204 image volumes were acquired. Four sessions were completed for each participant (approximately 24 min). After the fMRI was completed, subjects were offered a brief rest and simple math questions. This was followed by the presentation of Hanja and Hangul names on two pages on a computer screen, including the 40 original words displayed during the fMRI experiment and 80 similar distracters at three group intervals (1, 10, and 120 min). Subjects were asked to check all the words they had seen during the fMRI experiment. No time limit was imposed for this task (Behavioral study).
Statistical analysis for behavioral data
We used the time series hit rate and false alarm rate as an outcome variable. Response frequencies below 5 for each category (e.g., HT-HMC, LT-HMC, HT-LMC, and LT-LMC) were omitted for each subject in order to avoid statistical confound. A one-way repeated measures analysis of variance (RMANOVA) was performed to test whether there were significant differences between-subject's differences (morphemic clarity and semantic transparency), within-subject's differences (replicate measures) and interaction effects. The Greenhouse-Geisser method was applied to correct for the violation of sphericity of covariance. P value of 0.05 was considered statistically significant.
fMRI procedure and image data analysis
A 3T whole-body Siemens scanner with EPI was performed for image acquisition with an interleaved T2*-weighted EPI gradient echo sequence (TR/TE/α=2,000 ms/28 ms/90°, slice thickness=3 mm, in-plane resolution=3×3 mm, 39 slices, FOV=192 mm, matrix size=64×64). Each subject's anatomical image was also acquired using a high-resolution (1×1×1 mm), T1-weighted, and 3D gradient-echo pulse sequence (MPRAGE; TR/TE/TI=1,770/2.93/900 ms). The total data acquisition time of each experiment was approximately 30 min. Data was then analyzed using SPM8. Functional volume images were realigned, co-registered to anatomical image, and normalized to the MNI template using a transformation matrix acquired from T1 anatomical image normalized based on the SPM T1 template, and spatially smoothed with an 8 mm FWHM Gaussian kernel. The resulting time series was high-pass filtered with a cut off time window of 128 sec to remove low frequency drifts in the BOLD signal and temporally smoothed with hemodynamic response function (HRF). A voxel-based general linear model (GLM) at the single subject level was performed in order to estimate the parameters associated with the conditions of interest (e.g., reading, rehearsal [incidental encoding] and button response) in comparison to the baseline condition, and with six motion parameters as covariates of no interest. For example, one regressor was used to model the reading phase (2 sec), four regressors were used to model the rehearsal (incidental encoding) phase for HMC and LMC (former 2 sec and latter 2 sec for each 4 sec of the rehearsal period) and one regressor was used to model the button response phase (2 sec). A within subject analysis of variance (RMANOVA) in SPM was conducted to compare morphemic clarity among the groups. The significance threshold was set at P<0.05 (uncorrected) with spatial extent larger than 100 voxels. The results were displayed using the Xjview (SPM toolbox). The locations of the peak t-values were reported using AAL anatomy (SPM toolbox).
RESULTS
Experiment 1: Comparison of fMRI based cortical activation of Hanja and Hangul word readings
The comparison of Hanja and Hangul with baseline subtraction (Hanja/Hangul vs. baseline) showed Hanja reading induced much larger activation in Broca's area as well as the premotor-motor area and left superior parietal cortex (BA7) while Hangul elicited greater activation in the angular gyrus (AG) and left inferior prefrontal area (LIPFC) (Fig. 4A, B). In addition, Hanja induced greater activation in LSPC and Broca's area in dorsal pathway as well as ESC in ventral pathway. It is interesting to note that Hangul, phonological channel, also activated dorso-lateral prefrontal cortex (DLPFC) and left orbitofrontal cortex (LOFC) (Fig. 4C, D, Table 2). These data largely support the hypothesis shown in Fig. 1.
Experiment 2: Recognition memory based on semantic transparency and morphemic clarity; Behavioral and fMRI results
In the recognition memory experiments with fMRI, immediately after each fMRI experiment, a recognition memory test was performed. The hit rate of recognition memory was measured with stimulation samples 40 original names and 80 other added names, in groups of after 1 min, 10 min, and 120 min, respectively, after the completion of the fMRI experiment (Fig. 5). For the Hanja, the hit rate were 0.96, 0.88, and 0.79 for HT, and 0.72, 0.69, and 0.64 for LT, respectively. For the Hangul, the hit rates were 0.52, 0.28, and 0.12 for HT, and 0.40, 0.28, and 0.19 for LT at 1 min, 10 min and 120 min, respectively. As shown, the results showed that Hanja (HMC) performed superior short-term (1 min) as well as long-term (120 min) recognition memory. Contrarily, Hangul script (LMC) showed recognition memory performance began to drop sharply starting from 1 min after the fMRI experiment and up to 120 min (Fig. 5). An interesting finding was the interaction effect among the script, the semantic transparency and time for the recognition memory performance (Replication×Character×Transparency, F[2.1, 76.2]=3.67, P<0.028). In case of Hanja script, the name of person having high semantic transparency showed a better recognition memory performance than the name of person having low semantic transparency through from 1 min to 120 min. By comparison, in Hangul script, however, this pattern was no longer held (Fig. 5 and Table 3). In addition, the fMRI cortical activation results showed significantly greater activation in the posterior temporal-occipital cortex (PTC or ESC), LPHG and LSPC for Hanja names than Hangul names during recognition memory encoding test (at the threshold value of P<0.05 uncorrected) with a cluster size of 100 (Fig. 6 and Table 4).
DISCUSSION
In the Experiment 1, in order to see whether different cortical areas are involved in recognizing Hanja and Hangul scripts according to logographic and phonological processes of words, word reading experiments were performed for Hanja and Hangul using fMRI. Our results partially support the dual-route hypothesis by showing that Hanja and Hangul recruit different neural areas that are believed to be related to the logographic and phonological pathways. Transformation of Hangul graphemes into phonemes appears to occur in the AG, while transfer of Hanja graphemes occurs in the area of LSPC or BA7 (Fig. 4C, D) (1, 7, 11, 16, 17, 18, 19, 20, 21, 22) and then to the Broca's area (BA44, 45). In this scheme, the role of the LSPC is still unclear but it is one of the high visual association area believed to be responsible for high level visual information processing (10). The known function of Broca's area is motion preparation for speech or its imitation. In the phonological pathway, greater activation of the AG in Hangul is consistent with the hypothesis that grapheme to phoneme conversion takes place in that area.
In the Experiment 2, in order to determine how the Hanja and Hangul scripts affect the consolidation of recognition memory, specifically as a function of morphemic clarity and semantic transparency, the fMRI experiment was carried out by presenting non-word stimuli (e.g., name of a person) consisting of Hanja or Hangul. Recognition memory performance was measured from 1 min to 120 min after the fMRI experiment consists of 80 blocks of Hanja and Hangul names (Fig. 3). Interestingly, the effect of semantic transparency on recognition memory performance over time was relatively small (Table 3 and Fig. 5). As seen in Fig. 5, Hanja script having high transparency showed slightly better recognition memory performance, which also persisted throughout the test period (1 min to 120 min). Similar trend was found in the Hangul script. What we have learned from this experiment is that the recognition memory is the main factor of the difference between Hanja and Hangul, that is the morphemic clarity affects more than the semantic transparency on recognition memory. In other words, the semantic transparency difference within both Hanja and Hangul is not as important as the morphemic clarity difference between the groups, such as the difference between Hanja 美玉 (Mee-Ok) and Hangul 현자 (Hyeon-Ja) rather than the difference between Hanja 美玉 (Mee-Ok) and Hanja 貞玉 (Jung-Ok).
Based on the fMRI experiment with behavioral result, we concluded that recognition memory for Hanja name is superior to that for Hangul name. From a lexical quality point of view, the high clarity morphemic representation provided by Hanja script has relatively better explicit meaning in mental lexical context in comparison to Hangul script, which often has unclear and unbounded semantic representation. Our fMRI results showed increased BOLD signal in the LPHG for Hanja script (HMC) in comparison to Hangul script (LMC), suggesting that there is an alternative pathway for long-term memory via the ventral pathway or the ventral perception channel. The improvement of recognition memory for Hanja scripts than Hangul script is presumably related to increased brain activity, specifically in the LPHG or the hippocampus proper. Activation of the LPHG supports our hypothesis that there is a ventral stream or pathway that connects the ESC directly to the hippocampus via the ILF or IFO (Fig. 1). Human neuroimaging studies have consistently demonstrated that the hippocampal and entorhinal cortices are involved in the long-term encoding of new information (23, 24, 25, 26, 27, 28). The present results are in agreement with many previous studies which have shown that recognition memory performance accompanied increased BOLD signal in the LPHG. Our experiment was performed only with the people having high Hanja competency. Therefore, it is required to identify whether the same experiment with people having low Hanja competency reproduce same outcome with our experiment.
In summary, our experimental data shows substantially different cortical activations for Hanja compared to Hangul reading. It was also found that the morphemic clarity has significantly more effect than semantic transparency on reading-based recognition memory. Study demonstrated, as shown, that the difference between HT Hanja to LT Hanja ("美玉; Mee-Ok" to "貞玉; Jung-Ok"), the semantic transparency difference, is much less influential than the difference between Hanja and Hangul ("美玉" to "현자"), the morphemic difference indicating that the difference in morphemic clarity is the dominant factor in recognition memory. The later is presumably related to increased brain activity we have observed, specifically the LPHG.
Present study attempted to answer how Hangul and Hanja will affect on the recognition memory which possibly related to the comprehension of the words and sentences, the central theme of the human intelligence or intellectual performances.







 XML Download
XML Download